Предисловие
О книге
Цель данной интернет-книги — обеспечить быстрое погружение в написание бекенд приложений на Rust для уже опытных программистов.
Сначала мы детально познакомимся с самим языком, потом мы рассмотрим стандартную утилиту для управления проектами — Cargo, после чего мы погрузимся в асинхронные возможности Rust, и, под конец, разберёмся как создавать бекенд приложения.
На кого расчитана книга
Данная книга ориентирована на разработчиков, которые уже умеют программировать на других языках, и хотят быстро “вкатиться” в Rust.
Основная целевая аудитория — back-end инженеры, которые пишут на таких языках как Java, C#, Python, Ruby или Go, и недовольны той производительностью или потреблением ресурсов, которые предлагает их язык.
Подразумевается, что читатель уже знаком с такими вещами как:
- целые числа и числа с плавающей запятой
- арифметические и логические операции
- основные конструкции в императивных языках программирования: if, for, switch, функции
- базовые структуры данных: массив, список, хеш-таблица, дерево
- базовые алгоритмы: сортировка, поиска
- организации памяти программы: стек, куча
- основы работы с консолью
- многопоточность и механизмы синхронизации
- HTTP протокол
- реляционные базы данных
- JSON формат
О материале
При написании книги, автор хотел максимально сэкономить время читателя, поэтому главы, где описываются общеизвестные понятия (такие как примитивные типы данных, переменные, условный оператор if и т.д.), намеренно написаны очень коротко и поверхностно. При этом весь специфичный для Rust материал описан подробно.
Книга пытается быть максимально близкой к программисту, поэтому изобилует англицизмами и профессиональным жаргоном.
Установка Rust
Для работы с Rust вам понадобятся как минимум:
- Rust тулчейн (компилятор, система сборки и т.д.) — для компиляции файлов с исходным кодом на Rust в объектные файлы (файлы с машинным кодом)
- Линкер (компоновщик) — для сборки множества объектных файлов в исполняемый файл программы
- Стандартная библиотека C
Необходимость стандартной библиотеки C обусловлена тем, что для операции выделения памяти, а также для некоторых операций копирования, Rust использует Сишные функции.
Сборка прикладной программы на Rust выглядит примерно так:

То есть при сборке финального исполняемого файла из скомпилированных модулей, линкеру должна быть доступна стандартная библиотека C.
Установка Rust тулчейна осуществляется при помощи официальной утилиты rustup, а установка линкера и стандартной библиотеки C варьируется от операционной системы и C++ тулчейна.
В следующих главах мы рассмотрим установку Rust и C++ тулчейна на Windows и Linux.
Установка на Windows
Как мы уже знаем, для разработки на Rust под Windows, кроме Rust тулчейна нам потребуется стандартная библиотека C и линкер. На данный момент, на выбор есть два варианта их установки:
- Установить Microsoft Visual C++, которая помимо всего прочего включает в себя и стандартную библиотеку C, и линкер.
- Установить MinGW — порт GCC под Windows, который в свою очередь содержит стандартную библиотеку C и линкер.
По умолчанию настоятельно рекомендуется использовать вариант с Visual C++.
Rustup
Для всех вариантов установки нам потребуется утилита rustup. Для Window, установщик rustup поставляется в виде исполняемого файла rustup-init.exe, который можно скачать с официального сайта https://rust-lang.org/tools/install/
или по прямой ссылке: https://static.rust-lang.org/rustup/dist/x86_64-pc-windows-gnu/rustup-init.exe
Пока что просто скачаем rustup-init.exe, но запускать его будем после установки C++ тулчейна.
Установка с Microsoft Visual C++
Если у вас еще не установлена Visual Studio.
1) Скачайте инсталлятор Visual Studio с https://visualstudio.microsoft.com/
Нам потребуется бесплатная версия Visual Studio Community.
2) Запустите инсталятор, нажмите “Continue”, после чего вы должны увидеть окно выбора компонентов для установки.
Выберете категорию “Desktop development with C++”, и отметьте только компоненты
- MSVC Build Tools for x64/x86
- Windows 11 SDK
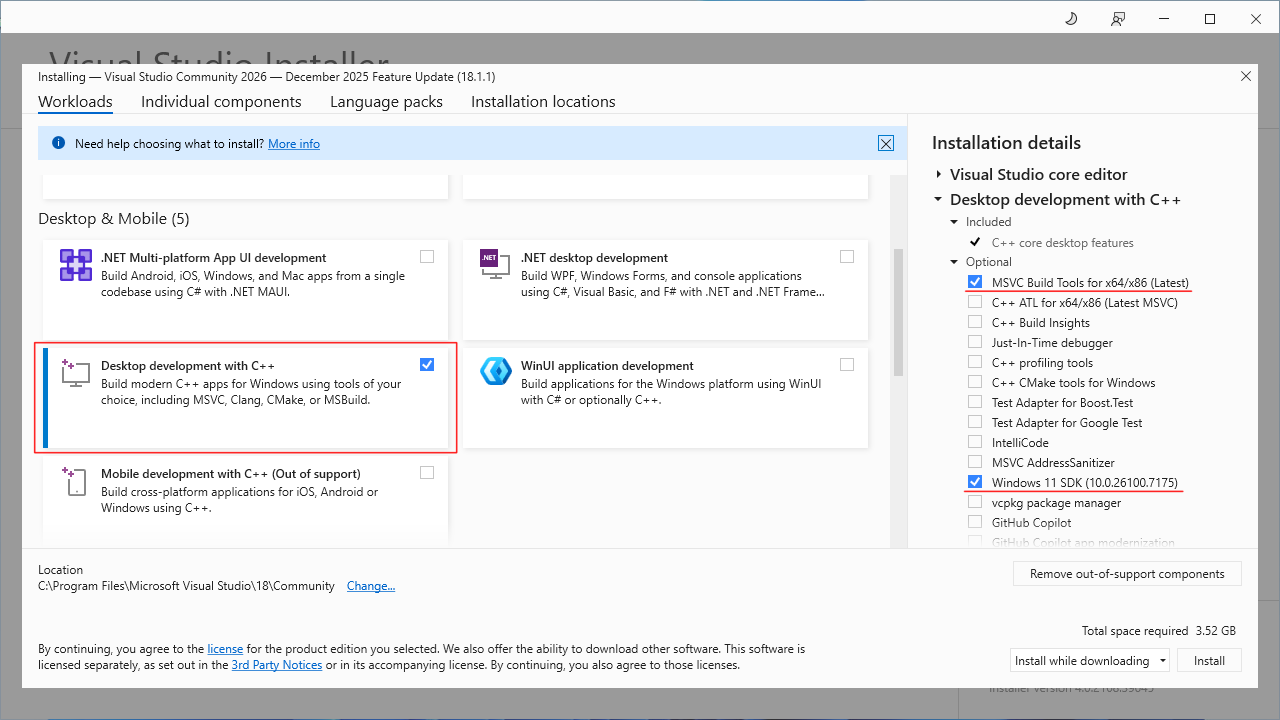
После, нажмите “Install”, и дождитесь завершения установки компонентов. После этого можно закрывать инсталятор.
Если у вас уже установлена Visual Studio, но отсутствуют компоненты MSVC Build Tools for x64/x86 и Windows 11 SDK, то просто запустите setup.exe, который находится в C:\Program Files (x86)\Microsoft Visual Studio\Installer\setup.exe, и доустановите их.
Note
Если вы не будете использовать библиотеки написанные на C/C++ (а в рамках этой книги мы не будем их использовать), то вам хватит только этих двух компонентов. Но в будущем вам могут понадобиться еще:
- C++ CMake tools for Windows — CMake утилита при помощи, которой собирается множество библиотек написанных на C++
- vcpkg package manager — утилита для установки библиотек на C/C++
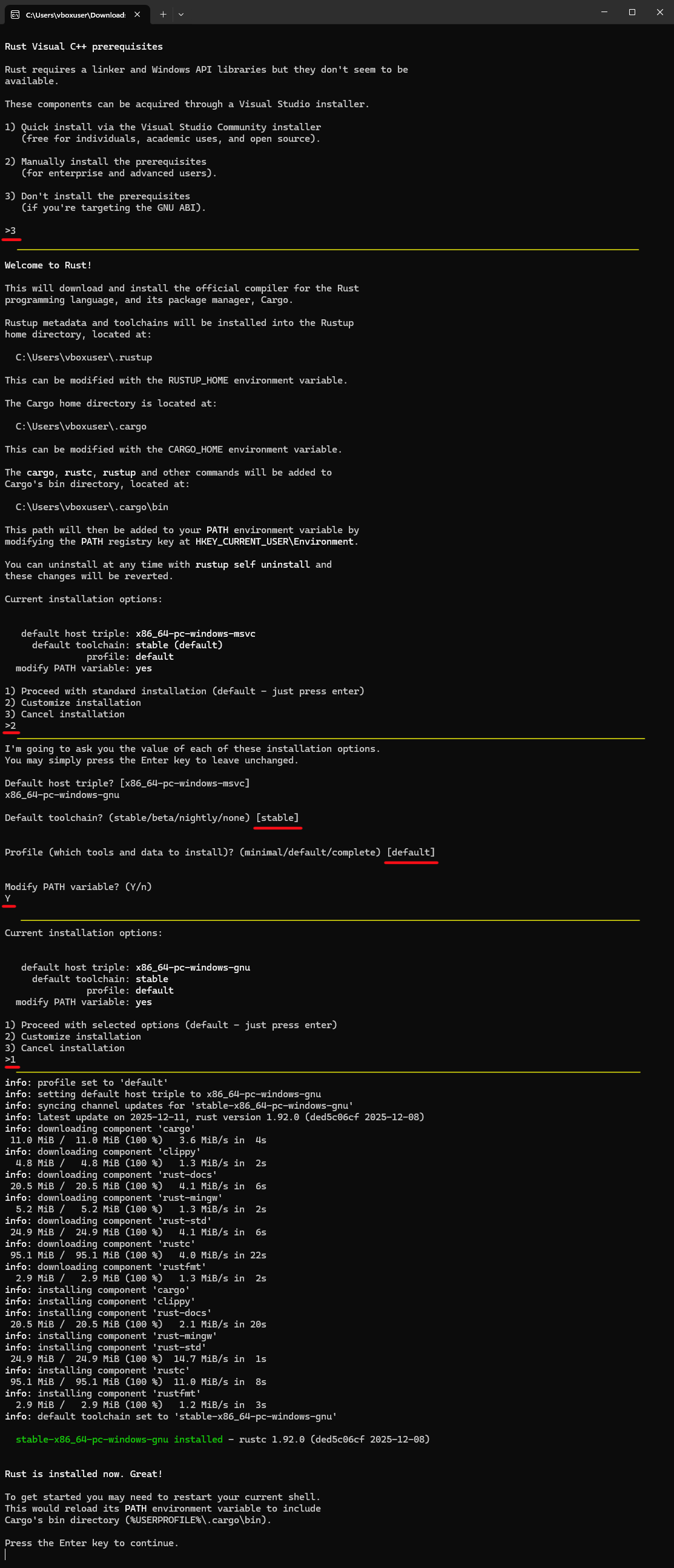
3) Теперь пришла очередь ранее скачанного rustup-init.exe. Запускаем инсталятор. Установщик по умолчанию предложит установить Rust тулчейн под target (целевую платформу) x86_64-pc-windows-msvc. Это как раз и есть сборка под Windows с использованием линкера и стандартной библиотеки от Visual C++. В консоли это должно выглядеть так:
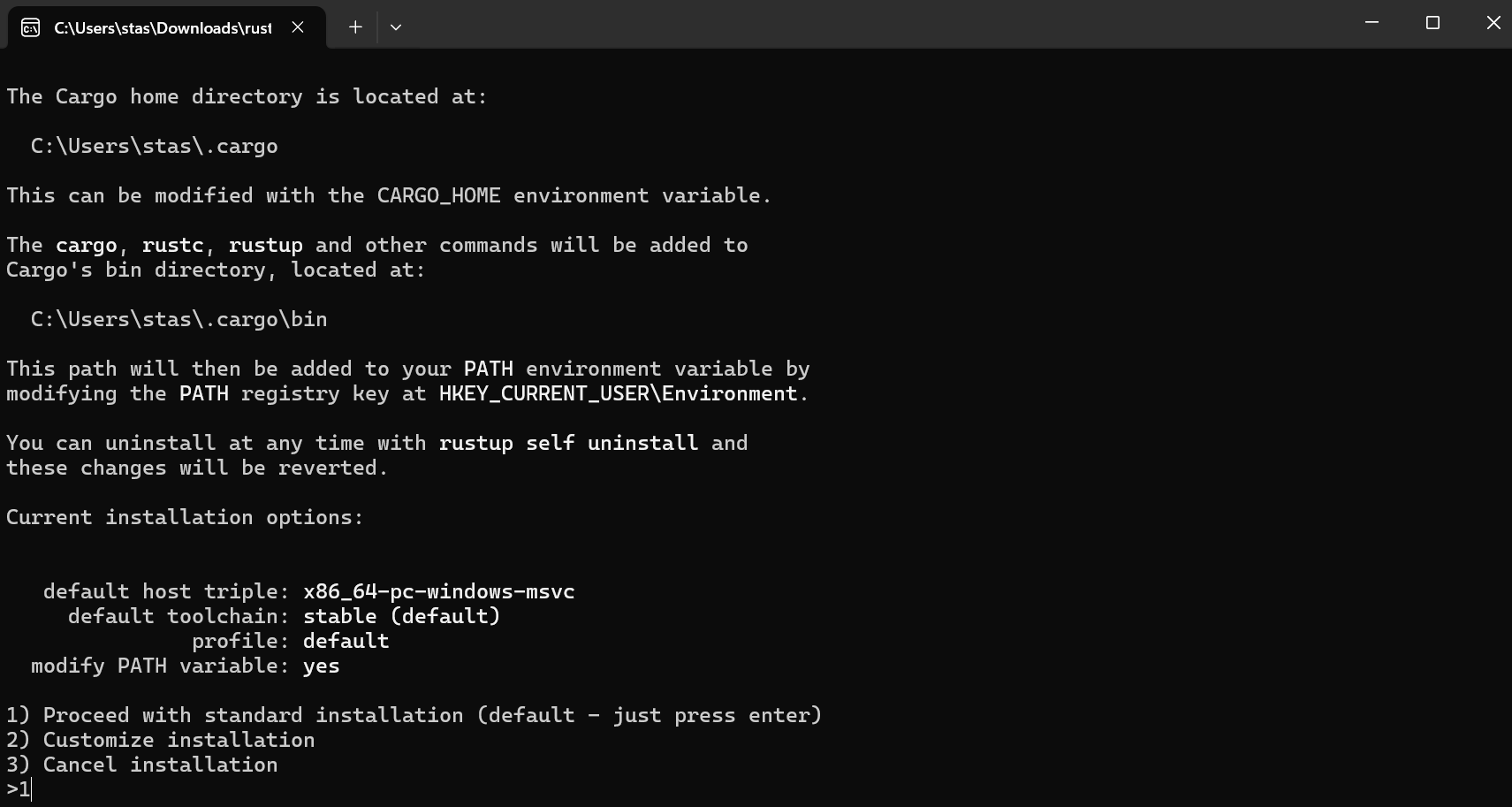
Выбираем 1-й вариант (просто установить тулчейн с настройками по-умолчанию).
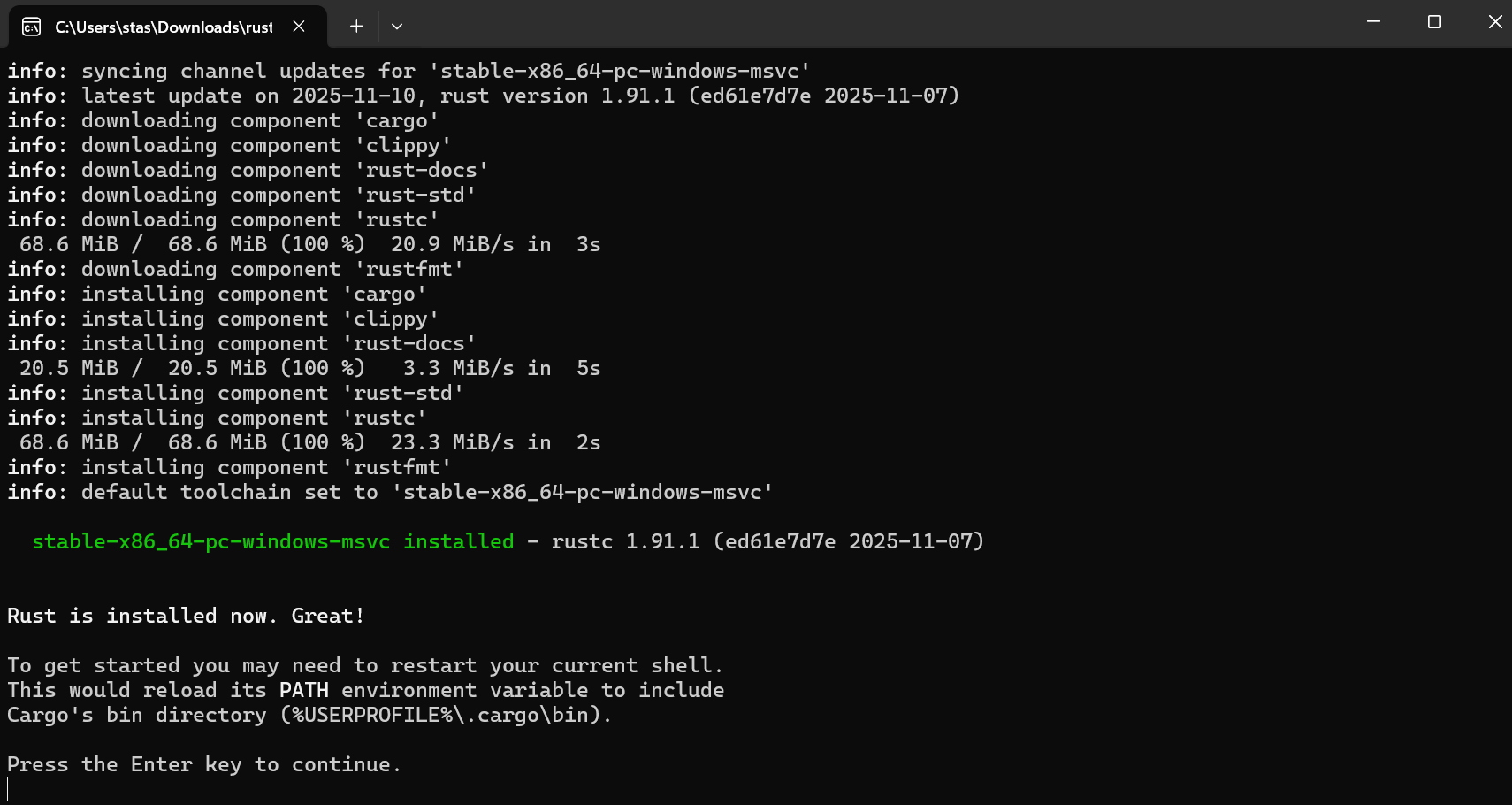
После установки компонентов Rust тулчейна, это окно консоли можно закрывать. Всё что нужно — установлено.
4) Теперь надо проверить, что компоненты установлены корректно.
Откройте консоль (PowerShell или cmd), и выполните следующие команды:
cargo new test_rust— создать новый Rust проект. С утилитой Cargo мы познакомимся потом, а пока что нам достаточно знать, что этой командой мы создадим “болванку” Rust программы, которая просто печатает на консоль строку “Hello, world!”cd test_rust— перейти в свежесозданный каталог test_rustcargo run— скомпилировать и запустить программу
В консоли это должно выглядеть так:
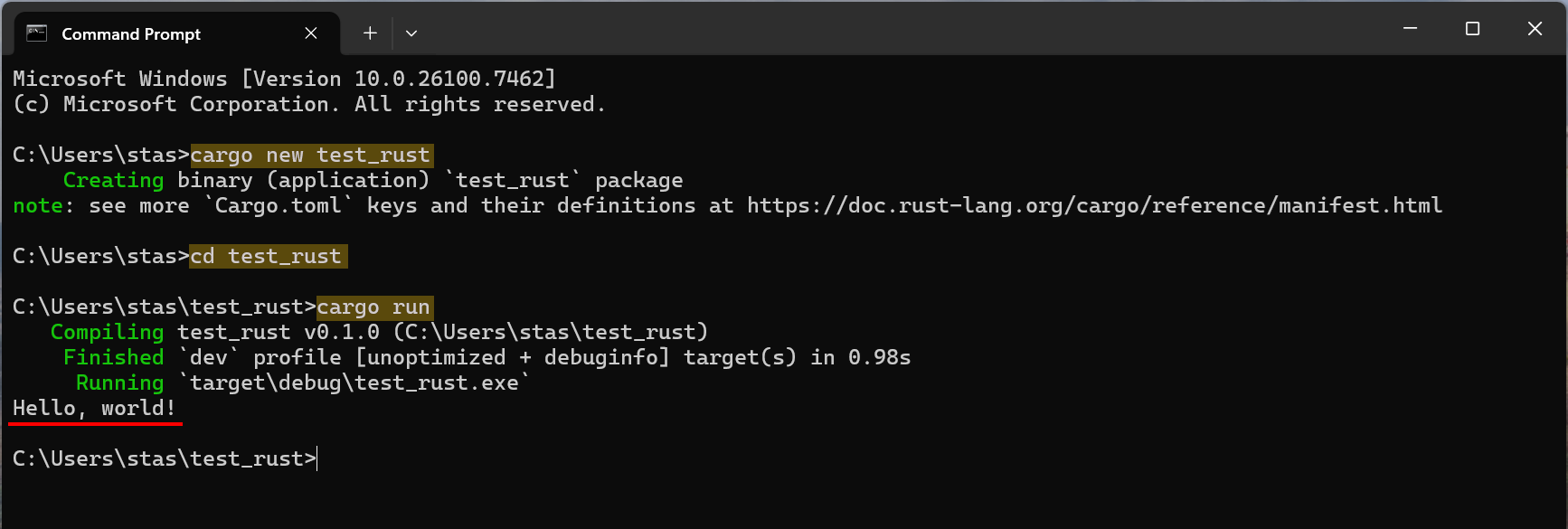
Всё готово.
Установка с MinGW
MinGW — порт компилятора GCC на Windows. Он так же содержит свой линкер и стандартную библиотеку C, поэтому может быть использован для сборки программ на Rust.
Существует несколько способов установки MinGW. Мы рассмотрим два из них:
- MinGW-W64-builds — просто архив с утилитами и библиотеками
- MSYS2 — среда для создания Linux-подобного окружения для разработки под Windows. Предлагает пакетный менеджер для простой установки утилит и библиотек, через который можно установить MinGW.
MinGW w64
Оригинальная сборка MinGW-w64 поставляется просто как архив, который можно скачать с официальной GitHub страницы: https://github.com/niXman/mingw-builds-binaries/releases.
На странице скачивания вы можетей найти несколько вариантов сборки, чьи имена составлены по схеме:
архитектура-версия-relese-АПИ_многопоточности-эксепшены-Си_рантайм-ревизия.7z
Например:
- x86_64-15.2.0-release-mcf-seh-ucrt-rt_v13-rev0.7z
- x86_64-15.2.0-release-posix-seh-msvcrt-rt_v13-rev0.7z
- x86_64-15.2.0-release-posix-seh-ucrt-rt_v13-rev0.7z
- x86_64-15.2.0-release-win32-seh-msvcrt-rt_v13-rev0.7z
- x86_64-15.2.0-release-win32-seh-ucrt-rt_v13-rev0.7z
Вам подойдёт любой вариант, кроме mcf, который не работал с Rust на момент написания этого текста (Rust 1.92). Лично автор предпочитает win32-seh-ucrt-rt вариант.
1) Скачайте 7z архив MinGW, и распакуйте в какую-то папку, например C:\dev\mingw64.
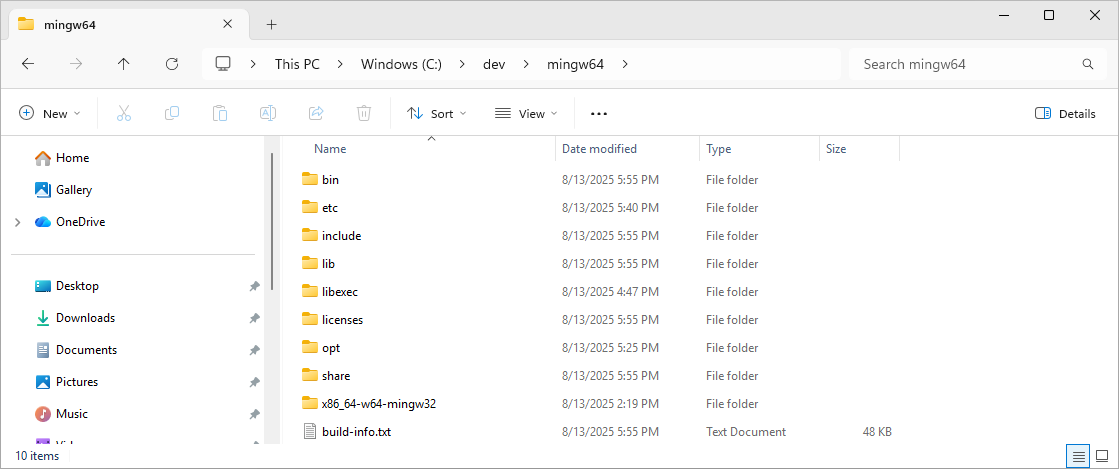
2) Добавте каталог mingw64\bin в системную переменную Path.
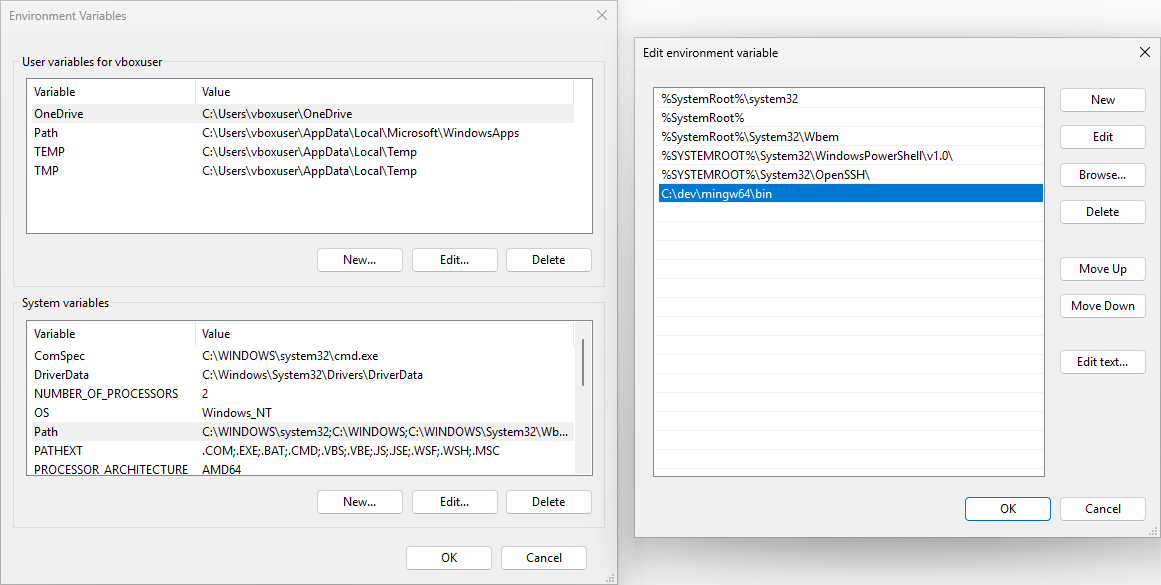
3) Теперь запустите rustup-init.exe.
На первый вопрос, который предлагает автоматическую установку компонентов, выберите пункт (3) — ничего не устанавливать.
Далее Rustup покажет конфигурацию, которую он предложит установить. По умолчанию это будет x86_64-pc-windows-msvc (тулчей и целевая платформа для Visual C++).
Выберити вариант (2) — кастомизировать конфигурацию.
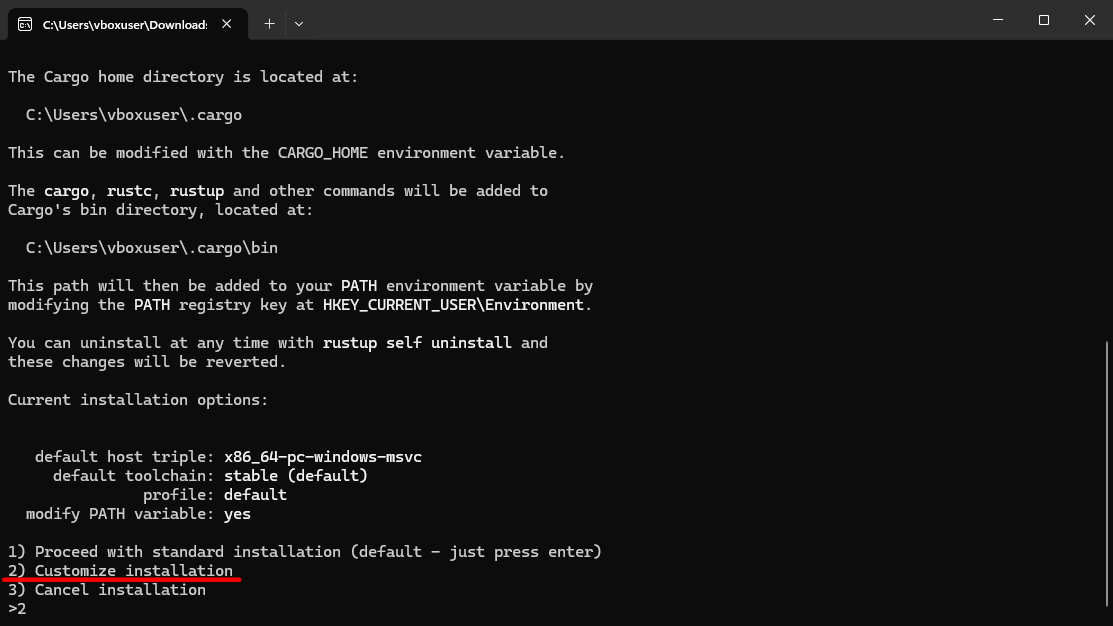
Rustup попросит указать имя Rust тулчейна, который вы хотите установить. Вместо предлагаемого по умолчанию x86_64-pc-windows-msvc, укажите x86_64-pc-windows-gnu.
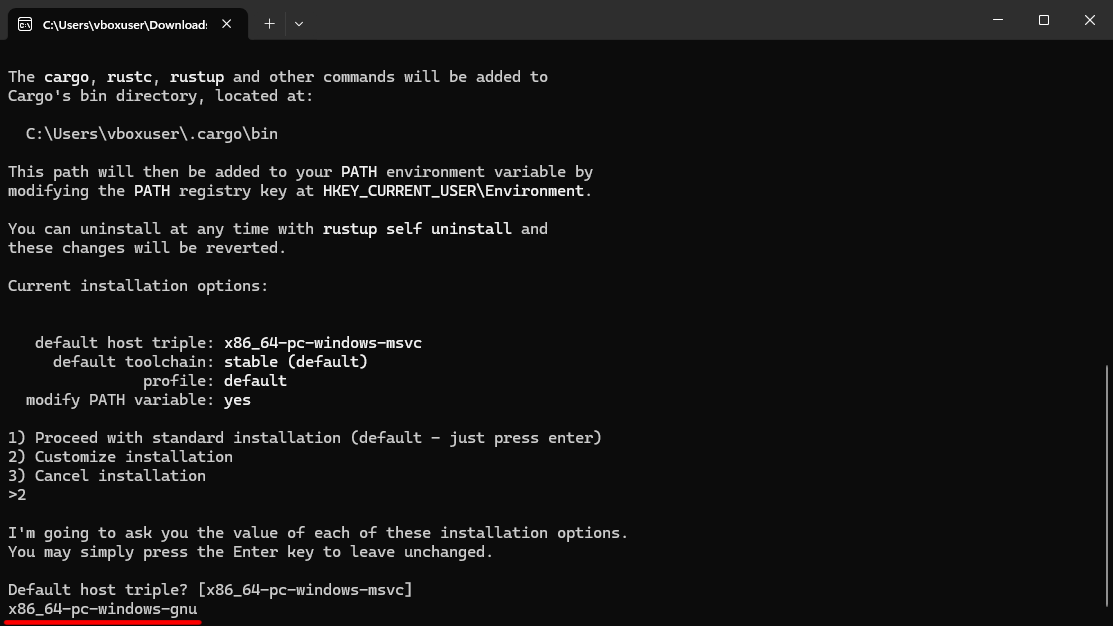
Для остальных параметров подходят значения по умолчанию.
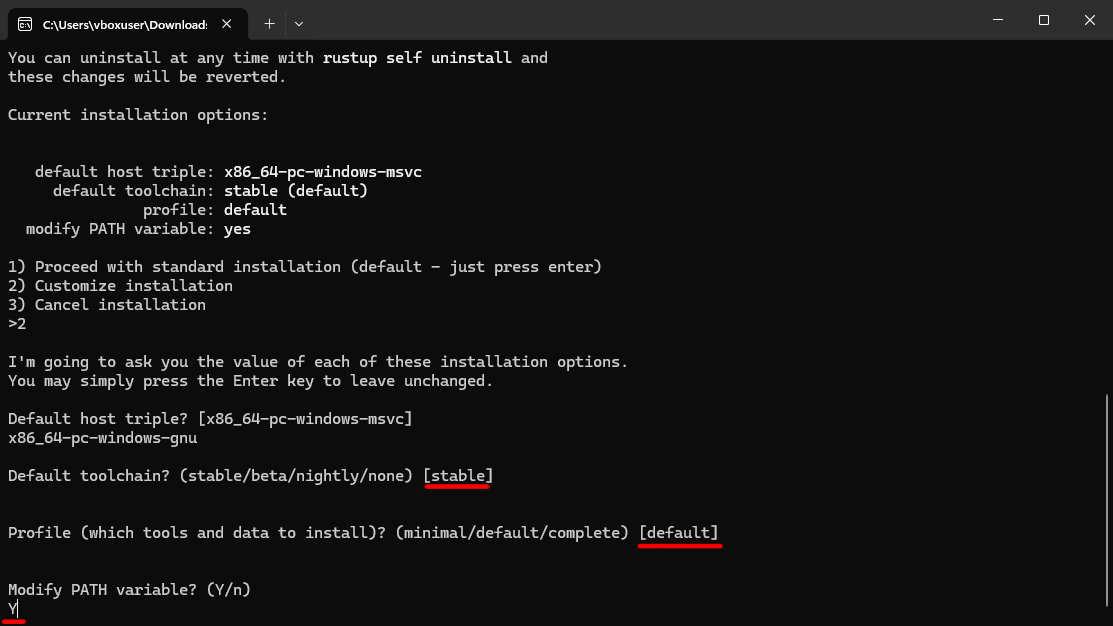
Установка завершена. Теперь протестируем, что мы можем собрать программу на Rust.
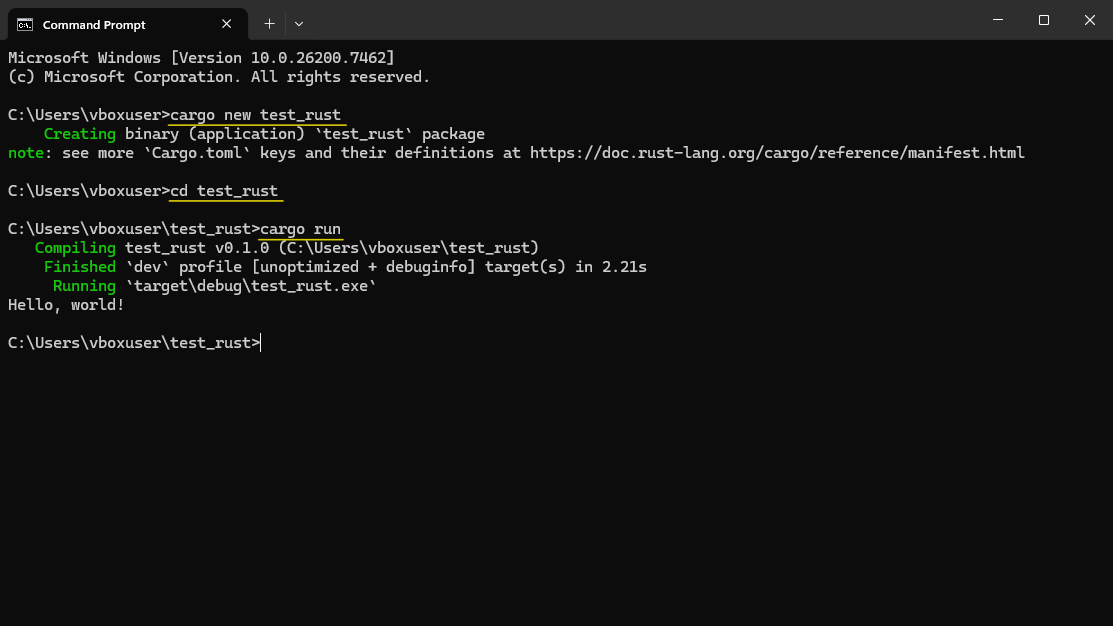
Откройте новую консоль и создайте и запустите Hello World программу, таким же образом, как и в описании установки вместе с Visual C++.
cargo new test_rustcd test_rustcargo run
Результат должен выглядеть так:
MSYS2
Если в предыдущем сценарии с MinGW w64, мы вручную качали дистрибутив MinGW и самостоятельно добавляли его в системные пути, то при использовании MSYS2 всё будет куда более автоматизировано: MSYS2 предоставляет пакетный менеджер pacman, который умеет скачивать и устанавливать программы и библиотеки из удалённого репозитория. С его помощью мы и установим MinGW.
1) Сначала скачайте инсталлятор MSYS2: https://www.msys2.org/#installation
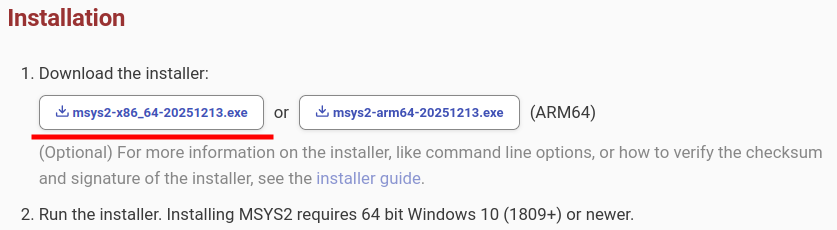
Запустите инсталлятор, и выберите путь по которому будет хранится как сам MSYS2, так и устанавливаемые им программы и библиотеки:
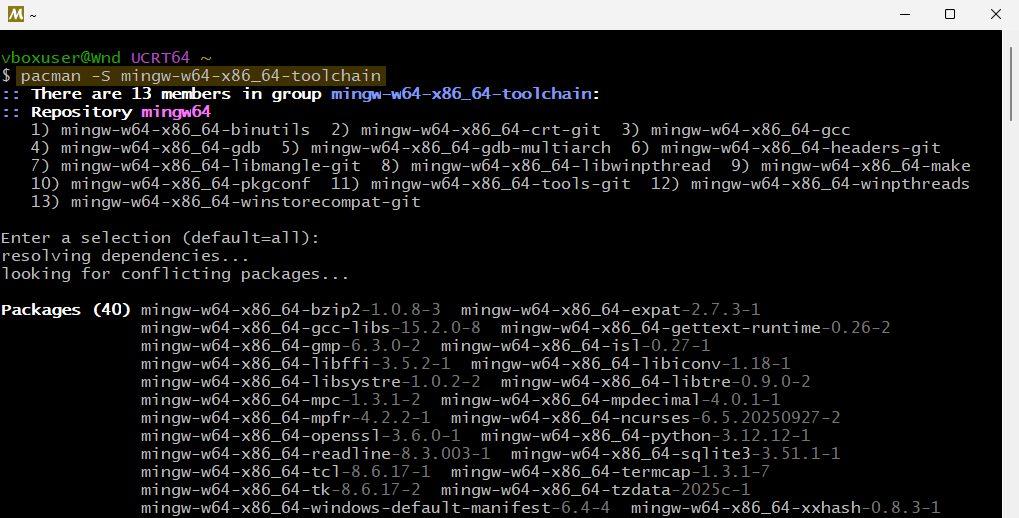
2) После завершения установки, откройте msys2 консоль (должна появится в меню “Пуск”) и установите пакеты mingw и base-develop при помощи команд:
pacman -S mingw-w64-x86_64-toolchain
pacman -S base-devel
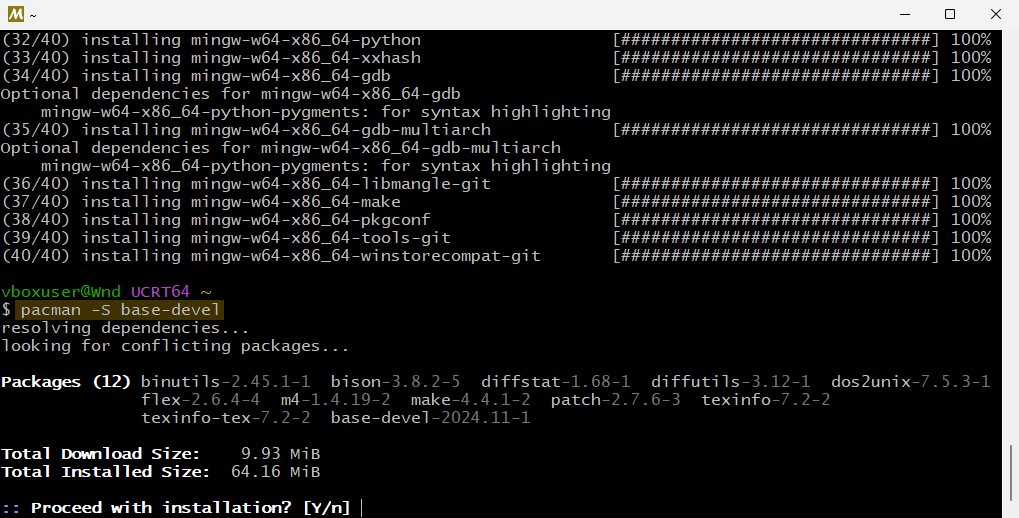
Вот и всё: MinGW установлен и добавлен в системные пути.
Теперь осталось установить Rust тулчейн. Делается это точно таким же образом, как и для ручной установки MinGW w64.
3) Запустите rustup-init.exe.
Далее вместо x86_64-pc-windows-msvc выберите x86_64-pc-windows-gnu и завершите установку.
Установка Rust завершена. Теперь можно приступать к изучению самого языка.
Установка на Linux
Установка на Linux, как и установка на Windows, состоит из двух этапов:
- Установка C++ тулчейна
- Установка Rust тулчейна
Установка С++ тулчейна
В качестве C++ тулчейна мы будем использовать GCC.
В различных Linux дистрибутивах GCC устанавливается по-разному, но, как правило, при помощи пакетного менеджера.
В дистрибутивах Linux с пакетным менеджером apt (Ubuntu, Debian, Linux Mint), GCC устанавливается командой:
sudo apt install gcc
В дистрибутивах с пакетным менеджером yum и/или DNF (CentOS, Fedora, Oracle Linux) используется команда
sudo yum install gcc
или
sudo dnf install gcc
Установка Rust
После того как GCC установлен, мы должны установить утилиту rustup, которая управляет Rust окружением.
Для установки rustup выполните команду:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Эта команда скачает и запустит скрипт rustup.sh, который, в свою очеред, скачает Rust тулчейн и поместит его в каталог ~/.rustup.
Tip
Если с установкой rustup возникли проблемы, то обратитесь к официальному руководству: https://www.rust-lang.org/tools/install
Выполните команду rustc --version, которая печатает версию текущего установленного компилятора Rust. Если всё прошло успешно, то вывод должен быть примерно таким:
$ rustc --version
rustc 1.89.0 (29483883e 2025-08-04)
Среда разработки
Кроме самого Rust тулчейна, вам, очевидно, понадобится редактор кода или среда разработки с поддержкой Rust. Популярные варианты:
- Rust Rover — очень мощная IDE от JetBrains специльно для Rust. Бесплатна для Open-Source разработки и обучения, но для коммерческий разработки придётся купить лицензию.
- VSCode — мощная, бесплатная и очень гибкая среда разработки с открытым исходным кодом.
- Zed — новая, бесплатная и очень быстрая среда разработки, написанная на Rust.
- NeoVim — мощный консольный редактор с высоким порогом входа, но большой гибкостью и расширяемостью. NeoVim — это форк оригинального Vim, в котором для написания плагинов вместо VimScript используется Lua.
- Helix — “клон” Vim, написанный на Rust. Не так гибок, как NeoVim, но дружественнее и проще.
Если вы уже пользуетесь одной из IDE от Jet Brains, при этом вам подходит как она сама, так и её лицензия и стоимость, то можете просто ставить Rust Rover и переходить к следующей главе.
rust-analyzer
Из всех вышеперечисленных сред разработки, только Rust Rover имеет собственную реализацию парсера и анализатора Rust кода. Все остальные работают с Rust кодом посредством rust-analyzer.
rust-analyzer — приложение, которое анализирует код на Rust и предоставляет такие возможности как:
- выведение типов
- автодополнение
- переход к объявлению переменной/функции/типа
- поиск всех использований функции/типа
- и т.д.
Редакторы кода взаимодействуют с rust-analyzer при помощи LSP (Language Server Protocol) — протокола, разработанного специально для взаимодейсвтия между редакторами и анализаторами кода.

Всё это значит, что перед тем как любой из вышеперечисленных редакторов сможет работать с Rust, вам необходимо установить rust-analyzer. Сделать это можно при помощи команды:
rustup component add rust-analyzer
После этого можно приступать к установке и настройке IDE.
VSCode
Если вы не работали со средами разработки от JetBrains или работали, но они вам не подходят, то первое, что рекомендуется попробовать — VSCode.
VSCode представляет из себя редактор кода, который изначально не умеет ничего кроме редактирования, но имеет обширную базу плагинов, способных легко превратить VSCode в мощную IDE.
Для начала скачайте VSCode с официального сайта: https://code.visualstudio.com/download. На сайте имеются варианты скачивания в виде :
- инсталлятора для Windows
- пакетов для Linux
- просто архива
Выбирайте то, что вам удобнее.
После скачивания, запустите VSCode и перейдите в плагины, щёлкнув на иконке как на изображении ниже:
В появившемся контекстном меню выберите пункт “Extension”, после чего перед вами должна открыться следующая панель:
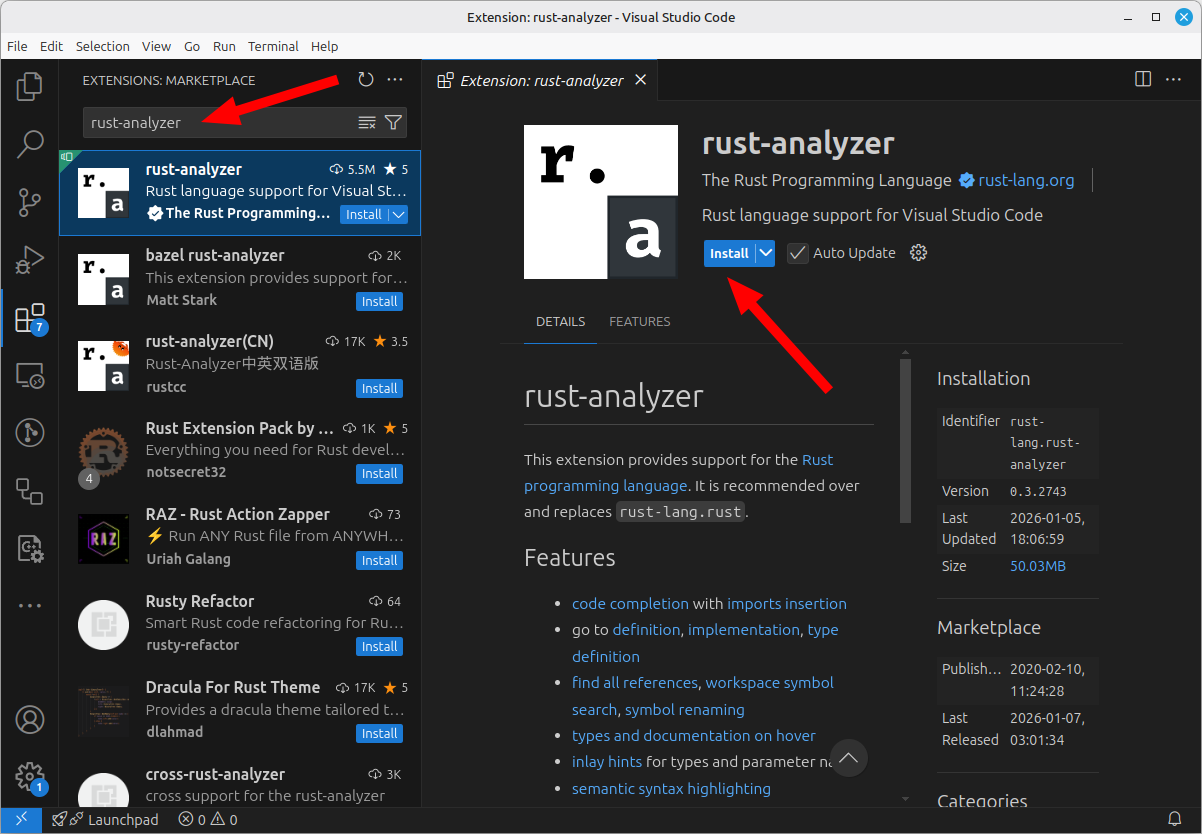
В левом верхнем углу находится поле ввода для поиска расширений. Введите в него “rust-analyzer”, и после того как расширение отобразится, нажмите “install”.
В принципе, этого уже достаточно, чтобы начать работать с Rust. Однако, рекомендуется так же установить следующие расширения:
- Even Better TOML — подсветка синтаксиса для TOML файлов
(ссылка на страницу плагина) - vscode-icons — более интуитивные пиктограммы в дереве файлов
(ссылка на страницу плагина)
После установки выберите в меню:
File -> Preferences -> Theme -> File Icon Theme -> VSCode Icons
Теперь протестируем, что всё работает.
Создайте Rust проект: откройте консоль, перейдите в удобный каталог (командой cd) и выполните следующую команду:
cargo new test_rust_project
Эта команда создаст новую директорию test_rust_project с проектом.
В VSCode выберите в меню “File -> Open Folder” и укажите папку test_rust_project.
После этого должен открыться ваш свежесозданный проект. Слева в дереве файлов щёлкните на src/main.rs, после чего справа в редакторе кода появится содержимое файла.
Над главной функцией (fn main) должна отображаться стрелочка с надписью “Run”.
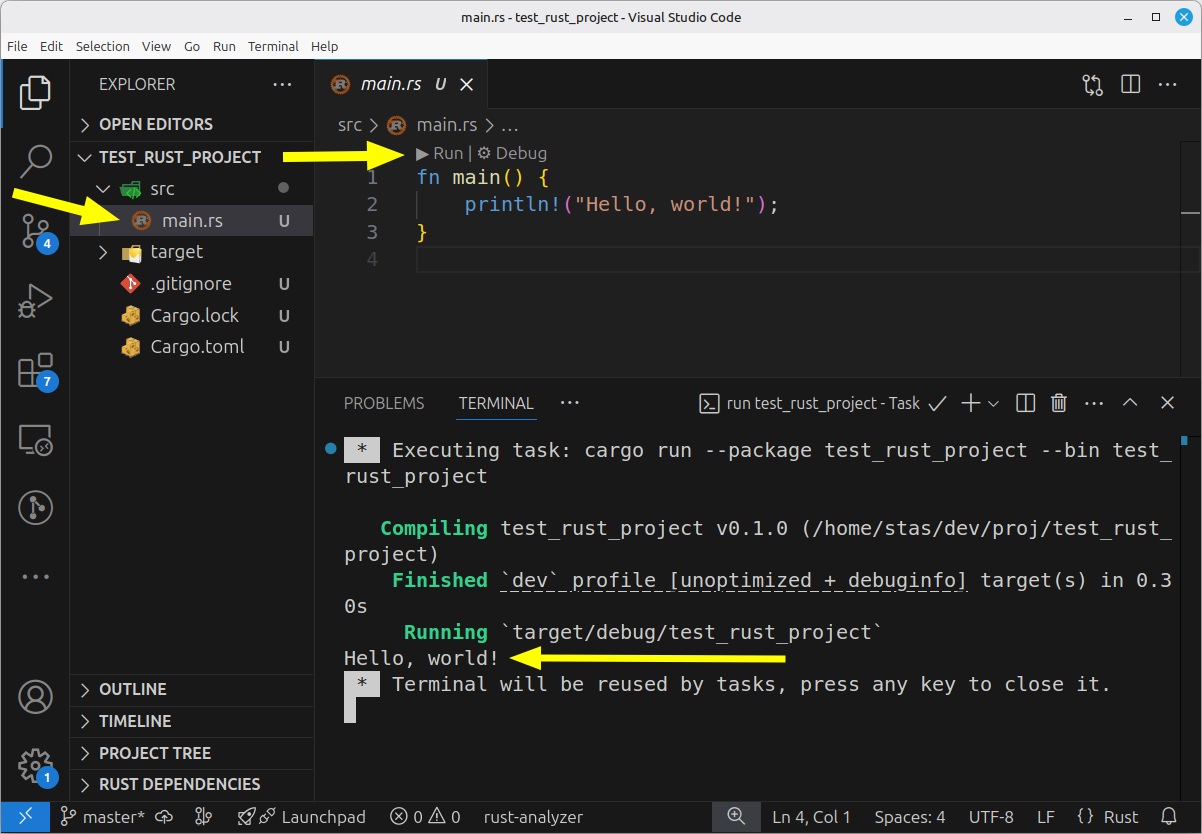
Нажмите на “Run”. Если после этого в нижней части окна появится терминал, в котором отобразится строка “Hello, World!”, то значит всё настроено верно.
Zed
Zed — молодая (первый бета релиз в 2023-м году) среда разработки, написанная на Rust и WGPU (библиотека для кроссплатформенной работы с графикой на GPU).
Основным фокусом Zed является производительность и эффективное использование аппаратных ресурсов. Если вы чувствительны к задержкам в работе графических приложений, то обязательно попробуйте Zed.
Скачать Zed можно с официального сайта: https://zed.dev/download
После запуска Zed выглядит так (разумеется, тёмная тема тоже имеется):
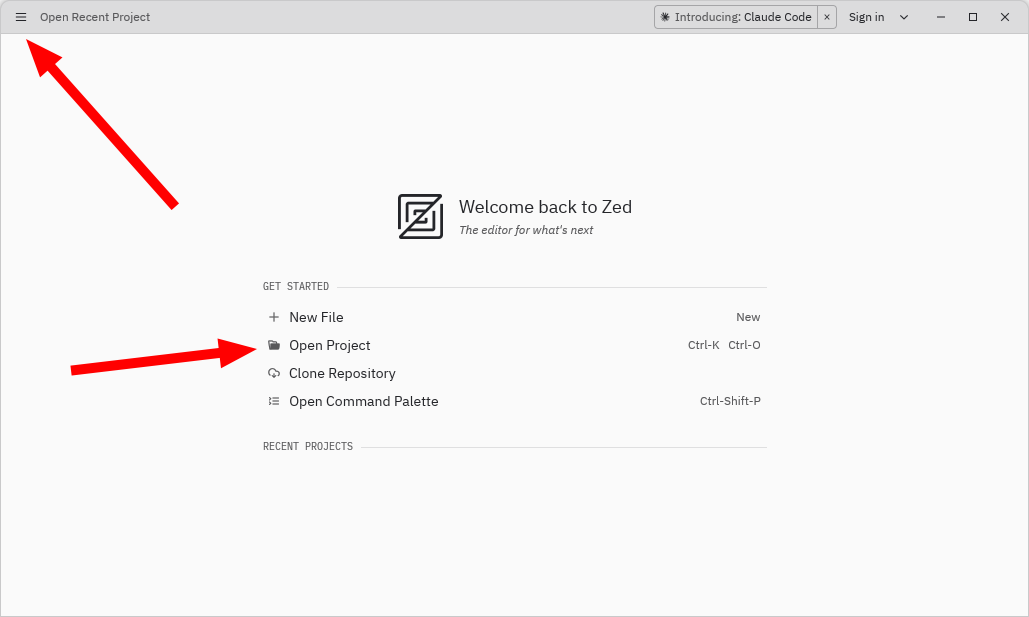
Zed сразу умеет общаться с rust-analyzer, поэтому никаких дополнительных расширений устанавливать не нужно.
Создайте тестовый Rust проект: откройте консоль, перейдите в удобный каталог (командой cd) и выполните следующую команду:
cargo new test_rust_project
Теперь в Zed откройте папку со свежесозданным проектом. Для этого либо на панели в центре выберите “Open Project”, либо кликните на значок ≡, находящийся в левом верхнем углу, и выберите File -> Open Folder.
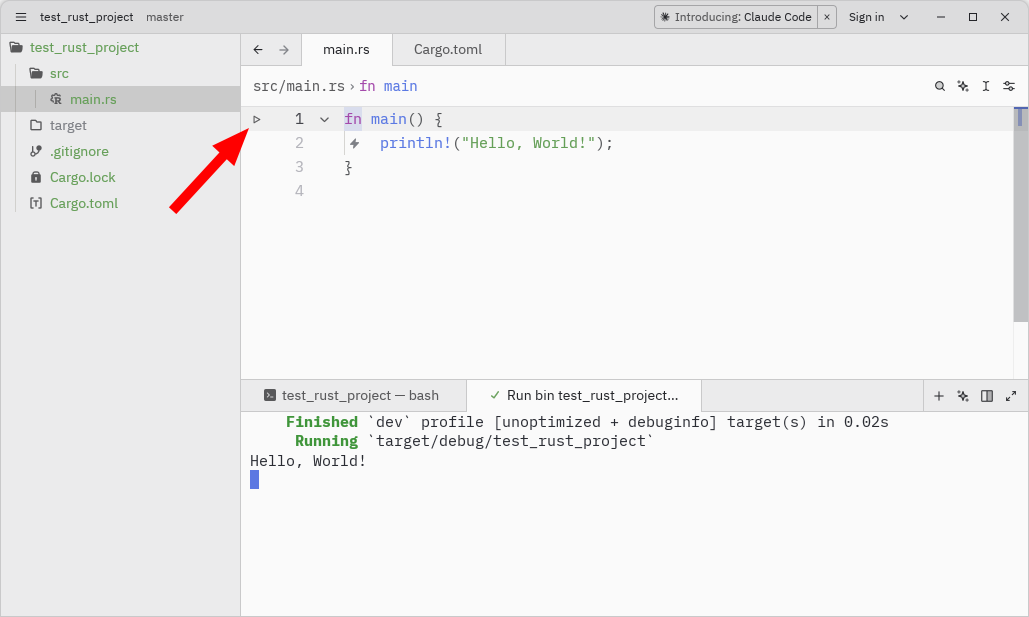
В дереве файлов проекта в левой части окна выберите файл src/main.rs, и в панели справа должно отобразиться содержимое файла.
Слева от функции main должен отображаться знак запуска — ▶. Нажмите на него, и в консоли снизу должен отобразиться вывод программы: Hello, World!
NeoVim
Если вы являетесь пользователем NeoVim, то вы и так уже всё знаете 😉
Если вы хотите попробовать Vim, но вас пугает перспектива его настройки, то попробуйте Helix.
Первый взгляд
Для начала, чтобы заложить фундамент нашего представления о языке, давайте посмотрим, как выглядит “Hello World” на Rust.
// Это комментарий
fn main() {
println!("Hello world!");
}Как видите, Rust — это язык с так называемым Си-подобным синтаксисом: тело функции обрамлено фигурными скобками, а каждое выражение заканчивается точкой с запятой.
Как и во многих Си-подобных языках, функция main — главная функция, с выполнения которой начинается программа.
Давайте скомпилируем эту программу.
1) Сохраните текст программы в файл main.rs в удобную для вас директорию.
2) Откройте консоль и перейдите (командой cd) в директорию, в которой находится файл main.rs
3) Скомпилируйте main.rs при помощи компилятора Rust — rustc:
rustc main.rs
Компилятор должен сгенерировать исполняемый файл: main.exe — на Windows или main — на Linux.
4) Запустите программу
На Linux:
./main
Hello world!
На Windows:
main
Hello world!
Безопасный Rust
Перед тем как мы погрузимся в изучение языковых конструкций, нужно сказать, что в языке Rust есть два подмножества: безопасный Rust и небезопасный.
По умолчанию мы пишем код на безопасном Rust, и компилятор гарантированно защищает нас от таких вещей, как:
- утечки памяти (memory leak)
- порча данных ввиду множественного доступа (concurrent modification errors)
- гонка за данные в многопоточной среде (data race)
- ошибки сегментации / ошибки доступа по нулевому указателю (segmentation error)
- неопределённое поведение (undefined behavior)
За такие гарантии безопасности мы платим определённой долей свободы, а именно в безопасном Rust коде запрещён ряд операций, таких как:
- работа с памятью при помощи указателя
- вызов кода из библиотек, написанных не на Rust
- работа с потенциально несинхронизированными данными
Такие операции относятся к небезопасному подмножеству Rust и могут быть выполнены только внутри специального unsafe блока.
Сразу хочется вас успокоить: при написании back-end приложений (а это основной фокус книги), использовать небезопасный Rust приходится крайне редко. В большинстве приложений можно полностью избежать использования небезопасного Rust.
В процессе изучения мы иногда будем отмечать, что какое-то действие доступно только в небезопасном Rust, и вы сами сможете убедиться, насколько редки эти случаи.
Переменные
Объявление переменной
Синтаксис для объявления переменных в Rust выглядит так:
let имя_переменной: тип = значение;Например:
#![allow(unused)]
fn main() {
let a: i32 = 5;
}Если при объявлении переменной ей сразу присваивается значение, то тип можно опустить, так как компилятор выведет его автоматически:
#![allow(unused)]
fn main() {
let a = 5;
}Также переменную можно сначала объявить, а значение присвоить ниже. При этом явное указание типа переменной так же не обязательно, так как компилятор сможет сопоставить объявление и последующую инициализацию.
#![allow(unused)]
fn main() {
let a;
a = 5;
}Мутабельность
Tip
Мутабельность — англицизм (mutable), который означает “изменяемость”.
По умолчанию переменные в Rust немутабельны, то есть после того, как переменной присвоено значение, другое значение в неё записать компилятор уже не позволит.
Такая программа:
fn main() {
let a = 1;
a = 5;
}вызовет ошибку компиляции:
error[E0384]: cannot assign twice to immutable variable `a`
--> main.rs:3:5
|
2 | let a = 1;
| - first assignment to `a`
3 | a = 5;
| ^^^^^ cannot assign twice to immutable variable
Для того, чтобы сделать переменную мутабельной, её нужно объявить с ключевым словом mut.
#![allow(unused)]
fn main() {
let mut a = 1;
a = 5;
}Именование переменных
Имена переменных могут содержать только буквы (включая допустимые Unicode буквы), цифры и символ подчёркивания. При этом имя переменной не может начинаться с цифры. Ключевые слова Rust не могут быть использованы в качестве имени переменной.
#![allow(unused)]
fn main() {
let a = 1;
let b_x_5 = 2;
let таки_переменная = 3;
let 変数名 = 4;
}В Rust для имен переменных принято использовать так называемую змеиную нотацию (Snake case):
- имена переменных должны начинаться со строчной буквы
- если имя переменной состоит из нескольких слов, то эти слова разделяются символом подчёркивания
Например:
#![allow(unused)]
fn main() {
let number = 1;
let some_number = 2;
let coordinate_2d_x = 2.11;
}В случае необходимости использовать ключевое слово в качестве имени переменной (такое может понадобиться, например, для десериализации поля из бинарного формата), необходимо к имени переменной добавить суффикс r#:
#![allow(unused)]
fn main() {
let r#if = 5;
}Константы
Кроме переменных, в Rust существуют и константы. В то время как переменные хранятся на стеке, константы хранятся, как правило, в сегменте кода.
Синтаксис объявления константы:
#![allow(unused)]
fn main() {
const ИМЯ: Тип = значение;
}В отличие от переменных, для констант всегда необходимо явно указывать тип данных.
Имена констант должны состоять из заглавных букв, а в качестве разделителя использовать знак подчёркивания.
#![allow(unused)]
fn main() {
const PI: f32 = 3.14;
const ANONYMOUS_NAME: &str = "anonymous";
}static
Статические переменные создаются в самом начале работы программы и существуют до её завершения, однако в отличие от констант, статические переменные:
- инициализируются уже во время работы программы, а не на этапе компиляции
- могут быть мутабельными
- могут содержать объекты, хранящие данные в куче
Статическая переменная объявляется при помощи ключевого слова static:
#![allow(unused)]
fn main() {
static ИМЯ: Тип = значение;
}Статические переменные могут быть как глобальными, так и локальными для функции. Оба вида мы отдельно разберём в соответствующих главах.
Мутабельная статическая переменная — потенциально небезопасный ресурс, так как она может быть одновременно изменена из нескольких потоков. Поэтому работа с мутабельными статическими данными — unsafe операция, о чём мы еще поговорим позже.
Note
В то время как константы, как правило, хранятся в сегмента кода, статические переменные хранятся в сегменте bss (Block Started by Symbol) или в сегменте данных.
Префикс _
Компилятор выдает предупреждения (warning) для каждой неиспользуемой переменной — переменной, которая объявлена и, возможно, инициализирована, но при этом не используется в каком-либо выражении.
Если мы намеренно хотим иметь в коде такую переменную (например, как задел для будущей функциональности), то мы можем начать имя переменной со знака подчёркивания.
Например:
#![allow(unused)]
fn main() {
let _some_unused_variable = 5;
}Компилятор не будет выдавать предупреждений о том, что такая переменная не используется.
“выброшенные” переменные
Если переменная состоит из одного только символа подчёркивания _, то она является “выброшенной” (discarded). Такая переменная семантически существует, однако обратиться к ней никак нельзя.
#![allow(unused)]
fn main() {
let _ = 5;
}Один из сценариев применения “выброшенных” переменных — сознательное игнорирование результата функции. Мы рассмотрим этот пример в главе Result
Также мы увидим применение таких переменных в главах Деструктурирующее присваивание и Паттерн матчинг.
Примитивные типы данных
В языке Rust имеются такие примитивные типы данных.
Целочисленные типы
| Размер | Знаковый | Беззнаковый |
|---|---|---|
| 8 бит | i8 | u8 |
| 16 бит | i16 | u16 |
| 32 бита | i32 | u32 |
| 64 бита | i64 | u64 |
| 128 бит | i128 | u128 |
| Платформозависимый (равный размеру указателя) | isize | usize |
Если мы объявляем переменную без указания типа и инициализируем её целым числом, то по умолчанию используется тип i32. Если же мы инициализируем переменную числом с плавающей запятой, то по умолчанию используется тип f64.
#![allow(unused)]
fn main() {
let a = 5; // i32
let b = 5.0; // f64
}Тип числа можно указывать как явно, так и при помощи суффикса к инициализирующему значению:
#![allow(unused)]
fn main() {
let a: u8 = 5;
let b = 5u8;
let c: f32 = 5.0;
let d = 5.0f32;
let e: u128 = 1;
let f = 1u128;
}Числа с плавающей запятой
Для представления чисел с плавающей запятой в Rust имеется два типа: f32 и f64. Соответственно, их размер 32 и 64 бита.
Оба типа реализуют стандарт IEEE-754, то есть значения типов f32 и f64 могут хранить как вещественные числа, так и “бесконечность” и “не число”.
#![allow(unused)]
fn main() {
let a: f32 = -1.0; // 1.0
let b = 5.0f32; // 5.0
let c = a + b; // 4.0
let d = 1.0 / 0.0; // inf
let e = a.sqrt(); // NaN
}bool
Булевый тип в Rust ровно такой, каким его можно ожидать: может хранить либо true, либо false.
#![allow(unused)]
fn main() {
let a: bool = true;
let b = false;
}Значение типа bool занимает в оперативной памяти 1 байт.
Символы
Для хранения отдельных текстовых символов используется тип char. Фактически это 4-байтное число, хранящее код символа в таблице Unicode.
Rust позволяет указать символ в исходном коде программы, как текстовый знак, взятый в одинарные кавычки.
#![allow(unused)]
fn main() {
let a = 'a';
let smile = '☺';
let book = '本';
}Unit
Тип Unit — аналог типа void в C, Java и других им подобных языках. Как правило, он используется для обозначения типа результата в функциях, которые не возвращают какое-либо значение.
Хоть тип и называется “Unit”, в коде он обозначается как () .
Принципиальное отличие типа Unit, являющегося множеством-синглтон, от типа void, который представляет пустое множество, заключается в том, что у типа Unit есть одно единственное значение —(). Мы можем даже создать переменную типа Unit и присвоить ей () .
#![allow(unused)]
fn main() {
let a: () = ();
}Tip
Чем не подходит void? Тип Unit появился в языках, которые испытали на себе влияние функционального программирования. Дело в том, что в функциональном программировании функция рассматривается, в первую очередь, как математическая функция, т.е. отображение значения из множества аргументов в значение из множества результатов. Здесь и появляется фундаментальная проблема типа
void: это пустое множество, в котором нет значений. Это сильно усложняет моделирование системы типов для таких важных в функциональном программировании операций, как композиция функций.В чисто функциональном языке Haskell даже имеется специальная функция
absurd, которая принимает аргумент типа Void и возвращает некое значение.absurd :: Void -> aКакое это значение и какого оно типа — не важно, так как эту функцию невозможно вызвать, ведь для её вызова необходим элемент из пустого множества Void, а такой не существует.
Never type
Еще один интересный тип, обусловленный особенностями системы типов данных в языках, испытавших воздействие функционального программирования, — never type.
В коде этот тип обозначается как !
Этот тип практически никогда не указывается явно и даже не наблюдается в коде. Более того, если не знать о его наличии, то можно годами писать на Rust и даже не подозревать о его существовании.
На данном этапе мы пока что не сможем разобраться с этим типом. Скажем только, что компилятор использует этот тип для выражений, которые никогда не возвращают значение в вызывающий код. Например, для функции выхода из программы.
Мы подробнее рассмотрим never type в главе Функции.
Приведение типов
Для того чтобы преобразовать один тип данных в другой, используется оператор as.
Синтаксис:
значение as Тип
Пример:
fn main() {
let a: i32 = 5;
let b: i64 = a as i64;
let c: i32 = b as i32;
let d: f32 = 7.0;
let e: i32 = d as i32;
let f: bool = true;
let g: i32 = f as i32; // 1
let h = false as i32; // 0
let i = 'A' as i32; // 65
let j = 66 as char; // B
}Rust является языком со строгой типизацией, поэтому в нём отсутствуют неявные преобразования типов, как в C. Любое преобразование типов нужно указывать явно при помощи оператора as.
Печать на консоль
Как мы уже видели в примере “Hello World” из главы Первый взгляд, для печати на консоль используется вызов println!.
Функция println! не так проста, как кажется. Да и не функция это никакая, а макрос. Причём если вы знакомы с макросами в C, то позвольте вас сразу успокоить: в Rust макросы куда безопаснее и удобнее.
Разбираться с тем, как устроены макросы в Rust и как именно работает макрос println!, мы будем потом в главе Декларативные макросы. А пока что давайте просто посмотрим на примеры использования println!, которые нам понадобятся для изучения последующего материала.
Чтобы напечатать строку на консоль, нужно просто передать её в вызов println! в качестве аргумента.
#![allow(unused)]
fn main() {
println!("Print just text");
}Если же нужно вывести на консоль значение переменной, то в вызов println! необходимо передать два аргумента:
- 1-й аргумент: строка с текстом для печати на консоль, которая в том месте, где мы хотим вывести значение переменной, содержит форматирующую комбинацию
{} - 2-й аргумент: переменная, значение которой встанет на место форматирующей комбинации
{}
Например:
fn main() {
let magic_number: i32 = 5;
println!("Number is {}", magic_number);
}Если скомпилировать и запустить эту программу, то мы увидим следующее:
$ rustc main.rs
$ ./main
Number is 5
Note
Это пример сборки и выполнения в Linux. В Windows сборка и запуск будут выглядеть как:
rustc main.rs main.exe Number is 5
Если мы хотим распечатать две переменные, то в форматирующей строке должны указать две {} комбинации и далее передать две переменные:
#![allow(unused)]
fn main() {
let number_1 = 5;
let number_2 = 6;
println!("Number 1 is {}, number 2 is {}", number_1, number_2);
}Альтернативно, переменную можно указывать не после форматирующей строки, а непосредственно в ней — внутри фигурных скобок:
#![allow(unused)]
fn main() {
let magic_number: i32 = 5;
println!("Number is {magic_number}");
}Также имеется комбинированный вариант: когда внутри {} мы задаём псевдоним, а после привязываем к этому псевдониму значение.
#![allow(unused)]
fn main() {
let magic_number: i32 = 5;
println!(
"Number is {num}, num in the power of two is {square}",
num = magic_number,
square = magic_number * magic_number
);
}Вышеуказанным образом выводить на консоль можно только значения типов, для которых определён трэйт std::fmt::Display. Про трэйты мы поговорим позже, а пока что нам нужно знать то, что через {} можно передавать только значения типов, для которых явно прописано, как значения этих типов преобразуются в строки.
Для всех примитивных типов в стандартной библиотеке Rust уже имеется реализация std::fmt::Display, что позволяет непосредственно выводить их через println!. Но для большей части типов (например, для массивов) это не так.
Однако если в вызове println! в форматирующей строке заменить {} на {:?}, то мы сможем выводить значения типов, для которых определён трэйт std::fmt::Debug, а таких типов подавляющее большинство.
Пока что не заостряйте внимание на этом моменте, так как мы его коснёмся еще не раз.
Скоупы
В Rust время жизни переменной ограничено скоупом — блоком из фигурных скобок, в котором она объявлена. По завершению скоупа все переменные, объявленные в нём, автоматически удаляются.
fn main() {
let a = 1;
{
let b = 2;
// В этом месте существуют и a, и b
} // Выход из скоупа: b удаляется
// В этом месте существует только a
let c = 3;
} // Выход из скоупа: a и c удаляютсяЗначение скоупа
В Rust каждый скоуп возвращает значение. Это значит, что результат скоупа можно присвоить переменной. Само же значение, возвращаемое скоупом — это последнее значение, вычисленное в скоупе.
#![allow(unused)]
fn main() {
let a: i32 = {
let x = 1;
let y = 2;
x + y // последнее вычисленное выражение
};
println!("{a}"); // 3
}Будьте внимательны: чтобы результат последнего выражения стал результатом скоупа, после него не должно быть точки с запятой.
Дело в том, что в отличие от C, где ; означает конец текущего выражения, в Rust ; служит разделителем между выражениями. То есть, например, выражение
{ a; }
трактуется как
{ a; () }
и, следовательно, результат всего скоупа будет — Unit, а не a.
Вот так будет выглядеть пример выше, если по ошибке поставить ; в конце скоупа.
#![allow(unused)]
fn main() {
let a: () = {
let x = 1;
let y = 2;
x + y;
};
}Тот факт, что скоуп возвращает значение, используется в ряде других конструкций, о которых мы поговорим далее.
Ссылки
Ссылка — это переменная, которая “ссылается” на данные, хранимые в другой переменной.
Для создания ссылки на значение, хранимое в переменной, используется оператор &.
let переменная: Тип = значение;
let ссылка: &Тип = &переменная;При этом тип ссылки будет &тип_изначальной_переменной.
Например:
fn main() {
let a: i32 = 5;
let ref_a: &i32 = &a;
println!("Value in a is {}", *ref_a); // Value in a is 5
}Оператор * в выражении *ref_a используется для получения значения, на которое ссылается ссылка.
Ссылки, как и переменные, по умолчанию являются немутабельными, т.е. с их помощью можно читать значение оригинальной переменной, но не изменять его. Чтобы создать мутабельную ссылку, нужно вместо & использовать &mut. Разумеется, мутабельную ссылку можно получить только для мутабельной переменной:
fn main() {
let mut a: i32 = 5;
let ref_a: &mut i32 = &mut a;
*ref_a = 99;
println!("Value in a is {}", *ref_a); // Value in a is 99
}Note
В отличие от указателей в C, которые являются физическим типом данных, т.е. ячейкой в памяти, в которой хранится адрес, ссылка в Rust является скорее семантической сущностью. То есть в большинстве случаев создание ссылки в коде не приводит к созданию дополнительных сущностей в памяти программы: компилятор просто подменяет взаимодействие с ссылкой на взаимодействие со значением непосредственно. При этом на уровне кода программы ссылка ведёт себя так, словно это физический “указатель” на данные, хранимые в другой переменной.
В Rust ссылки являются безопасными: компилятор отслеживает время жизни ссылок относительно времени жизни переменных, на чьи данные они указывают. При попытке сослаться на данные, принадлежащие уже уничтоженной переменной, компилятор выдаст ошибку.
Мы поговорим подробнее о ссылках в главе Владение, а также в главе Лайфтаймы.
Массивы
Массивы в Rust представляют из себя непрерывную последовательность значений, размер которой известен на момент компиляции.
Тип массива состоит из двух частей: тип элементов массива и количество элементов.
[тип_элементов; количество_элементов]
Например, массив из трёх элементов типа i32:
#![allow(unused)]
fn main() {
let arr: [i32; 3] = [1, 2, 3];
}Размер массива нельзя задать во время выполнения программы (например, считать с консоли желаемый размер и сконструировать его). Он обязательно должен быть известен во время компиляции, что делает массив полезным в редких случаях.
Например, массив из четырёх байт хорошо подходит для хранения IPv4 адреса.
fn main() {
let mut arr: [u8; 4] = [192, 168, 0, 1];
println!("Array is {arr:?}");
// Напечатает: Array is [192, 168, 0, 1]
}Note
Как мы видим, здесь для вывода на консоль мы используем форматирующую последовательность
{:?}вместо{}. Как мы говорили в разделе Вывод на консоль, это необходимо, так как массив не реализует трэйтstd::fmt::Display, но, как и почти все стандартные типы, реализуетstd::fmt::Debug.
Индексация элементов массива начинается с нуля.
fn main() {
let arr: [u8; 4] = [192, 168, 0, 1];
println!("{}", arr[0]); // 192
}Как и любые другие переменные, переменная-массив по умолчанию немутабельна. Чтобы массив можно было изменять, он должен быть объявлен с ключевым словом mut.
fn main() {
let mut arr = [1,2,3];
arr[1] = 55;
println!("Array is {arr:?}");
// Напечатает: Array is [1, 55, 3]
}Массивы, объявленные внутри функций, всегда располагаются на стеке.
Существует механизм, позволяющий перенести массив в кучу, однако придумать практическое применение для такой операции весьма непросто.
Вектор
Как мы уже знаем, размер массива должен быть известен во время компиляции, что делает его бесполезным для сценариев, при которых размер вычисляется в процессе работы программы.
Тип Vec (вектор) представляет из себя непрерывную последовательность элементов, размер которой может определяться и изменяться во время выполнения программы.
Note
Vec<T>является обобщённой (generic) структурой. И генерики, и структуры мы изучим только несколько глав спустя, однако вектор является настолько вездесущей структурой данных, что изучать даже базовые конструкции Rust без него будет очень сложно. Поэтому, на данном этапе мы только разберёмся, как с ним работать и как он располагается в памяти.
Если же вы знакомы с C++, то вы уже, скорее всего, провели аналогию с шаблонным классомstd::vector, и оказались полностью правы.
Если вы знакомы с Java, то считайте вектор близким родственником классаArrayList<T>.
Для начала рассмотрим пример использования вектора:
fn main() {
// Создаём пустой вектор
let mut my_vec: Vec<i32> = Vec::new();
my_vec.push(1); // Добавляем 1 в конец вектора
my_vec.push(2); // Добавляем 2 в конец вектора
my_vec.push(3); // Добавляем 3 в конец вектора
// Копируем в переменную third значение элемента с индексом 2 (индексация с нуля)
let third: i32 = my_vec[2];
println!("3-rd element: {}", third);
}Как видно, с точки зрения использования, вектор можно рассматривать просто как динамически расширяемый массив.
Лэйаут (расположение) в памяти
Теперь поговорим о том, как вектор хранится в памяти. Когда мы создаём переменную вектора, то на стеке располагается только его “служебная информация”, а сами данные хранятся в куче.
На стеке хранятся такие 3 поля:
- указатель на начало буфера в куче — в этом буфере хранятся сами элементы вектора
- счётчик количества элементов, записанных в буфере в куче
- размер буфера в куче
Лэйаут (layout) вектора из примера выше в оперативной памяти выглядит так:

Размер буфера в куче, который вектор изначально создаёт для хранения элементов, не стандартизирован, но на данной диаграмме мы предположили, что он равен 5.
Если желаемый размер буфера в куче известен заранее, то его можно задать явно, заменив Vec::new() на Vec::with_capacity(размер). Это приведёт к тому, что вектор аллоцирует первичный буфер в куче ровно такого размера, чтобы иметь возможность вместить ровно заданное количество элементов.
При добавлении элементов в вектор, счётчик элементов в буфере (len) увеличивается. Когда len становится равным capacity — то есть буфер в куче будет полностью заполнен, тогда вектор аллоцирует новый буфер большего размера, копирует в него все элементы из старого буфера и затем удаляет старый буфер. Последующее добавление элементов продолжится уже в новый буфер.
#![allow(unused)]
fn main() {
let mut my_vec: Vec<i32> = Vec::with_capacity(3);
my_vec.push(1);
my_vec.push(2);
my_vec.push(3);
// <- на этом месте буфер, чья вместимость - 3 элемента, уже заполнен
// Добавление 4-го элемента приведёт к выделению нового буфера
// и копированию в него 1,2,3.
// После этого 4 будет добавлено уже в новый буфер.
my_vec.push(4);
}Макрос vec!
В предыдущем примере для создания вектора с элементами мы сначала создали пустой вектор, а затем один за другим добавили в него все необходимые элементы. Согласитесь, что добавлять элементы по одному — весьма неудобно.
Поэтому, учитывая, что вектор является наиболее часто используемой структурой данных, в стандартную библиотеку Rust включили специальный макрос vec![], который берёт на себя бремя поэлементного добавления элементов в вектор.
При помощи этого макроса, мы можем переписать пример выше таким образом:
fn main() {
let mut my_vec = vec![1,2,3];
let third: i32 = my_vec[2];
println!("3-rd element: {}", third);
}Как работает этот макрос станет понятно только после прочтения главы Декларативные макросы.
Слайсы
Подобно тому, как ссылка указывает на данные, принадлежащие некой переменной, слайс — это специальная ссылка, которая указывает на последовательность элементов, как правило, принадлежащих другой переменной (вектору, массиву, и т.д.).
Аналогично тому, как ссылка создаётся оператором &, слайс создаётся оператором &[].
#![allow(unused)]
fn main() {
let arr: [i32; 5] = [0, 1, 2, 3, 4]; // массив
let slice1: &[i32] = &arr[..]; // слайс на все элементы массива
let slice2: &[i32] = &arr[2..=4]; // слайс на элементы со 2го по 4-й включительно
// альтернативно можно было бы написать
// let slice2: &[i32] = &arr[2..5]; // то есть со 2-го до 5-го не включительно
}Слайс позволяет обращаться к элементам по их индексу (относительно начала слайса, а не относительно начала оригинальной последовательности).
fn main() {
let arr = [0, 1, 2, 3, 4];
let slice: &[i32] = &arr[2..=4]; // слайс на элементы со 2го по 4-й
println!("{}", slice.len()); // 3 (размер слайса)
println!("{}", slice[2]); // 4 (2-й по индексу элемент слайса)
}В отличие от обычных ссылок, которые, как правило, эфемерны (не представлены отдельными ячейками в памяти), слайсы хранятся в памяти в виде пары полей:
- адрес первого элемента последовательности
- количество элементов

По умолчанию слайсы, как и ссылки, — немутабельны. Для того, чтобы сделать мутабельный слайс, нужно использовать ключевое слово mut.
Рассмотрим пример изменения элементов вектора посредством мутабельного слайса:
fn main() {
let mut v: Vec<i32> = Vec::with_capacity(5);
v.push(0);
v.push(1);
v.push(2);
v.push(3);
let slice: &mut [i32] = &mut v[1..3]; // слайс на элементы со 1го до 3го
slice[0] = 9;
println!("v[1]: {}", v[1]); // 9
}В памяти это соотношение вектора и слайса выглядит так:

Строки
Note
Если эта глава кажется вам трудной при первом прочтении, не пытайтесь понять её полностью. Вернитесь к ней после прочтения глав про Владение и Структуры.
Строки в Rust хранятся в виде буферов с символами в UTF-8 кодировке. При этом в Rust есть два основных типа для строк, которые отличаются тем, как они взаимодействуют с этим буфером: &str и String.
&str (строковый слайс)
Если мы напишем в коде программы строковый литерал (строку в двойных кавычках), то эта строка будет иметь тип &str.
#![allow(unused)]
fn main() {
let s: &str = "some text";
}По сути &str — это слайс, ссылающийся на буфер с последовательностью символов в кодировке UTF-8.
В каком-то смысле такие строки похожи на const char* строки в языке C, с той разницей, что в отличие от C, &str, будучи слайсом, хранит не только начальный адрес буфера в памяти, но и его длину.
Когда компилятор находит в коде строковый литерал, он, как правило, помещает эту строку в сегмент данных (или в сегмент кода, в зависимости от целевой платформы), и там эта строка “живёт” от самого начала программы и до её конца.
Тип &str не занимается управлением памяти, в которой находится строка, он просто ссылается на данные в памяти. При этом эта память может принадлежать как сегменту данных, так и куче (и являться собственностью объекта String) или даже располагаться на стеке.
String
Если &str — это слайс, который ссылается на буфер со строкой, но никак не управляет этим буфером, то String, наоборот, является собственником буфера, в котором содержится строка.
Технически String является обёрткой над вектором Vec<u8>, который хранит последовательность символов в кодировке UTF-8. Поэтому String всегда единолично владеет буфером со своей строкой, и этот буфер всегда располагается в куче.
При этом для любого String всегда можно создать слайс &str, который будет ссылаться на строковый буфер, находящийся во владении String.
Есть 3 способа создать переменную типа String:
- При помощи конструктора
String::from - При помощи
String::newсоздать пустую строку и далее наполнить её отдельно - Из
&strпри помощи методаto_string()
Конструктор String::from
Наиболее понятный способ создания объекта String — функция-конструктор (о них мы поговорим в главе Структуры) String::from(&str), которая в качестве аргумента принимает слайс &str. Эта функция:
- создаёт объект
String, который как мы уже сказали, — просто обёртка надVec<u8>(вектором хранящим буфер с элементами типаu8) - далее из аргумента
&strкопирует строку в свежесозданный вектор - и после возвращает готовый, инициализированный объект
String
fn main() {
// слайс на статическую строку, находящуюся в сегменте даных
let slice: &str = "text";
// Создаст в куче буфер и скопирует в него "text".
// На стеке будет тройка значений, как у Vec:
// адрес буфера, общий размер буфера и количество заполненных строкой байт
let s = String::from(slice);
}Note
Разумеется, гораздо короче и проще написать просто
String::from("text"), что в большинстве случаев и делают. В примере выше мы создали отдельную переменнуюsliceисключительно для наглядности.
Конструктор String::new
Функция-конструктор String::new просто создаёт новый объект String с пустым строковым буфером. Это может быть нужно, например, для того, чтобы передать объект String в функцию, которая заполнит его текстом.
Например, функция, которая читает строку с консоли, в качестве параметра принимает мутабельную ссылку на объект String, в который будет записан текст, считанный с консоли.
fn main() {
println!("Please enter some text and hit Enter button");
let mut buf = String::new(); // создаём пустую строку
std::io::stdin().read_line(&mut buf); // считываем текст с консоли в buf
println!("You have entered: {buf}");
}Также в пустую строку (да и не только в пустую) можно добавлять символы при помощи метода push(char) или сразу строковые слайсы при помощи метода push_str(&str).
fn main() {
let mut s = String::new();
s.push('H');
s.push('e');
s.push('l');
s.push('l');
s.push('o');
s.push_str(" world!");
println!("{s}"); // Hello world!
}Метод to_string()
Последний способ создания объекта String — вызов метода to_string() на объекте слайса &str. По сути, этот метод делает абсолютно то же самое, что и String::from(&str), только с другим синтаксисом.
fn main() {
let s: String = "text".to_string();
}&str и String в памяти
Чтобы подытожить, как &str и String располагаются в памяти, давайте рассмотрим следующий пример, в котором мы:
- Создаём слайс
&strиз строкового литерала - Далее создаём
Stringиз этого слайса - Создаём слайс, ссылающийся на строковый буфер объекта
String
fn main() {
// Компилятор увидит константный строковый литерал и поместит
// такую строку в сегмент статических данных.
let a_slice_1: &str = "text";
// Создаём String из символов, на которые указывает слайс.
// Это приведёт к созданию копии символов строки в куче.
let a_string: String = String::from(a_slice_1);
// Создаём второй слайс, который указывает на буфер символов в хипе,
// принадлежащей String-строке.
let a_slice_2: &str = a_string.as_str();
}Примерно так эти строки будут располагаться в памяти:

Макрос format!
Мы уже знакомы с макросом println!, который используется для вывода на консоль. Этот макрос в качестве аргумента принимает форматирующую строку, в которую при помощи {} можно “встраивать” значения.
Стандартная библиотека предлагает еще один макрос — format!. Он принимает на вход такую же форматирующую строку, как и println!, только, в отличие от последнего, он не печатает текст на консоль, а возвращает его в виде объекта String.
fn main() {
let s: String = format!("{} in the power of the 2 is {}", 3, 9);
println!("{s}"); // 3 in the power of the 2 is 9
}Условный оператор if
Как и в большинстве языков программирования, в Rust условный оператор if тоже есть.
Его синтаксис имеет вид:
if условие_1 {
выражение_1
} else if условие_2 {
выражение_2
} else {
выражение_3
}Например:
fn main() {
let a = 10;
if a % 2 == 0 {
println!("a is even");
} else {
println!("a is odd");
}
}В Rust, в отличие от C и Java, тело условной ветки обязательно должно быть обрамлено в фигурные скобки, даже если ветка содержит только одно выражение.
Результат оператора if
Оператор if является выражением, т.е. возвращает значение, которое можно присвоить переменной. Результатом всего if выражения является результат последнего выражения в отработавшей ветке.
#![allow(unused)]
fn main() {
let a = -5;
let mod_a: i32 =
if a < 0 {
-a
} else {
a
};
println!("{mod_a}"); // 5
}Здесь важно заметить, что для того, чтобы оператор if возвращал значение, последнее выражение в условной ветке НЕ должно заканчиваться знаком ;. Дело в том, что, как мы уже сказали, тело условной ветки всегда должно быть обрамлено в фигурные скобки, а это значит, что она является скоупом. Как мы уже знаем из главы Скоупы, если в конце последнего выражения скоупа стоит ;, то скоуп возвращает ().
#![allow(unused)]
fn main() {
let a = -5;
let mod_a: () =
if a < 0 {
-a; // то же самое, что и { -a; () }
} else {
a; // то же самое, что и { a; () }
};
println!("{mod_a:?}"); // Напечатает ()
}Tip
В английском языке есть принципиальная разница между понятиями statement (утверждение) и expression (выражение).
Словом statement называют код, который выполняется и ничего не возвращает. Например, в C/Java конструкция, заканчивающаяся знаком
;является statement.Expression — это выражение, которое вычисляет и возвращает значение. Примером expression в C/Java является
1 + 1, так как оно возвращает2.В русском языке, как правило, и statement и expression переводят как “выражение”, что создаёт путаницу.
Циклы
while
Цикл while в Rust работает и выглядит так же, как и в других императивных языках:
while условие {
тело цикла
}Например, вывод на консоль чисел от 5 до 0 (не включительно).
fn main() {
let mut n = 5;
while n > 0 {
println!("{n}");
n -= 1;
}
}do-while
В Rust нет цикла do-while, но при большой необходимости его можно имитировать через while:
Такой код
|
работает словно
|
loop
В Rust есть специальный “бесконечный” цикл — loop. По сути, это просто аналог while true.
loop {
тело цикла
}Как и из while true цикла, из loop можно выйти при помощи оператора break.
Например: программа, которая выводит те элементы последовательности Фибоначчи, которые меньше указанного числа (мы подразумеваем, что указанное число всегда больше 1).
fn main() {
let maximum = 30;
let mut a = 0;
let mut b = 1;
print!("{a} {b}");
loop {
let next = a + b;
if next > maximum {
break;
}
print!(" {next}");
a = b;
b = next;
}
}Оператор break для цикла loop имеет еще одну функциональность: он возвращает значение.
#![allow(unused)]
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2; // возвращаем из цикла
}
};
println!("The result is {}", result); // 20
}Тип оператора break — never type.
for
В Rust отсутствует “классический” цикл for (как в C) — только for-each, который предназначен для перебора элементов последовательностей.
Синтаксис:
for переменная in последовательность {
тело цикла
}Пример: перебор элементов массива.
fn main() {
let arr = [10, 20, 30, 40, 50];
for element in arr {
println!("the value is: {}", element);
}
}При помощи for можно перебирать элементы массивов, слайсов, векторов и еще целого ряда коллекций.
Перебор диапазона
В Rust нет “классического” цикла for вида for (int i=0; i<N; i++). Однако такой перебор числового диапазона требуется довольно часто.
К счастью, в Rust есть диапазоны (Range), которые задаются как начало .. конец, и могут использоваться для перебора элементов в цикле for.
#![allow(unused)]
fn main() {
for i in 0 .. 10 {
print!("{}, ", i);
}
// Напечатает: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
}Этот цикл перебирает числа от 0 до 10 (не включительно).
Чтобы перебрать числа от 0 до 10 (включительно), надо вместо 0 .. 10 указать 0 ..= 10.
Note
Детальнее о цикле for мы поговорим в главах Владение и Итераторы. Также в главе про Итераторы мы подробнее разберём диапазоны.
Функции
Как и в других языках программирования, в Rust функции — это механизм, позволяющий разбить программу на отдельные гранулированные подпрограммы.
Синтаксис объявления функции:
fn func_name(arg1: Тип1, arg2: Тип2) -> ТипВозвращаемогоЗначения {
тело функции
}Пример:
fn sum(a: i32, b: i32) -> i32 {
a + b
}
fn safe_divide(a: f32, b: f32) -> f32 {
if b != 0.0 {
a / b
} else {
0.0
}
}
fn main() {
let a = sum(1, 2);
println!("{a}");
let b = safe_divide(12.0, 4.0);
println!("{b}");
}При объявлении аргументов функции можно вставлять запятую после последнего аргумента, и поведение будет таким же, как и без неё.
fn sum(a: i32, b: i32,) -> i32 { .. }return
Как мы видим, последнее вычисленное значение автоматически является результатом функции.
При необходимости “досрочно” выйти из функции, следует явно использовать оператор return:
fn safe_divide(a: f32, b: f32) -> f32 {
if b == 0.0 {
return 0.0;
}
a / b
}
fn main() {
println!("12 / 3 = {}", safe_divide(12.0, 3.0));
println!("12 / 0 = {}", safe_divide(12.0, 0.0));
}Функции внутри функций
Rust позволяет объявлять функцию внутри другой функции.
Если часть функциональности функции хорошо гранулирована и используется несколько раз и при этом не нужна больше нигде в программе, то её можно вынести в отдельную внутреннюю функцию.
// Возвращает i-й элемент последовательности Фибоначчи.
// Индексация элементов последовательности - с нуля.
fn fibonacci_nth_element(index: usize) -> u32 {
if index == 0 {
return 0;
}
if index == 1 {
return 1;
}
// Высчитывет i-й элемент последовательности Фибоначчи
// * x0 - i-й элемент последовательности
// * x1 - (i+1)-й элемент последовательности
// * next_index - индекс следующего (i+2) элемента
// * desired_index - индекс искомого элемента
fn next_fibonacci(x0: u32, x1: u32, next_index: usize, desired_index: usize) -> u32 {
let x2 = x0 + x1;
if next_index == desired_index {
x2
} else {
next_fibonacci(x1, x2, next_index + 1, desired_index)
}
}
next_fibonacci(0, 1, 2, index)
}
fn main() {
println!("{}", fibonacci_nth_element(0)); // 0
println!("{}", fibonacci_nth_element(1)); // 1
println!("{}", fibonacci_nth_element(2)); // 1
println!("{}", fibonacci_nth_element(3)); // 2
println!("{}", fibonacci_nth_element(4)); // 3
}return и never type
Tip
Приведённая ниже информация не является необходимой для программирования на Rust, а скорее просто даёт лучшее понимание системы типов.
В главе Примитивные типы данных мы уже упоминали never type !, который используется для тех выражений, которые не возвращают управление в вызывающий код.
Оператор return возвращает значение типа !, так как он завершает исполнение функции и, следовательно, ничего в неё не возвращает.
fn gen_num() -> i32 {
// Переменная v имеет тип !
let v = return 5;
}
fn main() {
let a = gen_num();
}Never type не представляет каких-то реальных данных, а просто играет роль заглушки, чтобы “склеить” воедино систему типов Rust. Давайте рассмотрим примере:
fn safe_divide(a: f32, b: f32) -> f32 {
let non_zero_divider: f32 =
if b != 0.0 {
b
} else {
return 0.0
};
a / non_zero_divider
}
fn main() {
println!("12 / 0 = {}", safe_divide(12.0, 0.0));
}Обратите внимание, что тип переменной non_zero_divider — f32. Но как так получается? Ведь тип результата в первой ветке выражения if — f32, а тип результата во второй ветке — ! (never type).
Дело в том, что тип never type автоматически приводится к любому другому типу. Это абсолютно безопасно, так как в реальности это преобразование значения типа ! в значение другого типа всё равно никогда не происходит. Но именно это свойство never type является тем самым “клеем”, который согласовывает типы в подобных выражениях.
Tip
Программисты знакомые с языком Scala, могут провести аналогию с типом
Nothing.
const функции
В Rust можно задать функцию, которая может быть выполнена на этапе компиляции. Такая функция отмечается ключевым словом const.
#![allow(unused)]
fn main() {
const fn func_name(arg1: Тип1, arg2: Тип2) -> ТипВозвращаемогоЗначения {
тело функции
}
}Например:
const PI: f32 = 3.14;
const TAU: f32 = double(PI);
const fn double(num: f32) -> f32 {
num * 2.0
}
fn main() {
println!("Tau = {TAU}");
}static переменные
Функция может содержать статические переменные, значения которых сохраняются между вызовами функций.
Это проще показать на примере.
fn sum_with_previous(x: i32) -> i32 {
static mut PREV: i32 = 0; // статическая переменная
unsafe {
let result = PREV + x;
PREV = x;
result
}
}
fn main() {
println!("{}", sum_with_previous(1)); // 1
println!("{}", sum_with_previous(2)); // 3
println!("{}", sum_with_previous(7)); // 9
println!("{}", sum_with_previous(-6)); // 1
}Функция sum_with_previous складывает значение аргумента со значением аргумента из своего предыдущего вызова. Для этого она использует статическую переменную PREV, которая живёт вне контекста вызова функции.
Как видно, PREV инициализируется нулём. Эта инициализация выполняется только для первого вызова функции.
Также хочется отметить, что всё взаимодействие с мутабельной статической переменной может выполняться только внутри блока unsafe. Дело в том, что потенциально эта функция может быть одновременно вызвана из нескольких параллельных потоков, что может привести к сохранению или чтению некорректного значения PREV одним из потоков. Это классический пример гонок за данные (data race), что в безопасном Rust недопустимо. Именно поэтому необходим unsafe блок.
Это первый раз, когда мы сталкиваемся с блоком unsafe. Мы еще познакомимся с ним подробнее, а пока что скажем, что вся ответственность за безопасность кода внутри блока unsafe ложится на плечи его автора. Поэтому стоит избегать использования небезопасного Rust, если в этом нет необходимости.
Как вы могли понять, мутабельные статические переменные не особо безопасны по своей природе и могут быть использованы без дополнительных механизмов синхронизации только в однопоточной среде. К счастью, в back-end приложениях вы скорее всего никогда не будете их использовать — мы рассмотрели их только для того, чтобы больше раскрыть тему функций.
Кортежи
Как мы знаем, массив в Rust — это последовательность заранее известного размера, содержащая элементы одинакового типа. Массивы хорошо подходят для хранения таких сущностей, как, например, координаты в пространстве: [x, y, z] — все три составляющие координаты имеют одинаковый тип. Но что делать, если для хранения какой-то сущности требуется последовательность элементов разного типа?
Например, мы разрабатываем картотеку для отдела кадров, и по каждому сотруднику нам необходимо хранить его полное имя, дату рождения и пометку, является ли сотрудник действующим, — всё это данные разных типов: String, u32 и bool. Решить нашу задачу могут помочь кортежи.
Кортеж — это последовательность заранее известного размера, которая может содержать элементы разных типов.
Tip
Программисты на Java могут провести аналогию с классами
Pair<T1,T2>иTriplet<T1,T2,T3>из библиотеки Apache Commons.
Синтаксис объявления кортежа выглядит так:
(значение_1, значение_2, …, значение_N)
Пример: кортеж для хранения имени сотрудника, даты его рождения и пометки, является ли он действующим сотрудником.
#![allow(unused)]
fn main() {
let employee: (&str, i32, bool) = ("John Doe", 1980, true);
}Доступ к элементам кортежа осуществляется при помощи . после которой следует индекс элемента (индексация с нуля).
#![allow(unused)]
fn main() {
println!(
"Name: {}, birth year: {}, active: {}",
employee.0, employee.1, employee.2
);
}Также для кортежей есть удобный синтаксис, который позволяет за раз “разложить” весь кортеж на элементы и присвоить эти элементы переменным.
#![allow(unused)]
fn main() {
let (name, birth_year, is_active) = employee;
}Note
Такая операция “разложения” на составляющие называется деструктурирующим присваиванием. О ней мы отдельно поговорим в главе Деструктурирование
Возврат кортежа из функции
Одно из удобных применений кортежа — возврат нескольких значений из функции.
Например, нам нужна функция, которая принимает в качестве аргумента последовательность чисел и разделяет её на две части: первая содержит все нечётные числа, вторая — все чётные.
fn split_to_odd_and_even(numbers: &[i32]) -> (Vec<i32>, Vec<i32>) {
let mut odds = Vec::new(); // для нечётных
let mut evens = Vec::new(); // для чётных
for n in numbers {
if n % 2 != 0 {
odds.push(*n);
} else {
evens.push(*n);
}
}
(odds, evens)
}
fn main() {
let numbers = vec![1,2,3,4,5,6,7,8,9];
let (odds, evens) = split_to_odd_and_even(&numbers); // получаем слайс на вектор
println!("Odd numbers: {odds:?}");
println!("Even numbers: {evens:?}");
}Как мы видим, здесь в теле функции split_to_odd_and_even мы создали два вектора и оба вернули из функции путём “заворачивания” в кортеж.
Также заметим, что функция split_to_odd_and_even в качестве аргумента ожидает слайс, поэтому при помощи оператора & мы создаём слайс, указывающий на элементы вектора. Такая передача последовательности в функцию посредством слайса — одна из распространённых практик в Rust. Это позволяет вызывать функцию как для вектора, так и для массива.
Например, так бы выглядел вариант с массивом:
fn main() {
let numbers = [1,2,3,4,5,6,7,8,9];
let (odds, evens) = split_to_odd_and_even(&numbers); // получаем слайс на массив
println!("Odd numbers: {odds:?}");
println!("Even numbers: {evens:?}");
}Владение
(ownership)
Главная отличительная особенность Rust от других языков заключается в том, что он, не имея сборщика мусора, предлагает производительность уровня языков с ручным управлением памятью. При этом Rust не требует ручного управления памятью и гарантирует отсутствие утечек памяти. Такой результат достигается за счёт концепции владения данными.
Дело в том, что в Rust любой объект непримитивного типа должен иметь только одного владельца. Владелец — это переменная, которой присвоен объект. Поэтому когда значение одной переменной присваивается другой переменной, владение объектом переходит от первой переменной ко второй. При этом первая переменная становится недействительной.
Рассмотрим пример:
fn main() {
let s1 = String::from("some string");
let s2 = s1; // владение строкой переходит от s1 к s2
// В этом месте переменная s1 уже недействильна.
println!("{}", s2); // Теперь можно работать только с s2, но не s1
}Попытка обратиться к недействильной переменной приведёт к ошибке компиляции:
fn main() {
let s1 = String::from("some string");
let s2 = s1;
println!("{}", s1);
// 2 | let s1 = String::from("some string");
// | -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
// 3 | let s2 = s1;
// | -- value moved here
// 4 |
// 5 | println!("{}", s1);
// | ^^ value borrowed here after move
}Тот факт, что у любого объекта есть только один владелец, позволяет компилятору однозначно понять в каком месте память, занимаемая объектом, должна быть очищена. И это место — там, где владелец объекта прекращает своё существование.
Таким образом, в тех местах где переменные прекращают своё существование, компилятор вставляет код вызова деструктора для данных, которыми переменные владели.
Такой подход позволяет управлять памятью без сборщика мусора, при этом гарантировать отсутствие утечек.
Механизм компилятора Rust, который отслеживает время жизни объектов и гарантирует, что память будет очищена, когда нужно, и что в коде не будет обращений к уже очищенной памяти, называется борроу-чекером (borrow-checker).
Владение и скоупы
Как мы знаем, время жизни переменной привязано к скоупу, в котором эта переменная объявлена: когда скоуп завершается, все входящие в него переменные пропадают, а принадлежавшая им память очищается.
Однако переменная, объявленная внутри скоупа, может “отдать” свои данные другой переменной, которая объявлена за пределами этого скоупа.
fn main() {
let s1;
{
let s2 = String::from("some string");
s1 = s2; // значение отдаётся переменной из внешнего скоупа
}
println!("{s1}"); // OK
}Этот пример тривиален, однако по нему хорошо видно, как работает передача владения при переходе между скоупами. Эти знания нам понадобятся в дальнейшем, когда мы будем разбирать Лайфтаймы
Передача владения
Мы уже знаем, что передача владения объектом происходит при присваивании, но есть и другие сценарии.
Вот полный список операций, при которых происходит передача владения объектом:
- присваивание
- передача объекта в функцию в качестве аргумента
- возврат значения из функции
- захват объекта замыканием (этот сценарий мы рассмотрим позже)
Давайте рассмотрим сценарий передачи владения при вызове функции:
fn main() {
let name = String::from("Stas");
// Строка из переменной name уходит в функцию, делая name недействительной
let greeting = greet(name);
// <- Здесь переменная name уже не может быть использована
println!("{}", greeting); // Hello Stas!!!
}
fn greet(name: String) -> String {
// объект строки, возвращаемый вызовом format, перемещается в вызывающий код
format!("Hello {}!!!", name)
}Теперь, когда мы разобрались с тем, что передача переменной в качестве аргумента уничтожает эту самую переменную, давайте посмотрим на пример, который выглядит вполне обычно с точки зрения большинства языков программирования, но станет сюрпризом для изучающих Rust.
Допустим, мы хотим написать программу, которая выводит на консоль строку (неважно откуда мы её берём), а также информацию о длине этой строки. Для того, чтобы подсчитать длину строки, мы сделаем отдельную функцию, которая будет просто вызывать len() на переданной строке.
fn len_of_string(s: String) -> usize {
s.len()
}
fn main() {
let s = String::from("aaa");
let len = len_of_string(s);
println!("{}", s); // <- переменная s уже недействильна здесь
}И вот здесь нас сразу ожидает проблема: мы пытаемся распечатать переменную s, которая уже не действительна, так как она отдала владение своими данными в вызов функции на предыдущей строке.
Как мы можем решить эту проблему? Исключительно абсурдности ради давайте вспомним, что при помощи кортежей мы можем возвращать из функции несколько значений, а значит, мы можем вернуть обратно объект, переданный как аргумент.
fn len_of_string(s: String) -> (String, usize) {
let length = s.len();
(s, length)
}
fn main() {
let s = String::from("aaa");
let (s, len) = len_of_string(s);
println!("Len of {s} is {len}"); // "Len of aaa is 3"
}Выглядит странно, но хорошо демонстрирует, как работает перемещение владения объектом при вызове функций.
К счастью, Rust предоставляет куда более удобный механизм для решения этой проблемы — одалживание.
Note
В стандартной библиотеке Rust есть функция drop, которая уничтожает переданный ей объект.
#![allow(unused)] fn main() { let s = String::from("aaa"); drop(s); }Если посмотреть реализацию функции
drop(мы пока не знакомы с генериками, поэтому не можем полностью понять её сигнатуру), то мы увидим, что она не делает ничего.#![allow(unused)] fn main() { pub fn drop<T>(_x: T) {} }Уничтожение объекта происходит просто за счёт того, что функция
drop, забирает себе владение над объектом и не передаёт его никому дальше.
Одалживание (borrowing)
Вместо того, чтобы передавать в качестве аргумента значение переменной, мы можем передавать ссылку на это значение. Таким образом, владение объектом остаётся за переменной, и мы лишь даём функции попользоваться объектом.
fn len_of_string(s: &String) -> usize {
s.len()
}
fn main() {
let s = String::from("aaa");
let len = len_of_string(&s);
println!("Len of {s} is {len}");
}Такая передача аргумента по ссылке в Rust называется “одалживаем” (borrowing). Это название обусловлено тем, что функция словно берёт объект попользоваться, но возвращает его собственнику после завершения своей работы.
Tip
Если бы мы писали подобную функцию для реальной программы, мы бы разумеется сделали тип аргумента в
len_of_stringне ссылкой на строку&String, а слайсом&str, что позволило бы вызывать функцию как для строкString, так и для строковых литералов.
Мы написали эту функцию таким образом — исключительно для того чтобы было проще объяснить одалживание.
Безопасность ссылок (referential safety)
Из раздела выше мы уже знаем, что в Rust можно взять ссылку на объект и передать её в функцию.
Но давайте рассмотрим такой сценарий:
1) Мы создаём вектор с буфером на 3 элемента и заполняем его значениями.
let mut vector: Vec<i32> = Vec::with_capacity(3);
vector.push(1);
vector.push(2);
vector.push(3);
2) Дальше мы берём немутабельную ссылку на второй элемент вектора. Эта ссылка “указывает” непосредственно на адрес в памяти, по которому хранится второй элемент.
let reference: &i32 = &vector[1];
3) Ссылка на второй элемент еще “жива”, но теперь мы берём еще и мутабельную ссылку на весь вектор целиком. С её помощью мы добавляем в вектор еще один элемент. Буфер вектора был уже заполнен, поэтому в куче аллоцируется новый буфер большего размера, и в него копируются все элементы из старого буфера. После этого в новый буфер добавляется новый элемент, а старый буфер очищается из памяти.
let vec_ref = &mut vector;
vec_ref.push(4);
Вопрос: на что теперь указывает ссылка, которая ссылалась на второй элемент вектора? Разумеется, такая ссылка становится недействительной.
К счастью, Rust является безопасным языком, поэтому компилятор не позволит написать такой код. Выдавая ошибку, он будет руководствоваться правилом безопасности ссылок:
В любом месте кода для любого объекта может существовать либо только одна мутабельная ссылка, либо любое количество немутабельных ссылок.
Также это правило позволяет сделать безопасным использование ссылок в многопоточной среде. Ведь если мы только читаем данные, то это можно делать безопасно из любого количества параллельных потоков. При этом любая операция чтения данных будет потенциально опасной, если существует параллельный поток, который изменяет эти данные.
Чтобы лучше понять как работает контроль ссылок, давайте рассмотрим более простой пример:
fn main() {
let mut s = String::from("x");
let r1 = &mut s; // <-- взятие мутабельной ссылки
let r2 = & s; // <-- попытка взять немутабельную ссылку
println!("{r1}, {r2}");
}Компилятор выдаст ошибку:
4 | let r1 = &mut s; // <-- взятие мутабельной ссылки
| ------ mutable borrow occurs here
5 | let r2 = & s; // <-- попытка взять немутабельную ссылку
| ^^^ immutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- mutable borrow later used here
Перемещение владения для примитивных типов
Все вышеописанные правила владения данными не относятся к примитивным типам.
Примитивные типы занимают мало памяти и не владеют какими-то дополнительными ресурсами, поэтому в тех ситуациях, где для составных типов происходит передача владения, для примитивных типов просто выполняется копирование.
fn increment(a: i32) -> i32 {
a + 1
}
fn main() {
let x = 5;
let y = increment(x);
println!("x={}, y={}", x, y);
}Цикл for и владение
Еще один интересный момент, который следует рассмотреть — это то, как владение работает при итерировании циклом for.
Рассмотрим пример:
fn main() {
let arr = [String::from("1"), String::from("2"), String::from("3")];
for n in arr {
println!("{n}");
}
println!("{arr:?}");
}Этот пример не скомпилируется, так как в цикле for, на каждом витке итерации следующий элемент массива присваивается переменной n для последующего использования в теле цикла. Присваивание приводит к передаче владения.
В итоге, мы уничтожили массив просто распечатав его.
Эта проблема решается так же просто, как и проблема с передачей аргумента в функцию — путём взятия ссылки.
fn main() {
let arr = [String::from("1"), String::from("2"), String::from("3")];
for n in &arr {
println!("{n}");
}
println!("{arr:?}");
}Теперь когда мы заменили arr на &arr в заголовке цикла, на каждой итерации в переменную n присваивается не очередной элемент массива, а ссылка на него. А значит сам массив не уничтожается.
Note
После этого примера может показаться, что написание программ на Rust превращается в постоянную борьбу с компилятором. На первых порах так оно может и быть. Однако после того как вы привыкнете в концепции владения данными, вы будете на автомате писать так, как надо.
Лайфтаймы
Мы уже знаем, что в Rust каждый объект имеет только одного владельца, но этот владелец может одалживать объект по ссылке в другие участки кода. При этом компилятор проверяет, что время жизни скоупа, одолжившего объект, не больше, чем время жизни владельца этого объекта.
Давайте рассмотрим такой код:
// Функция принимает две ссылки на строки и возвращает ту ссылку,
// которая указывает на более длинную строку.
fn take_longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}
fn main() {
let l = take_longest("aaa", "bbbb");
}Попытка скомпилировать этот код провалится с ошибкой:
error[E0106]: missing lifetime specifier
help: this function’s return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
Эта ошибка говорит, что компилятор не уверен в том, как соотносятся между собой время жизни владельца x, время жизни владельца y и время жизни переменной, в которую будет присвоен результат функции.
Чтобы стало понятнее, давайте взглянем на такой вариант использования функции take_longest:
let s1 = String::from("aaa");
let longest;
{
let s2 = String::from("bbbb");
longest = take_longest(s1.as_str(), s2.as_str());
}Как мы видим, при таком сценарии, ссылка на строку, принадлежащую переменной s2, будет записана в переменную longest. Проблема в том, что переменная longest принадлежит скоупу, который “живёт” дольше, чем скоуп в который входит s2. А как мы сказали выше, компилятор проверяет, что ссылка на объект не “живёт” дольше, чем переменная, владеющая этим объектом.
Для решения этой проблемы необходимо явно указать, как должны соотноситься между собой время жизни владельцев объектов, на которые ссылаются аргументы функции, и время жизни переменной, в которую будет записан результат функции.
Такие отношения времени жизни указывают при помощи лайфтаймов (lifetime).
fn take_longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}Здесь в заголовке функции take_longest<'a> мы объявляем некий относительный лайфтайм 'a. Далее в каждой ссылке после знака & мы указываем, к какому лайфтайму принадлежит ссылка.
Запись лайфтаймов в заголовке функции take_longest можно прочитать так:
Cуществует некий лайфтайм
'aпроизвольной длины, который не короче времени жизни функцииtake_longest. Владельцы объектов, на которые ссылаютсяxиy, должны принадлежать к одному скоупу. А время жизни переменной, принимающей результат функции, не должно превышать время жизни этого скоупа.
После того, как мы задали лайфтаймы, следующая попытка использования функции take_longest приведёт к ошибке компиляции.
fn main() {
let s1 = String::from("aaa");
let longest;
{
let s2 = String::from("bbbb");
longest = take_longest(s1.as_str(), s2.as_str()); // does not live long enough
}
println!("The longest string is {}", longest);
}’static лайфтайм
В Rust существует один “глобальный” лайфтайм — 'static. Принадлежность к этому лайфтайму означает, что время жизни объекта продлится от минимум текущего момента и до конца работы программы.
Например, константная ссылка на строковый литерал имеет лайфтайм 'static.
const text: &'static str = "some string";
fn main() {
println!("{text}");
}Сложности работы с лайфтаймами
Как правило, для тех, кто начинает изучать Rust, именно лайфтаймы становятся наиболее сложным моментом. Поэтому если на первых порах вы испытываете сложности с проставлением лайфтаймов, то рекомендуется не заморачиваться со сложными связями между ссылками, а просто использовать .clone() для получения копии объекта.
Позднее, когда вы лучше освоитесь с языком, можно будет углубиться в лайфтаймы отдельно.
Декларативные макросы
В Rust есть два основных вида макросов:
-
Декларативные макросы. Эти макросы обрабатываются после того, как исходный текст программы преобразован в AST (абстрактное синтаксическое дерево). Они манипулируют AST-узлами, что делает их простыми в написании, при этом довольно безопасными.
По сути, декларативные макросы — это функции, которые выполняются на этапе компиляции, и манипулируют не данными, а узлами AST. -
Процедурные макросы. Эти макросы принимают на вход последовательность токенов и выдают на выход тоже последовательность токенов. То есть они отрабатывают до лексического разбора текста программы, поэтому позволяют буквально создать другой язык внутри программы на Rust. Мы не будем изучать процедурные макросы в рамках этой книги, так как они сложны, и обычная бэкенд разработка не подразумевает создание новых процедурных макросов.
Наш первый декларативный макрос
Декларативные макросы объявляются при помощи аннотации #[macro_export], после которой следует описание макроса на специальном Schema-подобном синтаксисе.
#[macro_export]
macro_rules! имя_макроса {
шаблон_1 => { подстановка 1 };
шаблон_2 => { подстановка 2 };
...
шаблон_N => { подстановка N }
}
Для начала, давайте рассмотрим простейший макрос, который суммирует два числа:
#[macro_export]
macro_rules! sum_nums { // объявляем макрос с именем sum_nums
( $x:expr, $y:expr ) => { $x + $y }
}
fn main() {
let res = sum_nums!(1, 2); // вызываем макрос
println!("Sum is: {}", res);
}При компиляции программы вызов макроса будет “раскрыт” (expanded) в следующее:
fn main() {
let res = 1 + 2;
println!("Sum is: {}", res);
}Как видно, компилятор просто заменил вызов макроса на сгенерированный им Rust код и дальше продолжил компиляцию.
Tip
Посмотреть, в какие выражения раскрывается вызов макроса, можно с помощью утилиты cargo expand.
Теперь давайте подробнее разберём объявление макроса из нашего примера.
#[macro_export]
macro_rules! sum_nums {
( $x:expr, $y:expr ) => { $x + $y }
}Здесь ( $x:expr, $y:expr ) — шаблон для того, что мы ожидаем в качестве аргумента макроса. Синтаксис аргументов шаблона имеет вид: $имя_аргумента : тип_аргумента.
( $x:expr, $y:expr ) означает, что мы ожидаем два аргумента, каждый из которых должен быть корректным выражением на языке Rust (тип expr означает выражение — expression).
Именно контроль типов аргументов делает декларативные макросы такими удобными и безопасными. Например, мы можем вызвать этот макрос для любых корректных выражений:
#![allow(unused)]
fn main() {
sum_nums!(1 + 1, 2 + 2); // => 1 + 1 + 2 + 2
sum_nums!({ 1 + 1 }, { 2 + 2 }) // => { 1 + 1 } + { 2 + 2 }
sum_nums!(if 5 > 4 { 1 } else { -1 }, 9); // => if 5 > 4 { 1 } else { -1 } + 9
}Типы аргументов макросов
Кроме выражений, макросы могут различать целый ряд конструкций на Rust. Ниже приведён полный список допустимых типов аргументов для макросов. Со многими мы пока что не знакомы, поэтому не стоит заострять на них своё внимание. Цель этой главы не научиться писать макросы, а разобраться с ними до того уровня, который позволит комфортно ими пользоваться.
| Фрагмент | Сопоставляется с | после может быть |
|---|---|---|
expr | Выражение на Rust: 2 + 2, "aaa", x.len() | =>, ; |
stmt | Инструкция (то что до точки с запятой) | =>, ; |
ty | Тип данных: String, Vec<u8>, (&str, bool) | =>, = |
path | Путь: crate::module, ::std::sync::mpsc | =>, = |
pat | Деструктурирующий шаблон: _, Some(ref x) | =>, = |
item | Артикул: struct Point {x: f64, y: f64}, mod mymod; | что угодно |
block | Блок кода / скоуп: { s+= "ok"; true } | что угодно |
meta | Тело атрибута: inline, derive(Copy,Clone), doc="3d models." | что угодно |
ident | Идентификатор: std, Json, my_var | что угодно |
tt | Дерево лексем: ;, >=, {}, [0 1 (+ 0 1)] | что угодно |
literal | Литерал: 5, 5u32, 1.0, "Hello" | |
vis | Visibility qualifier: pub, pub (crate) |
Как видите, благодаря системе типов для аргументов макросы в Rust куда безопаснее, чем в C.
Также при неправильном использовании макроса, мы получим осмысленную ошибку компиляции именно для макроса, а не для некорректно-сгенерированного макросом кода, что обычно происходит в C.
Переменное число аргументов
В Rust отсутствуют функции с переменным числом аргументов, однако это ограничение компенсируется макросами.
Давайте рассмотрим макрос, который принимает произвольное количество числовых литералов и конструирует их сумму:
#[macro_export]
macro_rules! sum_nums {
() => { 0 };
( $first:literal $(, $rest:literal )* ) => {
$first $( + $rest )*
};
}
fn main() {
let res = sum_nums!(1, 2, 3, 4, 5);
println!("Sum is: {}", res); // Sum is: 15
}В этом макросе у нас два шаблона.
С первым шаблоном () => { 0 } всё просто: он обрабатывает случай, если в вызов макроса не было передано ни одного значения. В этом случае мы просто возвращаем 0 (в данном примере мы решили, что сумма никаких аргументов равна нулю).
Второй шаблон ожидает как минимум один аргумент, который будет привязан к имени $first. Далее может следовать произвольное количество чисел предварённых запятой, и вся эта последовательность будет привязана к имени $( $rest )*. Причём сама запятая будет отброшена, так как она не привязывается к какому-то имени аргумента.
Результатом применения этого шаблона будет сначала литерал, привязанный к $first, а затем все элементы последовательности, привязанные к ${$rest}*. Причём перед каждым элементом мы добавляем знак +.
Таким образом вызов sum_nums!(1, 2, 3, 4, 5) превращается в 1 + 2 + 3 + 4 + 5.
Этот макрос можно переписать более простым способом:
#![allow(unused)]
fn main() {
#[macro_export]
macro_rules! sum_nums {
( $( $rest:expr ),* ) => { 0 $( + $rest )* }
}
}Здесь мы просто воспользовались тем, что сложение любого числа с нулём даёт это же число. Поэтому мы привязываем все аргументы макроса к $( $rest )*, а в теле шаблона мы складываем 0 со всеми аргументами макроса.
sum_nums!(1,); // 0 + 1
sum_nums!(1, 2, 3); // 0 + 1 + 2 + 3
sum_nums!(); // 0Скобки
Как вы могли заметить, мы вызываем наш макрос используя круглые скобки: sum_nums(1,2). При этом макрос vec! мы вызываем с использованием квадратных скобок. В чём же разница?
На самом деле и наш макрос, и vec! можно вызывать с любыми скобками:
sum_nums!(1, 2);
sum_nums![1, 2];
sum_nums!{1, 2};
vec!(1, 2, 3);
vec![1, 2, 3];
vec!{1, 2, 3};Какой вариант кажется выразительнее, тот и используйте.
Единственное отличие заключается в необходимости ставить ; после вызова макроса. Если макрос используется для генерации функции или структуры, то после вызова макроса в варианте с фигурными скобками ; ставить не надо.
// Макрос, который создаёт пустую функцию с заданным именем
#[macro_export]
macro_rules! make_empty_func {
($func_name:ident) => {
fn $func_name() {}
}
}
make_empty_func!(function_1); // Нужна точка с запятой после вызова макроса
make_empty_func!{function_2}
fn main() {
function_1();
function_2();
}Макрос vec!
Теперь, когда мы познакомились с декларативными макросами, становится понятно, почему vec![] оформлен именно в виде макроса, а не функции: функции не поддерживают переменное число аргументов.
Реальная имплементация макроса vec![] такова, что вызов vec![1, 2, 3] раскрывается в <[_]>::into_vec(::alloc::boxed::box_new([1, 2, 3])) (и мы пока что не готовы разбирать что это означает). Однако, в учебных целях, давайте напишем свою, более простую реализацию — классический учебный макрос vec2!.
Код макроса:
#![allow(unused)]
fn main() {
#[macro_export]
macro_rules! vec2 {
() => { Vec::new() };
( $( $x:expr),* ) => {
{
let mut _temp = Vec::new();
$( _temp.push($x); )*
_temp
}
}
}
}Код вызова макроса:
|
Такой код вызова |
раскрывается в
|
Указатели
unsafe
В языке Rust имеются указатели, которые работают практически так же, как и в C. Но, как мы сказали в самом начале книги, работа с указателями запрещена в безопасном Rust. Именно поэтому в этой главе мы активно будем использовать unsafe.
В главе про Статические переменные мы уже видели unsafe блок:
#![allow(unused)]
fn main() {
unsafe {
код
}
}Внутри такого блока можно использовать небезопасные операции, включая работу с указателями.
Также можно пометить целую функцию ключевым словом unsafe.
#![allow(unused)]
fn main() {
unsafe fn функция() {
...
}
}В таком случае всё тело функции становится unsafe блоком. Причём такую unsafe функцию можно вызывать только либо из unsafe блока, либо из другой unsafe функции.
Работа с указателями
Как и в C, в Rust указатель является переменной, которая хранит адрес в памяти. При этом на уровне исходного кода программы у указателя имеется тип, представляющий информацию о типе значения, чей адрес хранится в указателе.
Тип указателя получается путем добавления приставки *const (для немутабельного) или *mut (для мутабельного указателя) перед тем типом, на чьё значения ссылается указатель.
Например, если переменная имеет тип i32, то немутабельный указатель на неё будет иметь тип *const i32.
#![allow(unused)]
fn main() {
let p1: *const i32; // немутабельный указатель на i32
let p2: *mut i32; // мутабельный указатель на i32
let p3: *mut String; // мутабельный указатель на строку
}Есть несколько способов получить указатель на объект:
1) Преобразованием из ссылки
#![allow(unused)]
fn main() {
let mut v: i32 = 5;
let const_ptr: *const i32 = &v as *const i32;
let mut_ptr: *mut i32 = &mut v as *mut i32;
}2) При помощи &raw (пришёл на смену макросам addr_of и addr_of_mut).
#![allow(unused)]
fn main() {
let mut v: i32 = 5;
let const_ptr: *const i32 = &raw const v;
let mut_ptr: *mut i32 = &raw mut v;
}3) Макросы addr_of и addr_of_mut (более старый вариант).
#![allow(unused)]
fn main() {
let mut v: i32 = 5;
let const_ptr: *const i32 = std::ptr::addr_of!(v);
let mut_ptr: *mut i32 = std::ptr::addr_of_mut!(v);
}Для того, чтобы разыменовать указатель (обратиться к значению по адресу), как и в C, используется оператор *.
Рассмотрим простой пример.
fn main() {
let a = 5;
let ptr = (&a) as *const i32; // берём ссылку и преобразуём её в указатель
unsafe {
// разыменовываем указатель, чтобы получить значение переменной
println!("{}", *ptr); // 5
}
}Приведение ссылки к указателю является безопасной операцией и может выполняться вне блока unsafe. Но разыменовывание указателя или преобразование указателя в ссылку требуют unsafe.
Обход ограничения ссылок
Напомним, что в Rust в каждой точке программы на любой объект мы можем иметь либо одну мутабельную ссылку, либо сколько угодно немутабельных. В подавляющем большинстве ситуаций, особенно при написании бэкендов, это ограничение никак не мешает. Однако при написании структур данных или алгоритмов часто может понадобиться иметь более одной мутабельной ссылки на один и тот же объект.
Например, в двунаправленном списке нам одновременно нужны две мутабельные ссылки на одни и те же элементы: одна ссылка со стороны головы списка, другая с хвоста.

Другой пример — сортировка слиянием (merge sort), которая подразумевает разделение исходной последовательности на участки, каждый из которых сортируется отдельно, а следовательно, должен иметь свою мутабельную ссылку.
unsafe блок не позволяет напрямую нарушить правило безопасности ссылок, однако unsafe позволяет создать дополнительную ссылку через промежуточный указатель:
мутабельная ссылка → указатель → еще одна мутабельная ссылка.
fn main() {
let mut a = 5;
unsafe {
let r1: &mut i32 = &mut a; // первая мутабельная ссылка
let ptr: *mut i32 = r1 as *mut i32; // мутабельный указатель
let r2: &mut i32 = ptr.as_mut().unwrap(); // указатель во вторую ссылку
inc(r1);
inc(r2);
}
println!("{a}"); // 7
}
fn inc(a: &mut i32) {
*a = *a + 1;
}Разумеется, этот приём можно использовать только при крайней необходимости. Также настоятельно рекомендуется:
- хорошо покрывать тестами код, использующий unsafe
- осуществлять диагностику кода при помощи Miri — утилиты для поиска проблем в unsafe коде
Структуры
Одним из представителей составных типов в Rust являются структуры.
Структура — именованный набор полей различного типа, который составляет новый тип данных.
Синтаксис объявления структуры следующий:
struct ИмяСтруктуры {
поле_1: Тип1,
поле_2: Тип2,
...
поле_N: ТипN,
}Заметьте, что после последнего поля структуры можно ставить запятую (так же, как и после последнего аргумента при объявлении функции).
Поля структуры, как и переменные, должны именоваться в соответствии со змеиной нотацией. Имена самих структур должны следовать паскалевской нотации (Pascal case): имя начинается с заглавной буквы, и если в названии присутствует несколько слов, то каждое слово также начинается с заглавной буквы. Например: User, MainAddress, DatabaseConnection.
Пример структуры, которая хранит имя и фамилию человека:
#![allow(unused)]
fn main() {
struct Person {
first_name: String,
last_name: String,
}
}Синтаксис создания экземпляра структуры:
let переменная = ИмяСтруктуры { поле_1: значение_1, ..., поле_N: значение_N};Например:
let person = Person {
first_name: String::from("John"),
last_name: String::from("Doe"),
};Доступ к полю структуры осуществляется при помощи точки: структура.поле.
my_struct.field_1
Пример создания и использования структуры:
struct Person {
first_name: String,
last_name: String,
}
fn get_full_name(p: &Person) -> String {
format!("{} {}", p.first_name, p.last_name)
}
fn main() {
let p = Person {
first_name: "John".to_string(),
last_name: "Doe".to_string()
};
let full_name = get_full_name(&p);
println!("{}", full_name); // "John Doe"
}Если мы инициализируем поле структуры значением из переменной, чьё имя совпадает с именем этого поля, то вместо имя_поля: имя_переменной можно просто указать переменную.
#![allow(unused)]
fn main() {
let first_name = String::from("John");
let person = Person {
first_name,
last_name: String::from("Doe"),
};
}Чтобы иметь возможность изменять значения полей у переменной типа структуры, вся переменная должна быть объявлена как мутабельная.
fn main() {
let mut p = Person {
first_name: "John".to_string(),
last_name: "Doe".to_string()
};
p.first_name = "Theodor".to_string();
}Создание одного экземпляра из другого
Если мы хотим создать объект структуры из другого объекта этой же структуры путем изменения значения некоторых полей, то для такой ситуации имеется специальный синтаксис:
let новый_объект = Структура {
поле1: новое значение 1,
поле2: новое значение 2,
..старый_объект
};Пример:
struct Person {
first_name: String,
last_name: String,
}
fn main() {
let p1 = Person {
first_name: "John".to_string(),
last_name: "Doe".to_string()
};
let p2 = Person { first_name: "Robert".to_string(), ..p1};
println!("{} {}", p2.first_name, p2.last_name); // Robert Doe
}Методы
В отличие от традиционных ООП языков, где методы объявляются в теле класса, в Rust методы структуры объявляются отдельно от неё.
Синтаксис:
impl ИмяСтруктуры {
// метод, который НЕ меняет вызывающий объект
fn метод_1(&self, аргумент_1: Тип1, …, аргумент_N: ТипN) -> ТипРезультата {
...
}
// метод, который меняет вызывающий объект
fn метод_2(&mut self, аргумент_1: Тип1, …, аргумент_N: ТипN) -> ТипРезультата {
...
}
// "статический" метод, вызываемый на структуре, а не на объекте структуры
fn метод_3(аргумент_1: Тип1, …, аргумент_N: ТипN) -> ТипРезультата {
...
}
}Аналогом ключевого слова this из C++ и Java является ключевое слово self, которое необходимо явно передавать в качестве первого аргумента метода.
- Если метод не меняет состояние объекта, на котором он вызван, то self можно передавать по немутабельной ссылке —
&self. - Если же методу необходимо изменять хотя бы одно из полей структуры, то self необходимо передавать по мутабельной ссылке —
&mut self. - В редких случаях, когда метод должен забрать во владение объект, на котором он был вызван, self необходимо передавать по значению —
self.
Пример:
struct Person {
first_name: String,
last_name: String,
age: u32
}
impl Person {
fn new(first: &str, last: &str) -> Person {
Person {
first_name: first.to_string(),
last_name: last.to_string(),
age: 0
}
}
fn change_age(&mut self, new_age: u32) {
self.age = new_age;
}
fn introduce(&self) -> String {
format!("{} {} is {} years old", self.first_name, self.last_name, self.age)
}
}
fn main() {
let mut p = Person::new("John", "Doe");
p.change_age(25);
println!("{}", p.introduce());
}Кортежные структуры (tuple structs)
В дополнение к традиционным структурам, которые являются коллекцией именованных полей, Rust предлагает так называемые кортежные структуры, где поля идентифицируются не именем, а позицией.
Синтаксис:
struct Имя(Тип1, Тип2, …, ТипN);Пример:
/// Представляет цвет, закодированный RGB каналами
struct RGB (u8, u8, u8);
impl RGB {
/// Упаковывает все 3 канала в одно 4-байтное число
fn as_u32(&self) -> u32 {
((self.0 as u32) << 16)
+ ((self.1 as u32) << 8)
+ (self.2 as u32)
}
}
fn main() {
let mut color: RGB = RGB(255, 0, 0); // красный цвет
println!("Red channel: {}", color.0); // Red канал: 255
color.1 = 255; // Выставляет зелёный канал в 255
// кортежную структуру можно разложить на составляющие
// так же, как и обычный кортеж
let RGB(r, g, b) = color;
println!("R={r}, G={g}, B={b}"); // R=255, G=255, B=0
println!("As number: {}", color.as_u32());
}Как видим, кортежная структура — это фактически обычный кортеж, только с осмысленным именем и возможностью добавить к нему дополнительные методы.
Структура-синглтон
В Rust имеется возможность создать структуру, в которой нет полей. Например:
#![allow(unused)]
fn main() {
struct Universe;
}Очевидно, что для такой структуры возможен лишь один вариант объекта, поэтому такая структура называется синглтоном. Объект синглтон структуры ведёт себя так же, как и объект обычной структуры с полями.
struct Universe;
impl Universe {
fn includes(&self, p: &Planet) -> bool {
true
}
}
struct Planet {
name: String
}
fn main() {
let universe = Universe;
let earth = Planet { name: "Earth".to_string() };
println!("{}", universe.includes(&earth)); // true
}Практическое применение таких структур станет понятнее после прочтения главы Трэйты.
Лайфтаймы у структур
В главе Лайфтаймы мы узнали, что такое лайфтаймы в целом и как задавать их для функций. Теперь давайте разберёмся с лайфтаймами для структур.
Если у структуры есть поле, в котором хранится ссылка, то для этой ссылки необходимо указать лайфтайм. Это нужно для того, чтобы компилятор мог сопоставить время жизни поля-ссылки и время жизни объекта, ссылка на который хранится в поле структуры.
Рассмотрим пример: у нас будет строка String, которая хранит имя и фамилию, разделённые пробелом, и мы сделаем структуру с двумя полями:
- ссылка на часть строки, где хранится имя
- ссылка на часть строки, где хранится фамилия
#[derive(Debug)]
struct NameComponents<'a> {
first_name: &'a str,
last_name: &'a str,
}
fn main() {
let full_name = "John Doe".to_string();
let space_position = full_name.find(" ").unwrap();
let components = NameComponents {
first_name: &full_name[0..space_position],
last_name: &full_name[space_position + 1 ..],
};
println!("{components:?}");
// NameComponents { first_name: "John", last_name: "Doe" }
}Благодаря лайфтайму компилятор сможет проконтролировать, что объект структуры NameComponents не “переживёт” строку, на которую ссылаются его поля-ссылки. Например, такой вариант не скомпилируется:
fn main() {
let components;
{
let full_name = "John Doe".to_string();
let space_position = full_name.find(" ").unwrap();
// Error: `full_name` does not live long enough
components = NameComponents {
first_name: &full_name[0..space_position],
last_name: &full_name[space_position + 1 ..],
};
}
println!("{components:?}");
}Лэйаут в памяти
Warning
Если вы плохо знакомы с архитектурой компьютера и плохо понимаете, как данные располагаются на стеке, то этот раздел, скорее всего, покажется непонятным. В таком случае не стоит заострять на нём внимание, так как эта информация не пригодится при разработке back-end приложений на Rust. Однако в будущем настоятельно рекомендуется разобраться с этой темой.
Теперь давайте разберёмся, как экземпляры структур располагаются в оперативной памяти.
Note
Результаты нижеприведённых примеров получены на x86_64 процессоре и версии Rust 1.92
Рассмотрим пример: воспользуемся стандартной функцией size_of, которая возвращает размер типа в байтах.
struct MyStruct {
a: i64,
b: i32,
}
fn main() {
println!("Size = {}", std::mem::size_of::<MyStruct>()); // Size = 16
}Как так получается, что структура, состоящая из полей, чей размер соответственно 8 и 4 байта, занимает 16 байт?
Дело в том, что компилятор применяет так называемое “выравнивание”, т.е. располагает поля так, чтобы процессор мог адресовать их за одну операцию считывания или записи.
Note
Процессоры семейства x86_64 имеют регистры размером 8 байт. При операции чтения процессор может адресовать только блоки памяти, чей адрес кратен 8. Например, считать в регистр можно блоки ячеек по адресам 0-7, или 8-15, или 16-23 и т.д. Процессор не может запросить ячейки в диапазоне 4-11 или, тем более, 4-7.
Поэтому когда необходимо вычитать значение, чьё начало расположено по адресу, не кратному 8 (например, 4-11), то процессору приходится считывать куски из смежных блоков (т.е. 0-7 и 8-16), далее битовыми операциями “отрезать” от них нужную часть и “склеивать” воедино. Все эти операции занимают лишние машинные такты. Поэтому целесообразнее выровнять значения в памяти так, чтобы значения можно было считывать за одну операцию. Пусть платой за это и станет перерасход памяти. Получившиеся “пробелы” в памяти называют паддингами (padding).
Давайте посмотрим, по каким адресам располагаются поля a и b. Для этого мы получим указатель на каждое из полей, а потом воспользуемся методом addr(), который возвращает числовое значение адреса указателя.
struct MyStruct {
a: i32,
b: i64,
}
fn main() {
println!("Size = {}", std::mem::size_of::<MyStruct>()); // Size = 16
let s = MyStruct { a: 1, b: 2 };
println!("a: {}", ((&s.a) as *const i32).addr()); // a: 140731421349072
println!("b: {}", ((&s.b) as *const i64).addr()); // b: 140731421349064
}Оба адреса 140731421349072 и 140731421349064 кратны 8.
Note
Обычно для распечатки адреса используется форматирующая последовательность
{:p}макросаprintln!, но мы просто хотели явно продемонстрировать, каким образом получается адрес переменной.
Теперь давайте посмотрим как располагаются в памяти массивы структур:
struct MyStruct {
a: i32,
b: i64,
}
fn main() {
let arr = [
MyStruct { a: 1, b: 2 },
MyStruct { a: 3, b: 4 },
MyStruct { a: 5, b: 6 }
];
println!("arr[0].a: {:p}", &arr[0].a); // arr[0].a: 0x7ffdc124d970
println!("arr[0].b: {:p}", &arr[0].b); // arr[0].b: 0x7ffdc124d968
println!("arr[1].a: {:p}", &arr[1].a); // arr[1].a: 0x7ffdc124d980
println!("arr[1].b: {:p}", &arr[1].b); // arr[1].b: 0x7ffdc124d978
println!("arr[2].a: {:p}", &arr[2].a); // arr[2].a: 0x7ffdc124d990
println!("arr[2].b: {:p}", &arr[2].b); // arr[2].b: 0x7ffdc124d988
}В памяти это выглядит так (здесь мы используем представление адресов в шестнадцатеричном формате):

Здесь хорошо видны как выравнивание, так и паддинги.
Также мы видим, что компилятор поменял местами поля a и b. Да, Rust не гарантирует, что поля структуры в памяти будут иметь такой же порядок, как и в коде объявления структуры.
Если необходимо, чтобы компилятор располагал поля в памяти в том же порядке, что и в объявлении структуры (обычно это нужно при вызове функций из библиотек, написанных на других языках), то структуру следует пометить аннотацией #[repr(C)].
#![allow(unused)]
fn main() {
#[repr(C)]
struct MyStruct {
a: i32,
b: i64,
}
}Эта аннотация указывает, что структура должна иметь представление, совместимое с представлением структур в языке C, где порядок полей структуры в памяти должен соответствовать порядку полей в коде объявления структуры.
Модули
Во избежание конфликтов имён, а также для логического структурирования кода в программах на Rust принято группировать типы данных и функции в модули.
Tip
Модули в какой-то мере являются аналогами пространств имен из C++ или пакетов из Java.
Имеется несколько способов создать модуль.
Способ 1: блок mod { … }
Модуль можно объявить прямо в main.rs при помощи ключевого слова mod.
mod имя_модуля {
содержимое
}Далее, чтобы обратиться к функции или структуре из модуля, используется синтаксис:
модуль::имя
Рассмотрим пример: решения конфликта имён при помощи модулей.
Файл main.rs:
mod a {
pub fn get_num() -> i32 {
1
}
}
mod b {
pub fn get_num() -> i32 {
2
}
}
fn main() {
println!("{}", a::get_num()); // 1
println!("{}", b::get_num()); // 2
}Обратите внимание, что перед объявлением функции стоит модификатор видимости pub (public). Он указывает, что функция может быть использована “внешним” кодом. По умолчанию всё содержимое модуля является приватным и может быть использовано только внутри этого модуля.
mod my_module {
pub fn get_num() -> i32 { // видима за пределами модуля
get_5()
}
fn get_5() -> i32 { // видима только внутри модуля
5
}
}
fn main() {
println!("{}", my_module::get_num()); // 5
}Как правило, блок mod { ... } используют:
- для решения конфликта имён
- для вынесения части кода в блок (модуль), который компилируется только при выполнении некого условия
Способ 2: другой *.rs файл
Если в той же директории, где находится файл main.rs, создать другой файл с расширением *.rs, то этот файл можно будет подключить как модуль при помощи ключевого слова mod.
mod имя_файла_без_rs;Например, допустим, у нас имеются такие файлы:
main.rs:mod my_module; fn main() { println!("{}", my_module::get_num()); }my_module.rs:#![allow(unused)] fn main() { pub fn get_num() -> i32 { 5 } }
Скомпилируем и запустим
$ rustc main.rs
$ ./main
5
Note
Сильно упрощая, можно сказать, что при компиляции файла
main.rsвместо выраженияmod my_moduleпомещается содержимое файлаmy_module.rsтак, как если бы оно изначально находилось там и было просто заключено в блокmod my_module { ... }.mod my_module { pub fn get_num() -> i32 { 5 } } fn main() { println!("{}", my_module::get_num()); }
Чтобы не писать полное имя функции с указанием модуля, её можно импортировать при помощи директивы use.
mod my_module;
use my_module::get_num;
fn main() {
println!("{}", get_num());
}Способ создания модуля в виде отдельного *.rs файла подходит для случаев, когда весь код модуля можно поместить в один файл.
Способ 3: директория и mod.rs
Если функциональность модуля хорошо гранулирована и может быть разделена на несколько подмодулей, то модуль создают не как отдельный файл, а как отдельный каталог, в котором есть корневой файл модуля — mod.rs и другие *.rs файлы, которые служат в качестве под-модулей.
Для примера рассмотрим тривиальный модуль с арифметическими операциями.
src/
├── main.rs <- главный файл программы
└── my_math/ <- папка модуля
└── mod.rs <- корневой файл модуля
├── add.rs <- здесь функция сложения
└── mul.rs <- здесь функция умножения
Файлы программы:
-
Файл
my_math/mod.rs:pub mod add; // подключаем add.rs в модуль my_math pub mod mul; // подключаем mul.rs в модуль my_math -
Файл
my_math/add.rs:pub fn sum(a: i32, b: i32) -> i32 { a + b } -
Файл
my_math/add.rs:pub fn multiply(a: i32, b: i32) -> i32 { a * b } -
Файл
main.rs:mod my_math; use my_math::add::sum; use my_math::mul::multiply; fn main() { println!("2 + 3 = {}", sum(2, 3)); println!("2 * 3 = {}", multiply(2, 3)); }
Скомпилируем и запустим программу:
$ rustc main.rs
$ ./main
7
Note
Упрощая, можно сказать, что при компиляции
main.rs, компилятор также соберёт все файлы модулей воедино, словно изначально это был файл:mod my_math { pub mod add { pub fn sum(a: i32, b: i32) -> i32 { a + b } } pub mod mul { pub fn multiply(a: i32, b: i32) -> i32 { a + b } } } use my_math::add::sum; use my_math::mul::multiply; fn main() { println!("2 + 3 = {}", sum(2, 3)); println!("2 * 3 = {}", multiply(2, 3)); }
Трансляция и модули
Как мы уже сказали, когда мы создаём модули в виде отдельных файлов, нам не приходится компилировать их отдельно. Мы вызываем rustc только для файла main.rs, и все модули компилируются автоматически.
Сборку бинарного исполняемого файла можно проиллюстрировать так:

Для сравнения: в C++ каждый *.cpp файл компилируется в отдельный объектный файл, и только потом все объектные файлы линкуются в исполняемый бинарный файл.

Из-за того, что компилятор Rust “склеивает” main.rs и все входящие в него модули в один большой файл, который далее компилирует целиком, этот самый main.rs и все входящие в него модули называют крэйтом (crate — ящик). Представьте, словно все файлы “свалили” в один ящик (единицу трансляции) и подали на вход компилятору.
Понятие крэйта очень важно в экосистеме Rust. Мы подробнее поговорим про крэйты, и другие составляющие программ на Rust в главе Несколько исполняемых файлов.
Трэйты
Important
В русскоязычной литературе по Rust слово trait переводят по-разному: примесь, типаж. Мы будем использовать англицизм “трэйт”, потому что так говорят даже в русскоязычной среде при обсуждении языка Rust.
Трэйты служат для определения интерфейса взаимодействия с типом путём описания методов, которые должны у него присутствовать. Если для некого типа необходимо реализовать трэйт, то для этого типа нужно определить реализации всех методов, объявленных в трэйте.
Tip
Программисты на Java и C# могут провести параллели с интерфейсами. Для программистов на C++ самой близкой аналогией будет абстрактный класс.
Синтаксис объявления трэйта:
trait Имя {
fn метод_1(&self) -> Тип1;
...
fn метод_N(&self) -> ТипN;
}Синтаксис реализации трэйта для структуры:
impl Трэйт for Структура {
fn метод_1(&self) -> Тип1 { ... }
...
fn метод_N(&self) -> ТипN { ... }
}Пример:
// трэйт, который говорит о том, что тип реализующий его, умеет представляться
trait CanIntroduce {
// метод "представиться"
fn introduce(&self) -> String;
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn introduce(&self) -> String {
// Человек представляется называя своё имя
format!("Hello, I'm {}", self.name)
}
}
fn main() {
let person = Person { name: String::from("John") };
println!("{}", person.introduce ()); // Hello, I'm John
}Полиморфизм
Разумеется, трэйты не нужны просто для того, чтобы их реализовывать. Главное применение трэйтов — иметь возможность писать полиморфный код. То есть такой код, который взаимодействует с типами не напрямую, а через трэйт, который они реализуют. Например, чтобы иметь возможность создать функцию, которая в качестве аргумента принимает объект любого типа, реализующего необходимый трэйт.
В Rust существует два принципиально разных подхода к передаче аргументов на основе трейтов:
- Статическая диспетчеризация — когда тип аргумента указывается как
impl Трэйт - Динамическая диспетчеризация — когда тип аргумента указывается как
dyn Трэйт
Если вы программируете на C++, то, скорее всего, вы уже поняли, что это означает. В противном случае давайте рассмотрим каждый из этих двух типов.
Статическая диспетчеризация
Сначала мы рассмотрим синтаксис передачи аргументов со статической диспетчеризацией, а потом разберём, как этот механизм работает внутри.
Для того чтобы функция принимала аргумент по трэйту со статической диспетчеризацией, надо указать тип аргумента как impl Трэйт.
Рассмотрим на примере. Напишем функцию, которая принимает любой тип, реализующий трэйт CanIntroduce из примера выше, и печатает “представление” на консоль :
fn print_introduction(v: &impl CanIntroduce) {
// Всё что мы знаем о v: его тип реализует трэйт CanIntroduce
println!("Value says: {}", v.introduce());
}Разумеется, так как мы принимаем аргумент по его трэйту, единственное, что мы можем с ним делать — то, что объявлено в трэйте. Но это как раз то, что нам нужно.
Для того чтобы продемонстрировать, как эта функция может принимать аргументы разных типов, давайте в дополнение к структуре Person создадим еще структуру Dog и также реализуем для неё трэйт CanIntroduce.
struct Dog {
name: String
}
impl CanIntroduce for Dog {
fn introduce(&self) -> String {
// Вне зависимости от своего имени, собака может только погавкать
String::from("Waf-waf")
}
}Теперь посмотрим, как можно вызвать функцию print_introduction и для Person, и для Dog.
trait CanIntroduce {
fn introduce(&self) -> String;
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn introduce(&self) -> String {
format!("Hello, I'm {}", self.name)
}
}
struct Dog {
name: String
}
impl CanIntroduce for Dog {
fn introduce(&self) -> String {
// Вне зависимости от своего имени, собака может только погавкать
String::from("Waf-waf")
}
}
fn print_introduction(v: &impl CanIntroduce) {
// Всё что мы знаем о v: его тип реализует трэйт CanIntroduce
println!("Value says: {}", v.introduce());
}
fn main() {
let person = Person { name: String::from("John") };
let dog = Dog { name: String::from("Bark") };
print_introduction(&person); // Value says: Hello, I'm John
print_introduction(&dog); // Value says: Waf-waf
}Всё работает: мы написали полиморфную функцию, которая принимает аргумент любого типа, реализующего трэйт.
А теперь давайте поговорим о том, как это работает, и почему диспетчеризация называется статической.
Дело в том, что когда компилятор встречает использование функции, имеющей аргумент типа impl Трэйт, то он генерирует вариант этой функции для конкретного типа, с которым функция вызвана.
Note
Такой процесс генерации функции с конкретным типом вместо трэйта называется мономорфизацией.
То есть, найдя вызов функции print_introduction для Person, а потом для Dog, компилятор сгенерирует нечто наподобие следующего (разумеется, имена будут не такими):
fn print_introduction_$Person(v: &Person) {
println!("Value says: {}", v.introduce());
}
fn print_introduction_$Dog(v: &Dog) {
println!("Value says: {}", v.introduce());
}А далее компилятор изменит вызовы полиморфной функции print_introduction на вызовы конкретных вариантов:
fn main() {
let person = Person { name: String::from("John") };
let dog = Dog { name: String::from("Bark") };
print_introduction_$Person(&person);
print_introduction_$Dog(&dog);
}Таким образом, уже на этапе компиляции каждый из сгенерированных вариантов функции print_introduction будет знать, с каким именно конкретным типом он работает, а значит, ему будет известен адрес нужного метода introduce именно для того типа, с которым работает этот вариант print_introduction.

Адреса методов статичны (известны на момент сборки программы), поэтому диспетчеризация и называется статической.
Динамическая диспетчеризация
В противовес статической диспетчеризации существует и динамическая. На первый взгляд, различие в коде между статической диспетчеризацией и динамической — минимально: нужно просто заменить тип аргумента с impl Трэйт на dyn Трэйт. Однако разница в реализации очень существенна. Как и в прошлый раз, сначала мы разберём синтаксис, а потом уже внутреннее устройство.
Вот как будет выглядеть вариант print_introduction с динамической диспетчеризацией:
fn print_introduction(v: &dyn CanIntroduce) {
println!("Value says: {}", v.introduce());
}При этом вызовы этой функции для типов Person и Dog вообще не изменились:
trait CanIntroduce {
fn introduce(&self) -> String;
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn introduce(&self) -> String {
format!("Hello, I'm {}", self.name)
}
}
struct Dog {
name: String
}
impl CanIntroduce for Dog {
fn introduce(&self) -> String {
String::from("Waf-waf")
}
}
fn print_introduction(v: &dyn CanIntroduce) {
println!("Value says: {}", v.introduce());
}
fn main() {
let person = Person { name: String::from("John") };
let dog = Dog { name: String::from("Bark") };
print_introduction(&person); // Value says: Hello, I'm John
print_introduction(&dog); // Value says: Waf-waf
}Как мы уже сказали, разница кажется минимальной только внешне. Если при статической диспетчеризации компилятор генерирует столько вариантов функции, сколько имеется различных типов для которых функция вызывается, то при динамической диспетчеризации, функция всего одна.
Каким же тогда образом print_introduction понимает для какой реализации CanIntroduce она вызвана и какую реализацию метода introduce ей следует использовать? Дело в том, что аргумент &dyn CanIntroduce — это не просто ссылка на объект, переданный в качестве аргумента, это пара ссылок: первая — на сам объект, а вторая — на vtable (таблица виртуальных вызовов) для конкретного типа аргумента. В англоязычной литературе эту пару ссылок называют fat pointer — толстый указатель.
Когда компилятор видит в коде места, где к объекту конкретного типа обращаются посредством dyn Трэйт, то для этого типа он генерирует специальную таблицу vtable. В этой таблице хранятся имена методов, которые тип реализует для трэйта, и адреса реализаций этих методов в сегменте кода. Фактически, vtable является картотекой, которая хранит отображение имён методов из трэйта на реализации этих методов для конкретного типа.
Далее во всех местах вызова функции с dyn Трэйт аргументом компилятор генерирует код, который в качестве аргумента в функцию передаёт пару: адрес объекта-аргумента и адрес его vtable.
Внутрь реализации самой функции, которая принимает аргумент с динамической диспетчеризацией, компилятор вставляет код, который:
- по имени метода ищёт в таблице vtable адрес реализации этого метода
- вызывает этот метод

Объект типа dyn Трэйт называется трэйт объектом (trait object).
Tip
Не путайте:
dyn Трэйт(трэйт-объект) — значение неизвестного типа и неизвестного размера&dyn Трэйт(ссылка на трэйт-объект) — пара указателей: на значение и на vtableТо есть точно так же, как слайс-ссылка
&[]— это не просто адрес начала последовательности, а адрес + размер последовательности, так же и&dyn— это не просто адрес, а адрес значения + адрес vtable.
impl vs dyn
Подведём итог. Есть два способа обратиться к типу посредством трэйта, который он реализует:
impl Трэйт— заменяется на конкретный тип при компиляцииdyn Трэйт— заменяется на трэйт объект, который проксирует вызовы методов на реальный тип при помощи динамической диспетчеризации
Note
Если вы не знакомы с C++, детали динамической диспетчеризации, скорее всего, будут плохо понятны. Не пытайтесь понять всё досконально за раз, просто вернитесь к этой теме потом, после того как освоитесь с Rust на базовом уровне и будете готовы к более глубокому изучению.
На данном этапе мы еще не имеем достаточно знаний, чтобы рассмотреть все аспекты использования трэйт объектов, но пока что можем сказать следующее:
- Вызовы методов посредством статической диспетчеризации работают гораздо быстрее, потому что вызов осуществляется напрямую по адресу метода, в то время как при динамической диспетчеризации сначала нужно найти адрес метода в vtable.
- При компиляции
impl Трэйтпросто подменяется на конкретный тип, поэтому аргументы такого типа можно передавать как по ссылке&impl Трэйт, так и по значению —impl Трэйт. - В отличие от
impl Трэйт,dyn Трэйтнельзя передать по значению. Дело в том, что при компиляции функции в машинный код должен быть известен точный размер всех её аргументов. Но при динамической диспетчеризации конкретный тип аргумента не известен, а следовательно, неизвестен и его размер. Поэтому трэйт объекты всегда передаются либо по ссылке —&dyn Трэйт, либо через умный указательBox<dyn Трэйт>(о котором мы поговорим позже).
Реализация трэйта для “чужих” типов
В отличие от ООП языков, где методы класса определяются непосредственно в теле класса, в Rust методы структуры определяются за пределами тела структуры. Это даёт возможность реализовать свой трэйт для “чужих” структур (находящихся в других библиотеках).
trait CanIntroduce {
fn introduce(&self) -> String;
}
impl CanIntroduce for &str {
fn introduce(&self) -> String {
String::from("I am string slice")
}
}
impl CanIntroduce for i32 {
fn introduce(&self) -> String {
String::from("I am integer")
}
}
fn print_introduction(v: impl CanIntroduce) {
println!("Value says: {}", v.introduce());
}
fn main() {
print_introduction("a"); // Value says: I am string slice
print_introduction(5); // Value says: I am integer
}Однако в Rust существует правило “Orphan rule” (правило сирот), которое гласит:
Трэйт можно реализовать для типа только в том случае, если либо трэйт, либо тип (либо оба) принадлежит библиотеке в которой осуществляется реализация.
То есть, не смотря на то, что тип i32 принадлежит стандартной библиотеке, мы смогли реализовать для него трэйт CanIntroduce только потому, что трэйт CanIntroduce объявлен нами же в нашей программе. Мы не можем определить трэйт из “чужой” библиотеки для типа из “чужой” библиотеки. Либо трэйт, либо тип должен принадлежать нашему main.rs или его модулям.
В главе Newtype паттенр мы рассмотрим способ обхода ограничений Orphan rule.
Возврат трэйта из функции
Rust позволяет не только передавать аргументы посредством трэйта, но и возвращать трэйт из функции.
Принцип такой же, как и с передачей аргументов:
- если возвращаемый тип
impl Trait, то компилятор проведёт замену на конкретный тип - если возвращаемый тип
dyn Trait, то компилятор создаст трэйт объект
Например:
fn make_person() -> impl CanIntroduce {
Person { name: String::from("John") }
}Однако есть нюанс: поскольку компилятор просто заменяет impl Трэйт на конкретный тип, из такой функции нельзя возвращать два разных типа.
Рассмотрим пример:
trait CanIntroduce {
fn introduce(&self) -> String;
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn introduce(&self) -> String {
format!("Hello, I'm {}", self.name)
}
}
struct Dog {
name: String
}
impl CanIntroduce for Dog {
fn introduce(&self) -> String {
// Вне зависимости от своего имени, собака может только погавкать
String::from("Waf-waf")
}
}
fn make_someone(is_person: bool) -> impl CanIntroduce {
if is_person {
Person { name: String::from("John") }
} else {
Dog { name: String::from("Bark") }
}
}
fn main() {
let p = make_someone(true);
}Как мы знаем, impl Трэйт просто заменяется компилятором на конкретный тип. Поэтому, если возвращаемый тип impl CanIntroduce будет заменён, например, на Person, то возврат объекта типа Dog станет невозможным. И наоборот.
Возврат dyn Трэйт в этой ситуации работает прекрасно:
fn make_someone(is_person: bool) -> Box<dyn CanIntroduce> {
if is_person {
Box::new(Person { name: String::from("John") })
} else {
Box::new(Dog { name: String::from("Bark") })
}
}
fn main() {
let person = make_someone(true);
let dog = make_someone(false);
print_introduction(person.as_ref());
print_introduction(dog.as_ref());
}В этом примере присутствует тип, с которым мы пока еще не знакомы — Box. Фактически это просто безопасная обёртка над указателем. Конструктор Box::new(значение) переносит значение со стека в кучу и возвращает объект Box, внутри которого содержится указатель с адресом объекта в куче. Подробнее мы разберём Box в главе Умные указатели.
Tip
Если вы знакомы с C++, то можете считать, что
Box<T>— это то же самое, чтоstd::unique_ptr<T>
Главная причина, по которой мы используем Box<dyn Трэйт>, а не &dyn Трэйт, заключается в том, что мы не можем создать в функции объект на стеке, а потом вернуть ссылку на него. Ведь при выходе из функции её стэк-фрэйм будет очищен вместе со всеми находящимися в нём объектами, и ссылка на любой из этих объектов станет недействительной. Именно поэтому мы переносим объект в кучу и возвращаем из функции указатель (Box) на этот объект в куче.
Дефолтные имплементации методов
Методы в трэйте могут иметь реализации по умолчанию.
trait CanIntroduce {
fn say_name(&self) -> String;
fn introduce(&self) -> String { // реализация по умолчанию
format!("Hello, I am {}", self.say_name())
}
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn say_name(&self) -> String {
self.name.clone()
}
}
fn main() {
let person = Person { name: String::from("John") };
// Вызываем дефолтную реализацию метода introduce
println!("{}", person.introduce()); // Hello, I am John
}Методы с реализацией по умолчанию переопределяются так же, как и обычные методы трэйтов:
trait CanIntroduce {
fn say_name(&self) -> String;
fn introduce(&self) -> String { // реализация по умолчанию
format!("Hello, I am {}", self.say_name())
}
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn say_name(&self) -> String {
self.name.clone()
}
fn introduce(&self) -> String { // переопределяем
format!("Hi, I'am {}", self.say_name())
}
}
fn main() {
let person = Person { name: String::from("John") };
println!("{}", person.introduce());
}“Наследование” трэйта
В Rust один трэйт может “наследовать” другой трэйт.
trait A : B { ... } // Трэйт A "наследует" трэйт BНа практике это означает, что если мы хотим реализовать для нашего типа трэйт A, то мы обязательно должны реализовать и трэйт B для него.
Например:
trait HasName {
fn say_name(&self) -> String;
}
// Все кто реализуют CanIntroduce, должны реализовать и HasName
trait CanIntroduce : HasName {
fn introduce(&self) -> String;
}
struct Person {
name: String
}
impl CanIntroduce for Person {
fn introduce(&self) -> String {
format!("Hello, I am {}", self.say_name())
}
}
// Компилятор обяжет сделать реализацию для HasName
// после того как найдёт реализацию для CanIntroduce
impl HasName for Person {
fn say_name(&self) -> String {
self.name.clone()
}
}
fn main() {
let person = Person { name: String::from("John") };
println!("{}", person.introduce()); // Hello, I am John
}Ограничение несколькими трэйтами
Давайте посмотрим на передачу аргументов по impl Трэйт под другим углом. Когда мы указываем трэйт в качестве аргумента функции, то мы тем самым накладываем ограничение на типы, которые можно передавать в эту функцию.
Например, объявляя аргумент так:
#![allow(unused)]
fn main() {
fn print_introduction(v: impl CanIntroduce) { ... }
}мы накладываем ограничение, что функция может быть вызвана только с аргументом, чей тип реализует трэйт CanIntroduce. Но что, если нам нужно, чтобы аргумент реализовывал два трэйта? В таком случае надо просто перечислить необходимые трэйты через знак +.
#![allow(unused)]
fn main() {
trait CanIntroduce { ... }
trait HasJob { ... }
fn print_worker_introduction(v: &(impl CanIntroduce + HasJob)) {
}Важно сказать, что такой синтаксис для указания ограничения в виде нескольких трэйтов практически никогда не используется. Вместо него используется другой синтаксис, который мы рассмотрим в главе Генерики.
Self
Нередко в объявлении трэйта необходимо сослаться на конкретный тип, для которого будет реализован трэйт. Для этого используется ключевое слово Self (с заглавной буквы).
Например, создадим трэйт, который декларирует, что у типа должна быть функция-конструктор по умолчанию:
trait HasDefaultConstructor {
fn make_default() -> Self;
}Когда мы пишем этот трэйт, мы еще не знаем, какой тип будет возвращать функция make_default, так как он будет зависеть от типа, для которого мы реализуем этот трэйт. Поэтому в типе результата функции мы не можем указать конкретное имя типа. Именно здесь на помощь приходит Self.
Давайте теперь реализуем этот трэйт для типа Person из примеров выше:
trait HasDefaultConstructor {
fn make_default() -> Self;
}
struct Person {
name: String
}
impl HasDefaultConstructor for Person {
fn make_default() -> Self {
Person { name: "Anonymous".to_string() }
}
}
fn main() {
let p: Person = Person::make_default();
println!("Default name: {}", p.name);
}Здесь в реализации HasDefaultConstructor для Person в функции make_default мы указали тип результата как Self, но могли указать и Person. Эффект был одинаковым.
impl HasDefaultConstructor for Person {
fn make_default() -> Person { // Person вместо Self
Person { name: "Anonymous".to_string() }
}
}Требования к Трэйт-объектам
Note
Сейчас эта секция будет малопонятной. Её лучше перечитать после прохождения главы про Генерики.
Не для всех трэйтов можно создать трэйт объект. Чтобы компилятор мог сгенерировать трэйт-объект, т.е. dyn Трэйт, трэйт должен удовлетворять следующим требованиям:
-
Трэйт не должен содержать методов, которые возвращают
Selfили принимают аргумент типаSelf.#![allow(unused)] fn main() { trait A { fn f(&self, other: &Self) -> Self; } } -
Трэйт не должен содержать статических методов:
trait A { fn f() -> i32; } struct B {} impl A for B { fn f() -> i32 { 5 } } fn call_f(a: &dyn A) { println!("Do nothing"); } fn main() { let b = B {}; call_f(&b); } -
Трэйт не должен содержать методов, которые декларируют новый генерик-тип аргумент, не связанный с генерик-тип аргументом, заданным на уровне самого трэйта. О генериках мы поговорим в другой главе. Например, для такого трэйта нельзя создать трэйт-объект.
#![allow(unused)] fn main() { trait A { fn f<T>(); } } -
Трэйт не должен содержать ассоциированных типов (которые являются разновидностью генериков):
#![allow(unused)] fn main() { trait A { type X; } }
Если трэйт наследует другие трэйты, то все наследуемые трэйты также должны удовлетворять вышеприведённым условиям для преобразования в трэйт-объект.
unsafe trait
Если мы создаём трэйт, содержащий методы, которые предполагают unsafe операции, такие как работа с указателями, то трэйт следует объявить с ключевым словом unsafe.
#![allow(unused)]
fn main() {
unsafe trait MyTrait {
fn do_something_dangerous();
}
}Для реализации такого трэйта будет необходимо указать ключевое слово unsafe.
#![allow(unused)]
fn main() {
unsafe impl MyTrait for MyStruct {
fn do_something_dangerous() {
...
}
}
}Тот факт, что мы реализуем unsafe трэйт, не означает, что в методах мы обязательно используем unsafe блок. Unsafe трэйт может даже не содержать unsafe методов (как мы это увидим позже для трэйтов Send и Sync). Единственная цель, с которой трэйт помечается как unsafe — сделать акцент на потенциальной опасности трэйта в глазах того, кто будет реализовывать его для своих типов.
Автоматическая реализация трэйтов
В качестве вводной давайте рассмотрим следующий пример: мы попытаемся создать структуру для хранения координат точки в двухмерном пространстве и попробуем сравнить два экземпляра точки на равенство:
struct Point2D { x: i32, y: i32 }
fn main() {
let p1 = Point2D {x: 1, y: 1};
let p2 = Point2D {x: 1, y: 1};
println!("p1 = p2: {}", p1 == p2);
}При попытке скомпилировать этот код мы получим ошибку:
error[E0369]: binary operation `==` cannot be applied to type `Point2D`
--> src/my_module/num.rs:6:30
|
6 | println!("p1 = p2: {}", p1 == p2);
| -- ^^ -- Point2D
| |
| Point2D
Компилятор указывает, что для того чтобы иметь возможность сравнивать объекты на равенство, их тип должен реализовывать трэйт PartialEq, который предоставляет метод для сравнения двух экземпляров на равенство.
Note
Пусть вас не смущает, что трэйт называется “Partial Equals” (частичное равенство): он используется именно для сравнения на равенство, а эта самая “частичность” задействуется только для редких случаев. Например, при сравнении двух
f32, оба из которых равныNaN: спецификация IEEE-754 требует, чтобы результат сравнения двухNaNбыл ложным, несмотря на то, что они одинаковы.
Сам трэйт PartialEq имеет следующий вид (на самом деле он немного сложнее, но суть мы передали):
#![allow(unused)]
fn main() {
pub trait PartialEq {
fn eq(&self, other: &Self) -> bool;
fn ne(&self, other: &Self) -> bool { !self.eq(other) }
}
}Как мы видим, трэйт содержит два метода: eq (equal) и ne (not equal). Когда компилятор встречает сравнение двух объектов при помощи оператора ==, он подменяет использование оператора == на вызов метода eq. То есть вызов p1 == p2 будет заменён на p1.eq(p2). Аналогично, применение оператора != заменяется на вызов метода ne.
Таким образом, чтобы проверка на равенство работала для нашей структуры Point2D, мы должны реализовать для неё PartialEq:
struct Point2D { x: i32, y: i32 }
impl PartialEq for Point2D {
fn eq(&self, other: &Self) -> bool {
self.x == other.x && self.y == other.y
}
}
fn main() {
let p1 = Point2D {x: 1, y: 1};
let p2 = Point2D {x: 1, y: 1};
println!("p1 = p2: {}", p1 == p2);
}Теперь всё работает.
Если мы задумаемся о реализации метода eq для нашей точки, который заключается просто в сравнении всех полей, то заметим, что для подавляющего большинства структур, которые мы можем написать, сравнение так же будет заключаться просто в сравнении между собой всех соответствующих полей.
К счастью, в Rust есть специальный механизм, который позволяет генерировать вот такие наиболее частые реализации для трэйтов — аннотация derive.
derive
Если над нашей структурой мы “повесим” аннотацию #[derive(PartialEq)], то компилятор сам сгенерирует реализацию PartialEq для нашего типа. Автоматическая реализация метода eq просто сравнивает все соответствующие поля для объектов структуры, что нам и нужно.
#[derive(PartialEq)]
struct Point2D { x: i32, y: i32 }
fn main() {
let p1 = Point2D {x: 1, y: 1};
let p2 = Point2D {x: 1, y: 1};
println!("p1 = p2: {}", p1 == p2);
let p3 = Point2D {x: 0, y: 0};
let p4 = Point2D {x: 1, y: 1};
println!("p3 = p4: {}", p3 == p4);
}Как видите, такая реализация работает правильно, при этом наш код стал заметно короче и выразительнее.
Note
Посмотреть, какой код реализации генерируется на основании аннотации
derive, можно при помощи утилиты cargo expand.
Аннотации
Мы уже обсудили аннотацию derive, но пока что мы толком не знакомы с самими аннотациями.
Аннотация — это специальная пометка для компилятора, которой может быть отмечена структура, функция, модуль и т.д.
Аннотация имеет следующий синтаксис:
#[аннотация(аргументы аннотации)]
Когда компилятор встречает аннотацию, он обращается к соответствующему обработчику, который выполняет ту или иную кодогенерацию.
Соответственно, для аннотации derive в стандартной библиотеке Rust имеется специальный обработчик, который во время компиляции генерирует стандартную реализацию для тех или иных трейтов.
Кроме PartialEq, генерация стандартной реализации поддерживается для целого ряда других трэйтов из стандартной библиотеки, например:
- Hash — стандартный трэйт, предоставляющий метод для вычисления хеш-кода объекта.
- Debug — трэйт, который декларирует “отладочный” метод преобразования в строку. Именно он используется, когда мы распечатываем объект через
{:?}в вызовеprintln!. - Default — позволяет создавать значение по умолчанию для множества типов. Например:
0— для чисел,false— для булевого типа, пустая строка — для строк, и т.д.
трэйт Clone
Мы уже знаем, что благодаря концепции владения при присваивании объекта от одной переменной к другой этот объект перемещается.
Однако если мы хотим не перемещать объект, а скопировать, то нам на помощь придёт трэйт Clone, который предоставляет для этого метод clone(). Сам трэйт выглядит вот так:
trait Clone: Sized {
fn clone(&self) -> Self;
}Казалось бы, что в нём особенного? Мы и сами можем написать для нашего типа метод, который будет возвращать копию объекта. Например, так:
#[derive(Debug)]
struct Point2D { x: i32, y: i32 }
impl Point2D {
fn make_clone(&self) -> Point2D {
Point2D { x: self.x, y: self.y }
}
}
fn main() {
let p1 = Point2D { x: 1, y: 1};
let p2 = p1.make_clone();
println!("p1={:?}, p2={:?}", p1, p2);
// Напечатает: p1=Point2D { x: 1, y: 1 }, p2=Point2D { x: 1, y: 1 }
}Однако вся прелесть в том, что для Clone также можно сгенерировать реализацию просто путём добавления аннотации derive.
#[derive(Debug,Clone)]
struct Point2D { x: i32, y: i32 }
fn main() {
let p1 = Point2D { x: 1, y: 1};
let p2 = p1.clone();
println!("p1={:?}, p2={:?}", p1, p2);
// Напечатает: p1=Point2D { x: 1, y: 1 }, p2=Point2D { x: 1, y: 1 }
}Note
Автоматическая генерация — не единственная причина использовать трэйт
Clone. Как мы уже знаем из прошлой главы, полиморфные функции могут накладывать ограничения на то, какие трэйты должны быть реализованы типом аргумента. Клонирование является очень важной функциональностью, поэтому как в стандартной библиотеке, так и в сторонних библиотеках имеется великое множество функций, которые накладывают на свои аргументы ограничениеimpl Clone.
Разумеется, при необходимости ничто не мешает нам реализовать Clone для нашего типа вручную.
#[derive(Debug)]
struct Point2D { x: i32, y: i32 }
impl Clone for Point2D {
fn clone(&self) -> Point2D {
Point2D {x: self.x, y: self.y}
}
}
fn main() {
let p1 = Point2D { x: 1, y: 1};
let p2 = p1.clone();
println!("p1={:?}, p2={:?}", p1, p2);
}Реализация clone(), сгенерированная при помощи #[derive(Clone)], делает глубокую копию объекта, т.е. текущий объект и все вложенные. Именно поэтому, если мы хотим применить #[derive(Clone)] для нашей структуры, то типы всех полей этой структуры также должны реализовать трэйт Clone.
трэйт Copy
Из главы Владение мы знаем, что операция присваивания, перемещает только объекты составных типов, а значения примитивных типов просто копируются.
На самом деле, для того чтобы понять, нужно ли копировать объект или перемещать, компилятор проверяет, реализует ли этот тип трейт Copy.
trait Copy: Clone { }Как мы видим, этот трэйт наследует трэйт Clone, но не добавляет никаких новых методов. Такие трэйты называются маркерными, т.е. просто играют роль “пометки” для компилятора.
Если компилятор видит, что тип объекта, используемого в операции присваивания, реализует трэйт Copy, то вместо того, чтобы перемещать объект, он вызывает на нём метод .clone() и присваивает полученную копию.
Перепишем наш пример для структуры Point2D, добавив трэйт Copy в аннотацию derive.
#[derive(Debug,Clone,Copy)]
struct Point2D { x: i32, y: i32 }
fn main() {
let p1 = Point2D { x: 1, y: 1};
let p2 = p1; // При присваивании вызывается p1.clone()
println!("p1={:?}, p2={:?}", p1, p2);
// p1=Point2D { x: 1, y: 1 }, p2=Point2D { x: 1, y: 1 }
}Теперь при присваивании переменной p1 в переменную p2, перемещение владения не происходит. Вместо этого создаётся копия объекта из переменной p1 и присваивается переменной p2.
Деструктурирующее присваивание
В главе Кортежи мы познакомились со специальным синтаксисом для “разбиения” объекта кортежа на его составляющие.
#![allow(unused)]
fn main() {
let employee: (&str, i32, bool) = ("John Doe", 1980, true);
let (name, birth_year, is_active_employee) = employee;
}Такая операция “разбиения” объекта на составляющие называется деструктурирующим присваиванием.
Деструктурирующее присваивание доступно не только для кортежей, но также для массивов и структур. Рассмотрим несколько примеров.
Кортежи
С деструктурированием кортежей мы уже знакомы, однако давайте взглянем на более сложный пример с вложенным кортежем.
#![allow(unused)]
fn main() {
let tup: (i32,char,bool,(i32,i32,i32)) = (1, 'z', true, (7,7,7));
let (num, c, _, t) = tup;
println!("num={}, char={}, triplet={:?}", num, c, t);
}Здесь мы присвоили весь вложенный кортеж целиком в переменную t, однако мы можем деструктурировать и вложенный кортеж.
#![allow(unused)]
fn main() {
let tup: (i32,char,bool,(i32,i32,i32)) = (1, 'z', true, (7,8,9));
let (num, c, _, (d1, d2, d3)) = tup;
println!("num={num}, char={c}, d1={d1}, d2= {d2}, d3={d3}");
}Обратите внимание, что для элемента, значение которого нам не интересно, мы использовали “выброшенную” (discarded) переменную.
Массивы
Массивы также можно деструктурировать.
#![allow(unused)]
fn main() {
let arr: [i32;3] = [1, 2, 3];
let [a1, a2, a3] = arr;
println!("a1={a1}, a2={a2}, a3={a3}");
}При деструктурировании массива можно часть элементов, идущих с начала массива, присвоить переменным, а оставшиеся элементы (в хвосте массива) проигнорировать.
#![allow(unused)]
fn main() {
let arr: [i32;5] = [1, 2, 3, 4, 5];
let [a_1, _, a_3, ..] = arr;
println!("a1={}, a3={}", a_1, a_3);
}Также оставшиеся элементы в хвосте массива можно не игнорировать, а записать в новый массив:
#![allow(unused)]
fn main() {
let arr: [i32;5] = [1, 2, 3, 4, 5];
let [a_1, _, a_3, rest @ ..] = arr;
// Тип переменной rest - массив [i32, 2]
println!("a1={}, a3={}, rest={:?}", a_1, a_3, rest);
}Выражение rest@.. означает: привязать все остальные элементы к переменной rest.
Мы не можем совершить деструктурирующее присваивание для слайсов или векторов, так как компилятор не может гарантировать соответствие количества переменных в деструктурирующем шаблоне с количеством элементов в слайсе. Массив же, в отличие от слайсов, имеет фиксированный размер, известный еще на стадии компиляции.
Структуры
Аналогично тому, как кортежи деструктурируются исходя из позиции элементов, структуры деструктурируются исходя из имён полей.
struct Person { name: String, age: u32 }
fn main() {
let p = Person { name: String::from("John"), age: 25 };
let Person { name, age } = p;
println!("Name={}, Age={}", name, age);
}При деструктурировании структуры мы также можем “извлечь” только те поля, которые нам нужны:
struct Person { name: String, age: u32 }
fn main() {
let p = Person { name: String::from("John"), age: 25 };
let Person { name, .. } = p;
println!("Name={name}");
}Деструктурирование аргументов
Производить деструктурирование объектов можно не только при присваивании, но и при принятии аргументов в функцию.
struct Point2D {
x: i32,
y: i32,
}
fn print_point_2d(Point2D { x, y }: Point2D) {
println!("2D point ({x}, {y})");
}
fn main() {
let p = Point2D { x: 1, y: 5 };
print_point_2d(p);
}Разумеется, деструктурировать можно и аргументы, являющиеся кортежными структурами.
// Red, Green, Blue, Alpha
struct Rgba(u8, u8, u8, u8);
// Проверяет, если цвет НЕ является полупрозрачным,
// т.е. alpha компонента равна 255
fn is_fully_opaque(Rgba(_, _, _, alpha): Rgba) -> bool {
alpha == 255
}
fn main() {
println!("Is opaque: {}", is_fully_opaque(Rgba(125, 0, 0, 255)));
println!("Is opaque: {}", is_fully_opaque(Rgba(200, 200, 200, 50)));
}Паттерн матчинг
В дополнение к оператору if, в Rust имеется ещё один оператор ветвления, который мы не рассмотрели раньше — оператор match, который часто называют паттерн-матчингом (pattern matching).
Этот оператор является неким гибридом классического switch-case (из C или Java) и деструктурирующего присваивания.
Синтаксис:
match значение {
шаблон 1 => выражение 1,
…
шаблон N => выражение N,
}Оператор последовательно примеряет шаблоны к значению: если шаблон совпадает, то выполняется соответствующее ему выражение и оператор match завершает свою работу, иначе происходит проверка следующего по списку шаблона.
Шаблон может быть:
- константой
- переменной или переменной с условным блоком
- шаблоном деструктурирующего присваивания
Рассмотрим все варианты в порядке возрастания сложности.
match как switch-case
Самый простой вариант использования оператора match — прямое сопоставление значения: как switch-case из C или Java.
В качестве примера, проверим равно ли значение числовой переменной 0 или 1:
fn main() {
let a = 1;
match a {
0 => println!("It is 0"),
1 => println!("It is 1"),
_ => println!("Neither 0 nor 1"),
}
// Напечатает: It is 1
}Компилятор проверяет, что в теле match присутствуют ветки для всех возможных вариантов значения переменной.
Именно поэтому после веток с 0 и 1 мы также вставили ветку с шаблоном _. Этот шаблон совпадает с абсолютно любым значением и служит в качестве ветки default, если проводить аналогию с оператором switch-case, или в качестве ветки else, если сравнивать с оператором if.
На самом деле, шаблон _ — это обычная “выброшенная” переменная, такая же, как и те, что мы видели в деструктурирующих шаблонах. Вместо “выброшенной” переменной можно указать переменную с любым корректным именем, и тогда в неё будет записано значение, переданное в match.
fn main() {
let a = 5;
match a {
0 => println!("The number is 0"),
1 => println!("The number is 1"),
x => println!("The number is {x}"),
}
// Напечатает: The number is 5
}Имейте в виду, что такой шаблон в виде переменной подходит под любое значение, поэтому должен располагаться в самом конце списка шаблонов.
В шаблоне можно также перечислить несколько значений:
fn main() {
let a: u32 = 7;
match a {
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 =>
println!("The number is less than 10"),
_ =>
println!("The number is equal to or greater than 10"),
}
// Напечатает: The number is less than 10
}Проверяя числа в шаблоне, вместо того, чтобы перечислять подряд все значения, можно указать диапазон:
fn main() {
let a: u32 = 44;
match a {
0 ..= 9 => // от 0 до 9 включительно
println!("The number is less than 10"),
10 .. 100 => // от 10 до 100 не включительно
println!("The number is in range [10,99]"),
_ =>
println!("The number is equal to or greater than"),
}
// Напечатает: The number is in range [10,99]
}Переменная привязка
В примере выше мы указали целый диапазон значений. Но что если мы хотим знать не только диапазон, в который попадает значение, но и само значение? Можно, конечно, напрямую обратиться к переменной, переданной в match, однако это не всегда возможно (например, если в match было передано арифметическое выражение или вызов функции).
В таком случае нам поможет переменная привзяка (binding). Это такая переменная, в которую записывается значение, которое удовлетворило шаблону.
Синтаксис:
привязка @ шаблон => выражение
Теперь перепишем пример выше с использованием привязок:
fn main() {
match 22 + 22 {
x@(0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9) =>
println!("{x} is less than 10"),
x@10 .. 100 =>
println!("{x} is in range [10,99]"),
x =>
println!("{x} is equal to or greater than"),
}
// Напечатает: 44 is in range [10,99]
}match как выражение
Оператор match, как и оператор if, возвращает значение. Результат всего оператора match — результат отработавшей условной ветки.
Пример оператора match, который используется для получения модуля числа (неотрицательной части):
#![allow(unused)]
fn main() {
let a = -5;
let absolute = match a {
.. 0 => -a, // диапазон от минус бесконечности до 0 невключительно
_ => a,
};
println!("{absolute}"); // 5
}Сравнение со строковыми литералами
Допустим, у нас имеется объект строки типа String и мы хотим проверить её содержимое при помощи оператора match. Мы можем попытаться написать такую проверку следующим образом:
fn main() {
let name = String::from("Robert Smith");
let is_anonymous = match name {
"Anonymous".to_string() => true,
"John Doe".to_string() => true,
_ => false,
};
}Компиляция этой программы завершится с ошибкой:
"Anonymous".to_string() => true,
^^^^^^^^^^^^^^^^^^^^^^^ not a pattern
Дело в том, что, как мы сказали в самом начале, шаблон может быть либо константой, либо переменной, либо шаблоном деструктурирующего присваивания. Выражение "Anonymous".to_string() не является ни одним из вышеперечисленных.
Note
Здесь, говоря о переменной, мы имеем в виду переменную-шаблон для присваивания (или деструктурирующего присваивания), а не переменную, объявленную за пределами
matchблока и содержащую некое значение. Т.е. такой код работает не так, как вы могли ожидать:fn main() { let anonymous = "Anonymous".to_string(); let john_doe = "John Doe".to_string(); let name = String::from("Robert Smith"); let is_anonymous = match name { anonymous => true, // отработает эта ветка john_doe => true, _ => false, }; println!("{is_anonymous}"); // true }Эта программа печатает “true”, потому что переменная
anonymousв блокеmatchвоспринимается не как переменная объявленная выше и содержащая строку “Anonymous”, а как переменная-шаблон для присваивания. Разумеется, одиночная переменная без дополнительных условий является шаблоном, который подходит под абсолютно любое значение.
Единственное, что нам остаётся — использовать строковые литералы, так как они являются константами.
fn main() {
let name = String::from("Robert Smith");
let is_anonymous = match name.as_str() {
"Anonymous" | "John Doe" => true,
_ => false,
};
}Обратите внимание, что мы передаём в оператор match не просто переменную name, а строковый слайс от неё — name.as_str().
match для слайсов
Для слайсов можно использовать шаблоны, которые выглядят в точности как шаблоны деструктурирующего присваивания для массивов.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let s = match v.as_slice() {
[] => 0,
[a, b, c, ..] => a + b + c,
_ => -1,
};
println!("{}", s); // 6
}Еще раз напомним, что слайсы нельзя использовать в “обычном” деструктурирующем присваивании, потому что компилятор не может гарантировать, что количество переменных из деструктурирующего шаблона соответствует количеству элементов в слайсе.
Но у match такой проблемы нет, так как несовпадение слайса с шаблоном, всего лишь означает, что match перейдёт к следующему шаблону и попытается сопоставить слайс с ним.
match для структур
Синтаксис шаблонов для структур в паттерн-матчинге очень похож на синтаксис шаблонов для деструктурирующего присваивания, однако позволяет дополнительно задавать значения для полей.
struct Person { name: String, age: u32 }
fn main () {
let p = Person { name: String::from("John"), age: 17 };
match p {
Person { name, age: 1 .. 18 } => println!("Person {name} is not adult"),
Person { name, age: 18 } => println!("Person {name} just turned 18"),
Person { name, .. } => println!("Person {name} is adult"),
}
// Напечатает: Person John is not adult
}match if
В шаблонах можно указывать дополнительное условие при помощи ключевого слова if.
struct Person { name: String, age: u32 }
fn main () {
let p = Person { name: String::from("John"), age: 17 };
match p {
Person { name, age } if age < 18 =>
println!("Person {name} is not adult"),
Person { name, age } if age == 18 =>
println!("Person {name} just turned 18"),
Person { name, .. } =>
println!("Person {name} is adult"),
}
// Напечатает: Person John is not adult
}Условие в блоке if может:
- быть составным, т.е. содержать несколько условий, скомбинированных через операторы
||и&& - обращаться к полям шаблона, биндингам и любым другим именам, доступным в этом скоупе
При помощи блока if можно переписать наш пример со строками:
fn main() {
let name = String::from("Robert Smith");
let is_anonymous = match name {
s if s == "Anonymous" => true,
s if s == "John Doe" => true,
_ => false,
};
println!("{is_anonymous}"); // false
}Такой код работает корректно, однако вариант с сопоставлением со строковыми литералами более изящен.
ref
Как мы знаем, деструктурирующее присваивание разрушает присваиваемый объект. Если мы не хотим разрушать объект, а хотим просто получить ссылку на его поле, то мы можем “деструктурировать” объект не по значению, а по ссылке:
#[derive(Debug)]
struct Person { name: String, age: u32 }
fn main() {
let mut person = Person { name: String::from("Anonymous"), age: 25 };
let Person {name, ..} = &mut person;
*name = "John Doe".to_string();
// Объект person всё еще "жив"
println!("{person:?}"); // Person { name: "John Doe", age: 25 }
}Деструктурирующие шаблоны в операторе match — не исключение: они так же уничтожают переданный в них объект.
Но можно ли передать объект в оператор match по ссылке так же, как в “обычном” деструктурирующем присваивании?
Да, можно:
#[derive(Debug)]
struct Person { name: String, age: u32 }
fn main () {
let mut person = Person { name: String::from("Anonymous"), age: 25 };
match &mut person {
Person { name, .. } if name == "Anonymous" => {
*name = "John Doe".to_string();
},
Person { .. } => (),
}
println!("{person:?}"); // Person { name: "John Doe", age: 25 }
}Однако специально для патерн-матчинга существует ключевое слово ref, которое позволяет в деструктурирующем шаблоне захватить поле объекта по ссылке несмотря на то, что объект был передан в match по значению. При этом, если все поля объекта захватываются по ref ссылке (или игнорируются), то исходный объект не разрушается.
#[derive(Debug)]
struct Person { name: String, age: u32 }
fn main () {
let mut person = Person { name: String::from("Anonymous"), age: 25 };
match person {
Person { ref mut name, .. } if name == "Anonymous" => {
*name = "John Doe".to_string();
},
Person { .. } => (),
}
println!("{person:?}"); // Person { name: "John Doe", age: 25 }
}Как видите, здесь мы передали переменную person в match по значению, а не по ссылке. Но поскольку в шаблоне мы обратились к полю name по ref ссылке, а не по значению, уничтожение объекта не произошло. Поэтому переменная person осталась действительной после передачи в match.
Анонимные функции
Rust испытал на себе определённое влияние функционального программирования, поэтому имеет поддержку анонимных функций, замыканий и функций высшего порядка.
Анонимные функции
Анонимная функция — функция, являющаяся объектом, который можно присвоить переменной, передать в качестве аргумента в другую функцию и, разумеется, вызвать.
Анонимные функции декларируются при помощи следующего синтаксиса:
|аргумент_1, …, аргумент_n| -> ТипРезультата { тело функции }
Tip
Исходный код анонимной функции часто называют “функциональным литералом”.
Например:
fn main() {
// создаём анонимную функцию, и присваиваем её переменной
let inc: fn(i32) -> i32 = |x: i32| { x + 1 };
let a = 1;
// вызываем нашу функцию абсолютно так же, как и обычную
let b = inc(a);
println!("{b}"); // 2
}Обратите внимание, что тип анонимной функции имеет вид:
fn(тип_аргумента_1, ..., тип_аргумента_2) -> тип_результата
Такой тип называется указателем на функцию (function pointer).
Как и в случае с обычными переменными, тип анонимной функции можно не указывать, если компилятор в состоянии вывести его по телу анонимной функции.
#![allow(unused)]
fn main() {
let inc = |x: i32| { x + 1 };
}Также, фигурные скобки вокруг тела анонимной функции не обязательны, если оно состоит только из одного выражения:
#![allow(unused)]
fn main() {
let inc = |x: i32| x + 1;
}В некоторых ситуациях компилятор способен вывести и типы аргументов. В этом случае можно опустить и типы.
fn main () {
// Компилятор вывел тип x исходя из использования inc ниже.
let inc = |x| x + 1;
let a = 1;
let b = inc(a);
println!("{b}")
}Note
Часто анонимные функции называют лямбда-выражениями, отсылаясь к разделу математики “Лямбда-исчисление”, которое легло в основу функционального программирования. Также анонимные функции часто называют лямбда-функциями.
Функции высшего порядка
Функцией высшего порядка называют функции, которые принимают другие функции в качестве аргумента либо возвращают функцию в качестве результата.
Для примера напишем функцию высшего порядка transform, которая принимает два аргумента — число и функцию, и возвращает результат применения этой функции к числу:
fn transform(a: i32, f: fn(i32) -> i32) -> i32 {
f(a)
}
fn main() {
let inc: fn(i32) -> i32 = |x: i32| { x + 1 };
let a = 9;
let b = transform(a, inc);
println!("{b}"); // 10
}Теперь рассмотрим пример, когда функция возвращает анонимную функцию в качестве результата:
fn create_inc() -> fn(i32) -> i32 {
|x: i32| x + 1
}
fn main() {
let inc = create_inc();
let a = 1;
let b = inc(a);
println!("{b}"); // 2
}Указатель на функцию
Анонимные функции компилируются таким же образом, как и обычные, и помещаются в сегмент кода. Когда мы присваиваем анонимную функцию переменной, то в переменную просто записывается указатель на функцию, находящуюся в сегменте кода.
В таком случае чем на уровне исполняемого кода анонимная функция принципиально отличается от обычной? Ничем. Более того, указатель на обычную функцию тоже можно присвоить переменной.
fn func_inc(x: i32) -> i32 {
x + 1
}
fn main() {
let inc: fn(i32) -> i32 = func_inc;
let a = inc(7);
println!("{a}"); // 8
}Как мы видим, анонимные функции — это просто другой синтаксис для создания функций.
Замыкание
В примере выше мы сделали функцию create_inc, которая возвращает анонимную функцию — инкремент:
#![allow(unused)]
fn main() {
fn create_inc() -> fn(i32) -> i32 {
|x: i32| x + 1
}
}Теперь давайте попробуем написать функцию, которая возвращает анонимную функцию, которая увеличивает свой аргумент не на единицу, а на заданный шаг:
#![allow(unused)]
fn main() {
fn make_inc_with_step(step: i32) -> fn(i32) -> i32 {
|x| { x + step }
}
}Увы, такой код не скомпилируется, и выдаст ошибку:
|x| { x + step }
^^^^^^^^^^^^^^^^ expected fn pointer, found closure
Дело в том, что из тела нашей анонимной функции, мы обращаемся к данным, которые принадлежат скоупу за пределами функции. Такая анонимная функция называется замыканием (closure).
Note
Такое название происходит из того, что анонимная функция как бы “замкнута” на свой внешний скоуп. Также часто говорят, что замыкание “захватывает” данные из внешнего контекста.
Замыкания, по своей природе, гораздо сложнее “чистых” анонимных функций (которые зависят только от своих аргументов). Чистая анонимная функция просто превращается в обычную функцию в сегменте кода, и мы работаем с ней через указатель на функцию. Замыкание же — это объект, представляющий из себя сложную комбинацию кода и захваченных данных.
Note
Понятие “чистой” функции широко используется в функциональном программировании. Чистая функция обращается исключительно к своим аргументам, и никак не взаимодействует с внешними по отношению к ней данными.
Давайте сначала перепишем код так, чтобы он работал, а дальше будем разбираться с устройством замыканий.
fn make_inc_with_step(step: i32) -> impl Fn(i32) -> i32 {
move |x| { x + step }
}
fn main() {
let inc_with_5 = make_inc_with_step(5);
let a = inc_with_5(2);
println!("{a}"); // 7
}Как видим, у нас появилось два отличия:
-
fn(i32)->i32превратилось вimpl Fn(i32)->i32, что явно указывает на то, что замыкание — это не просто указатель на функцию, а объект некого типа, который реализует трэйтFn. -
Перед объявлением функционального литерала появилось ключевое слово move, которым мы явно указываем для компилятора, что если мы внутри замыкания используем какое-то значение из внешнего контекста, то владение над этим значением перемещается к замыканию.
Типы замыканий
Как мы уже сказали, для всех “чистых” анонимных функций, используется один тип данных — указатель на функцию, который имеет вид fn(...)->.... Вернее, сами типы отличаются, но все они объединены в семейство указателей на функции. Для замыканий же есть три разных трэйта:
-
Fn — трэйт для замыканий, которые захватывают значения из внешнего контекста по значению либо по немутабельной ссылке. Такие замыкания безопасно использовать в многопоточной среде, так как они только читают захваченное значение.
-
FnMut — трэйт для замыканий, которые захватывают значения из внешнего контекста и изменяют их по мутабельной ссылке. Такие замыкания нельзя использовать в многопоточной среде без предварительной синхронизации, так как они могут менять захваченное значение.
-
FnOnce — трэйт для замыканий, которые захватывают значения из внешнего контекста по значению (т.е. берут над ним владение) и уничтожают это значение в процессе своего вызова. Такое замыкание можно вызвать только один раз, так как после первого вызова значение будет уничтожено и недоступно для второго вызова.
Захват по ссылке и перемещение владения
Как мы сказали выше, замыкание может захватывать значения из внешнего контекста по значению или по ссылке. От того, каким образом захваченное значение будет использовано в теле замыкания, будет зависеть то, на основе какого трэйта компилятор сгенерирует тип замыкания: Fn, FnMut или FnOnce.
Рассмотрим самый простой пример захвата по немутабельной ссылке.
fn main() {
let salutation = "Hello".to_string();
// Тип замыкания: impl Fn(&str)->String
let greet = |name: &str| make_greeting(&salutation, name);
println!("{}", greet("John")); // Hello John
// Переменная salutation захвачена замыканием по немутабельной ссылке,
// поэтому всё еще может быть использована после захвата.
print_string(salutation); // OK, data is still usable
}
fn make_greeting(salutation: &str, name: &str) -> String {
format!("{} {}", &salutation, name)
}
fn print_string(s: String) {
println!("{s}")
}Захват значения переменной salutation произошёл по немутабельной ссылке, потому что в теле самого замыкания мы используем немутабельную ссылку &salutation .
Note
Нам пришлось создать отдельные функции
make_greetingиprint_string, чтобы по их сигнатурам было явно видно, какие аргументы используются по ссылке, а какие по значению. Использование макросовformat!иprintln!напрямую нарушило бы чистоту эксперимента, так как эти макросы используют объекты строк по ссылке, даже если их явно передать по значению.
Если же в теле замыкания, мы используем по значению переменную, захваченную из внешнего контекста, то и захват произойдёт по значению.
fn main() {
let salutation = "Hello".to_string();
// Тип замыкания: impl FnOnce(&str)->String
let greet = |name: &str| make_greeting(salutation, name);
println!("{}", greet("John")); // Hello John
// Теперь когда salutation захвачена по значению,
// т.е. перемещена в замыкание использовать её нельзя
print_string(salutation); // Error: use of moved value: `salutation`
}
fn make_greeting(salutation: String, name: &str) -> String {
format!("{} {}", &salutation, name)
}
fn print_string(s: String) {
println!("{s}")
}Почему в предыдущих примерах перед анонимными функциями не использовалось ключевое слово move, как это было в примере из секции Замыкание? Дело в том, что move нужно явно указывать только, если замыкание живёт дольше скоупа, в котором оно создано. В нашем простом примере компилятор способен сам однозначно разобраться, какое поведение ожидается. Но если мы попытаемся вынести создание замыкания greet в отдельную функцию, то move понадобится:
#![allow(unused)]
fn main() {
fn make_greet_closure() -> impl Fn(&str) -> String {
let salutation = "Hello".to_string();
move |name: &str| make_greeting(&salutation, name)
}
}Здесь наше замыкание живёт дольше, чем скоуп, в котором оно создано: скоуп (тело функции make_greet_closure) завершается, а замыкание продолжает жить в коде, который вызвал функцию make_greet_closure.
FnMut
Как мы уже сказали, если замыкание захватывает значение по мутабельной ссылке, то компилятор делает такое замыкание реализацией трэйта FnMut.
Для примера напишем еще одно инкрементирующее замыкание. Однако теперь это замыкание будет иметь ссылку на число, которое хранит шаг инкремента. Причём после каждого вызова этот шаг инкремента будет увеличиваться на единицу.
fn main() {
let mut step = 1;
// impl FnMut(i32)->i32
let mut growing_inc = |x: i32| {
let step_ref = &mut step;
let res = x + *step_ref;
*step_ref += 1;
res
};
println!("{}", growing_inc(1)); // 2
println!("{}", growing_inc(1)); // 3
println!("{}", growing_inc(1)); // 4
}Как видите, с каждым вызовом замыкания число, на которое замыкание увеличивает переданный в него аргумент, возрастает на единицу.
Important
Важно напомнить, что тип замыкания зависит не от того, как значение захвачено из внешнего скоупа, а от того, как это захваченное значение используется.
Замыкание из примера выше имеет тип, основанный на
FnMut, не потому, что оно захватывает значение по мутабельной ссылке, а потому, что оно по мутабельной ссылке изменяет значение, чьё время жизни больше, чем один вызов замыкания.
Рассмотрим этот же пример, но только теперь наше замыкание захватит переменную step не по мутабельной ссылке, а по значению.
fn main() {
let mut step = 1;
// impl FnMut(i32)->i32
let mut growing_inc = |x: i32| {
let res = x + step;
step += 1;
res
};
println!("{}", growing_inc(1)); // 2
println!("{}", growing_inc(1)); // 3
println!("{}", growing_inc(1)); // 4
}Это замыкание всё еще увеличивает шаг инкремента после каждого своего вызова, и тип замыкания всё еще реализует трэйт FnMut. Почему так? Как мы сказали: не важно, как замыкание захватило значение, важно то, как оно это значение изменяет.
Замыкание захватило переменную step по значению, и поместило в свой контекст, где это значение существует вне вызовов самого замыкания. А при вызове замыкание изменяет это значение по мутабельной ссылке.
FnOnce
После того как мы детально рассмотрели Fn и FnMut, разобраться с FnOnce должно быть несложно. Главное помнить, что тип замыкания зависит от того, что замыкание делает с захваченным значением:
Fnзамыкания только читают захваченное значениеFnMutзамыкания изменяют захваченное значение по мутабельной ссылкеFnOnceзамыкание уничтожает захваченное значение
Рассмотрим следующий пример:
// Обёртка над println!(), которая принимает строку по значению,
// следовательно забирает её себе из вызывающего кода
fn print_and_destroy(s: String) {
println!("{s}");
}
fn main() {
let text = "text".to_string();
// Тип замыкания: FnOnce()
let closure_print_and_destroy = || print_and_destroy(text);
closure_print_and_destroy();
}Если попытаться вызвать closure_print_and_destroy() во второй раз, то компилятор выдаст ошибку:
closure cannot be invoked more than once because it moves the variable
textout of its environment.
Этот тип замыканий часто используется, когда замыкание захватывает какой-то ресурс, операция над которым имеет побочный эффект: закрытие файла, очистка памяти, и другие операции, которые можно сделать только один раз.
Конкретный тип замыкания
В коде программы мы не имеем доступа к конкретному типу замыкания, потому что этот конкретный тип будет сгенерирован только при компиляции.
То есть мы не можем написать:
fn make_inc_with_step(step: i32) -> impl Fn(i32) -> i32 {
move |x| { x + step }
}
fn main() {
let inc_with_5: Какой-то тип = make_inc_with_step(5);
}Единственное, что мы можем знать о типе замыкания — то, какой трэйт он реализует и какая у замыкания сигнатура (типы аргументов и возвращаемого значения).
Note
В ночной сборке Rust при помощи флага
type_alias_impl_traitможно включить псевдонимы для impl Трэйтов. Тогда можно будет писать так:type MyFn = impl Fn(i32) -> i32; let inc_with_5: MyFn = make_inc_with_step(5);На момент выхода Rust 1.92 эта фича всё еще не была доступна в стабильной ветке.
Также очень важно знать, что в программе на Rust нет двух замыканий с одинаковыми типами. Даже если у двух замыканий совпадает сигнатура и трэйт, который они реализуют, то конкретные типы, которые компилятор выведет для замыканий, будут разными. Следовательно, мы не можем написать такой код:
#![allow(unused)]
fn main() {
fn make_inc(is_decrement: bool) -> impl Fn(i32) -> i32 {
if is_decrement {
return move |x| { x - 1 };
} else {
return move |x| { x + 1 };
}
}
}Как вы могли понять, компиляция функции завершается с ошибкой, так как impl Трэйт должно быть заменено на конкретный тип во время компиляции, а у этих двух замыканий, конкретные типы разные.
В качестве решения, мы можем использовать тот трюк, с которым познакомились в главе о Трэйтах — воспользоваться динамической диспетчеризацией. То есть вместо impl Fn возвращать dyn Fn.
fn make_inc(is_decrement: bool) -> Box<dyn Fn(i32) -> i32> {
if is_decrement {
Box::new(move |x| { x - 1 })
} else {
Box::new(move |x| { x + 1 })
}
}
fn main() {
let dec: Box<dyn Fn(i32) -> i32> = make_inc(true);
let a = 2;
let b = dec(a);
println!("{b}"); // 1
}Этот код компилируется и выполняется без проблем.
Генерики
Генерики (generics) — это механизм, который позволяет писать функциональность, работающую со значениями, абстрагируясь от типов этих значений.
Note
Мы будем одинаково использовать названия и “генерик”, и “обобщённый”.
Например, если мы создаём структуру данных “список”, то мы будем сфокусированы на работе с элементами в списке (добавление элемента, удаление, поиск, вставка), а не над тем, какой тип у этих элементов. Функциональность списка не изменится в зависимости от того, храним мы в нём числа или строки.
Уже знакомый нам тип вектор — Vec как раз является генерик-типом: в векторе мы можем хранить значения любого типа данных.
Генерик типы и функции
Для того чтобы разобраться с генериками, давайте создадим максимально простой обобщённый тип — структуру-обёртку. Эта обёртка не имеет никакой специальной функциональности, она просто хранит в себе значение, но эта обёртка подходит для хранения значений любого типа.
#![allow(unused)]
fn main() {
struct Holder<T> {
v: T
}
}Здесь <T> — это так называемый генерик тип-аргумент (generic type argument): тип, над которым мы абстрагируемся.
Note
В примере выше мы назвали наш абстрагированный тип как
T(самое популярное имя для генерик типа-аргумента), но это имя может быть абсолютно любым, например “Element”.#![allow(unused)] fn main() { struct Holder<Element> { v: Element } }
Holder<T> — это, скорее, не тип, а шаблон для создания типа. Когда компилятор встречает использование Holder<T> для значения какого-то типа, например i32, он генерирует конкретный тип Holder<i32>.
struct Holder<T> {
v: T
}
fn main() {
let bool_holder: Holder<bool> = Holder { v: true };
let i32_holder: Holder<i32> = Holder { v: 5 };
let string_holder: Holder<String> = Holder { v: "aaa".to_string() };
}Обобщёнными могут быть не только структуры, но и функции. Напишем для нашей генерик структуры Holder<T> соответствующую обобщённую функцию-конструктор:
#![allow(unused)]
fn main() {
fn make_holder<T>(v: T) -> Holder<T> {
Holder {v: v}
}
}Как видим, генерик аргумент для функции указывается так же, как и для структуры: в угловых скобках после имени.
Теперь мы можем создавать экземпляры Holder, используя эту функцию:
struct Holder<T> {
v: T
}
fn make_holder<T>(v: T) -> Holder<T> {
Holder {v: v}
}
fn main() {
let bool_holder: Holder<bool> = make_holder(true);
let i32_holder: Holder<i32> = make_holder(5);
let string_holder: Holder<String> = make_holder("aaa".to_string());
}Note
Заметьте, генерик тип-аргумент
Tу функцииmake_holder<T>никак не связан с генерик аргументомTв объявлении структурыHolder<T>. Просто, как мы уже сказали,T— самое популярное имя. Если бы мы написалиfn make_holder<A>(v: A) -> Holder<A>, то ничего бы не изменилось.
Чтобы сложить полную картину, давайте посмотрим, как выглядят методы для генерик структур. Сделаем два метода: get — для получения значения из нашей обёртки, и set — для записи нового значения.
impl<T> Holder<T> {
fn get(&self) -> &T {
&self.v
}
fn set(&mut self, new_v: T) {
self.v = new_v;
}
}В этой конструкции мы видим два генерик тип-аргумента: в impl<T> и в Holder<T>. Тот, который в impl<T> — объявляет имя генерик тип-аргумента для всего impl блока. Генерик аргумент в Holder<T> просто устанавливает связь между генерик аргументом из impl<T> и генерик аргументом в объявлении структуры Holder<T>.
Мы словно говорим:
Для некоего типа
Tмы реализуем шаблонный типHolder, который при параметризации этим типомTимеет такие имплементации методовgetиset.
Немного запутано, но станет понятнее в более сложных примерах далее.
А теперь всё вместе:
struct Holder<T> {
v: T
}
impl<T> Holder<T> {
fn get(&self) -> &T {
&self.v
}
fn set(&mut self, new_v: T) {
self.v = new_v;
}
}
fn make_holder<T>(v: T) -> Holder<T> {
Holder {v: v}
}
fn main() {
let mut h = make_holder(1);
println!("{}", h.get()); // 1
h.set(5);
println!("{}", h.get()); // 5
}Мономорфизация генериков
Как мы уже сказали, генерик типы вроде Holder<T> — это скорее шаблоны типов, а конкретные типы получаются при параметризации генерика конкретным типом, например Holder<i32>.
Каждый раз, когда компилятор встречает использование генерик типа с новым тип-аргументом, он генерирует конкретный вариант генерика под этот тип. Это генерирование конкретных типов для генерик-типов называют мономорфизацией.
Например, мы использовали наш генерик тип Holder<T> для типов i32 и bool. Компилятор мономорфизирует Holder<T> для i32 и для bool примерно так (в реальности имена будут выглядеть сложнее):
struct Holder_i32 {
v: i32
}
struct Holder_bool {
v: bool
}То же самое произойдёт и с методами, и с функциями: под каждый тип-аргумент будут сгенерированы конкретные варианты функций.
|
|
|
|
Note
В языках Java и C# также имеются генерики. Однако в этих языках отличительной чертой генериков является так называемое “стирание” генерик тип-аргумента при компиляции. Другими словами, в Java генерики используются просто как дополнительный контроль типов во время компиляции.
Но после компиляции информация о генерик тип-аргументах исчезает и недоступна во время работы программы.
В Rust же генерики больше похожи на шаблоны в C++, где при компиляции также происходит мономорфизация шаблона.
Турборыба ::<>
Мы уже видели пример использования генерик-функции для создания объекта генерик-структуры.
struct Holder<T> {
v: T
}
fn make_holder<T>(v: T) -> Holder<T> {
Holder {v: v}
}
fn main() {
let mut h = make_holder(1); // тип переменной - Holder<i32>
}Здесь компилятор смог самостоятельно вывести тип генерик-функции make_holder по типу аргумента, с которым функция была вызвана: раз тип аргумента — i32, то и тип результата функции — Holder<i32>.
Но если у функции нет аргументов, то компилятор не сможет сам вывести тип генерика, и его придётся указать явно. Для примера рассмотрим функцию, которая возвращает пустой вектор:
fn make_empty_vec<T>() -> Vec<T> {
Vec::new()
}При вызове make_empty_vec тип генерика можно указать через тип для переменной, которой присваивается результат.
let v: Vec<i32> = make_empty_vec();Но можно указать генерик тип-аргумент прямо на вызове функции:
let v = make_empty_vec::<i32>();Этот синтаксис задания генерик тип-аргумента ::<> прозвали турборыбой (turbofish).
Генерик трэйты
Обобщёнными могут быть не только структуры и функции, но и трэйты.
// Задаёт интерфейс доступа к некому значению внутри типа
// при помощи методов get и set.
// При этом тип элемента, к которому осуществляется доступ,
// задаётся генериком.
trait CanBeAccessed<T> {
fn get(&self) -> &T;
fn set(&mut self, new_v: T);
}
// Задаёт интерфейс для создания нового объекта.
trait HasGenericConstructor<T> {
// Из объекта типа T cоздаёт объект типа,
// реализующего HasGenericConstructor<T>
fn new(value: T) -> Self;
}
struct Holder<T> {
v: T
}
impl<T> CanBeAccessed<T> for Holder<T> {
fn get(&self) -> &T {
&self.v
}
fn set(&mut self, new_v: T) {
self.v = new_v;
}
}
impl<T> HasGenericConstructor<T> for Holder<T> {
fn new(value: T) -> Self {
Holder { v: value }
}
}
fn main() {
let mut h = Holder::new(5);
h.set(7);
println!("{}", h.get());
}Как мы видим из примера, генерик трэйты ведут себя ровно так же, как и обычные, только теперь у них появился генерик тип-аргумент.
Ассоциированные типы
Для генерик трэйтов существует альтернативный синтаксис для указания генерик тип-аргумента: через специальное поле — ассоциированный тип.
trait Имя {
type АссоциированныйТип;
}Следующий пример показывает, как соотносятся между собой генерик с тип-аргументом и генерик с ассоциированным типом.
Трэйт с генерик тип-аргументом
|
Трэйт с ассоциированным типом
|
Перепишем наш пример из раздела про генерик трэйты с использованием ассоциированного типа:
trait CanBeAccessed {
type ElementType;
fn get(&self) -> &Self::ElementType;
fn set(&mut self, new_v: Self::ElementType);
}
trait HasGenericConstructor {
type TypeArg;
fn new(value: Self::TypeArg) -> Self;
}
struct Holder<T> {
v: T
}
impl<T> CanBeAccessed for Holder<T> {
type ElementType = T;
fn get(&self) -> &T {
&self.v
}
fn set(&mut self, new_v: T) {
self.v = new_v;
}
}
impl<T> HasGenericConstructor for Holder<T> {
type TypeArg = T;
fn new(value: T) -> Self {
Holder { v: value }
}
}
fn main() {
let mut h = Holder::new(5);
h.set(7);
println!("{}", h.get());
}Хоть генерик трэйты и трэйты с ассоциированным типом служат одной цели, у них всё же имеются два различия.
1) Первое отличие генерик-трэйтов от трэйтов с ассоциированным типом заключается в том, где определяется тип, которым будет параметризирован генерик:
-
Для генерик трэйта фактический тип генерик тип-аргумента определяется в коде, где используется структура, реализующая этого генерик трэйт.
-
Для трэйта с ассоциированным типом тип ассоциированного поля определяется в блоке реализации трэйта для структуры (
impl Трэйт for Тип). В примере выше в блокеimpl<T> CanBeAccessed for Holder<T>мы определили, что тип поля-ассоциированного типа для трэйтаCanBeAccessedбудет таким же, как и генерик тип-аргумент в структуреHolder<T>. И это никак нельзя переопределить в месте создания объектаHolder.
2) Второе отличие заключается в реализации трэйтов для типов.
Один и тот же генерик трэйт можно несколько раз реализовать для одного и того же типа, указав разные типы для тип-аргумента:
trait ValueProducer<T> {
fn produce() -> T;
}
struct ProducerImpl;
impl ValueProducer<i32> for ProducerImpl {
fn produce() -> i32 {
5
}
}
impl ValueProducer<String> for ProducerImpl {
fn produce() -> String {
"Hello".to_string()
}
}
fn main() {
let n: i32 = ProducerImpl::produce();
println!("{n}");
let s: String = ProducerImpl::produce();
println!("{s}");
}Написать аналогичный код, используя трэйт с ассоциированным типом, не получится.
Границы генериков
Когда мы объявляем обобщённый тип или функцию, мы можем указать, что генерик тип-аргумент должен реализовывать некий трэйт. Другими словами, мы можем ограничить его трэйтом.
fn my_func<T: Трэйт>(...) -> ... {
...
}
struct MyStruct<T: Трэйт> {
v: T
}В таком случае компилятор позволит параметризировать наш обобщённый тип/функцию только теми типами, которые реализуют этот указанный трэйт.
// Функция принимает аргумент любого типа, который реализует трэйт Copy
fn duplicate<T: Copy>(v: T) -> T {
v
}
fn main() {
let num = 5;
let num_dup = duplicate(num); // i32 реализует трэйт Copy
let s = "Hello".to_string();
let s_dup = duplicate(s); // String не реализует трэйт Copy
// ^^^^^^^^^^^^ the trait `Copy` is not implemented for `String
}Если генерик тип-аргумент должен реализовывать несколько трейтов, то их надо перечислить через знак +
fn my_func<T: Трэйт1 + Трэйт2 + Трэйт3>(...) -> ... {
...
}На этом моменте вам может показаться, что это ограничение типов по реализуемому ими трэйту очень похоже на передачу аргументов по impl Трэйт, с которым мы познакомились в главе Трэйты / Статическая диспетчеризация. Ведь по сути, impl Трэйт тоже может быть заменён только на тип, который этот трэйт реализует.
|
генерик с границей |
|
То есть: передача аргументов по генерику с границей и передача аргументов через impl Трэйт — это просто разный синтаксис для одного и того же механизма.
Чтобы продемонстрировать это, давайте перепишем пример, который мы использовали в главе Трэйты / Статическая диспетчеризация, с использованием границ генерика.
Оригинальный пример с трэйтами
trait CanIntroduce { fn introduce(&self) -> String; } struct Person { name: String } struct Dog { name: String } impl CanIntroduce for Person { fn introduce(&self) -> String { format!("Hello, I'm {}", self.name) } } impl CanIntroduce for Dog { fn introduce(&self) -> String { String::from("Waf-waf") } } fn print_introduction(v: &impl CanIntroduce) { println!("{}", v.introduce()); } fn main() { let person = Person { name: String::from("John") }; let dog = Dog { name: String::from("Bark") }; print_introduction(&person); // Hello, I'm John print_introduction(&dog); // Waf-waf }
trait CanIntroduce {
fn introduce(&self) -> String;
}
struct Person { name: String }
struct Dog { name: String }
fn create_person(name: String) -> Person {
Person { name }
}
fn create_dog(name: String) -> Dog {
Dog { name }
}
impl CanIntroduce for Person {
fn introduce(&self) -> String {
format!("Hello, I'm {}", self.name)
}
}
impl CanIntroduce for Dog {
fn introduce(&self) -> String {
String::from("Waf-waf")
}
}
fn print_introduction<T: CanIntroduce>(v: T) { // Отличие здесь
println!("{}", v.introduce ());
}
fn main() {
let person = create_person("John".to_string());
let dog = create_dog("Bark".to_string());
print_introduction(person); // Hello, I'm John
print_introduction(dog); // Waf-waf
}Как видите, это минимальное различие в синтаксисе приводит к одному и тому же результату.
Однако есть ситуации, где можно использовать только генерик с границей. Например, компилятор не позволяет написать замыкание, которое возвращает impl Трэйт, но позволит — замыкание, которое возвращает генерик с границей:
use std::fmt::Display;
fn produce_number() -> i32 {
5
}
// Так нельзя:
// fn print_produced(f: fn() -> impl Format) {
// println!("{}", f());
// }
fn print_produced<R: Display>(f: fn() -> R) {
println!("{}", f());
}
fn main() {
print_produced(produce_number);
}Также impl Трэйт синтаксис имеет существенные ограничения при описании обобщённых асинхронных функций, с которыми мы познакомимся позже.
where
Для указания границы генерика существует альтернативный синтаксис — блок where.
Без where блока
|
С where блоком
|
Блок where позволяет сделать сигнатуру функции более читабельной, так как делает объявление генерик тип-аргументов менее громоздкими.
Перепишем функцию print_introduction из предыдущего примера, с использованием блока where.
fn print_introduction<T>(v: T) where T: CanIntroduce {
println!("{}", v.introduce ());
}Блок where можно использовать не только с функциями, но и с типами:
|
генерик с границей |
блок |
Блок where особенно удобен для описания генериков, которые в своём составе имеют другие генерики. Рассмотрим пример:
use std::fmt::Display;
fn print_produced<F,R>(mut f: F)
where
F: FnMut() -> R,
R: Display
{
println!("{}", f());
}
fn main() {
let sequence_producer = {
let mut counter = 0;
move || {
counter += 1;
counter
}
};
print_produced(sequence_producer);
}Здесь функция print_produced в качестве аргумента принимает FnMut замыкание, которое возвращает значение любого типа, который реализует трэйт Display. Попытка написать эту функцию с использованием impl Трэйт синтаксиса привела бы к ошибке компиляции:
fn print_produced(mut f: impl FnMut() -> impl Display) {
println!("{}", f());
}Ошибка:
`impl Trait` is not allowed in the return type of `Fn` trait bounds
`impl Trait` is only allowed in arguments and return types of functions and methods
Специализация трэйта
Для генерик структур можно задавать методы, которые будут доступны только при мономорфизации определённым типом. Это позволяет добавить дополнительную функциональность для определённых типов.
Давайте сделаем для нашего Holder метод инкремент, который будет доступен только если объект Holder хранит i32.
struct Holder<T> {
v: T
}
impl Holder<i32> {
fn inc(&mut self) {
self.v += 1;
}
}
fn main() {
let mut h = Holder { v: 1 };
h.inc();
}Специализировать генерик можно не только под конкретный тип, но и под трэйт. Давайте сделаем метод, который будет доступен только если генерик Holder параметризирован типом, реализующим трэйт Clone.
struct Holder<T> {
v: T
}
impl<T: Clone> Holder<T> {
fn clone_value(&self) -> T {
self.v.clone()
}
}
fn main() {
let h: Holder<String> = Holder { v: "text".to_string() };
let s2: String = h.clone_value();
}const генерики
Генерики позволяют параметризировать типы и функции не только не только типами, но и константами.
Например, тип массива состоит из двух частей: тип элемента и размер массива.
#![allow(unused)]
fn main() {
let arr: [i32; 3] = [1, 2, 3];
}Поэтому если мы захотим написать генерик функцию, которая возвращает массив определённого размера, то в дополнение к генерик тип-аргументу для элементов массива нам придётся указать еще и константу для размера самого массива. Константа в генериках определяется тоже в угловых скобках, но в отличие от генерик тип-аргумента, к ней прибавляется ключевое слово const и тип константы.
<const Константа: ТипКонстанты>
Для примера напишем функцию, которая создаёт массив заданного размера, и инициализирует его элементы заданным значением:
/// Создаёт массив указанного размера, где все элементы
/// инициализированы заданным значением
fn make_array<T: Copy, const SIZE: usize>(init_value: T) -> [T; SIZE] {
[init_value; SIZE]
}
fn main() {
let arr: [i32; 5] = make_array::<i32, 5>(1);
println!("{arr:?}"); // [1, 1, 1, 1, 1]
}К значению генерик константы можно обращаться как к обычной константе. Например, напишем функцию, которая несколько раз печатает на консоль переданное в неё значение. При этом количество раз, которое значение будет напечатано на консоль, зададим const генерик-аргументом.
use std::fmt::Display;
fn print_times<const QUANTITY: usize>(v: impl Display) {
for _ in 0 .. QUANTITY {
println!("{v}");
}
}
fn main() {
print_times::<3>("Hello");
}Перечисления
Перечисления, или просто “энамы” (enums), в Rust могут иметь две формы:
- Просто перечисление значений, как в C, C++, Java и т.д.
- Контейнер типов
Рассмотрим каждую из этих форм.
Перечисление как в C
Если нам нужно перечисление как в C, то для объявления перечисления используется следующий синтаксис:
#![allow(unused)]
fn main() {
enum EnumName {
Элемент1,
Элемент2,
…,
ЭлементN
}
}Например:
enum IpAddrKind {
V4,
V6,
}
fn main() {
let ip_v4 = IpAddrKind::V4;
let ip_v6 = IpAddrKind::V6;
}Так же, как и в Си, с элементами перечисления можно ассоциировать число. Далее это число можно получить путём приведения значения типа энама к usize:
enum HttpStatus {
Ok = 200,
NotModified = 304,
NotFound = 404,
}
fn main() {
println!("{}", HttpStatus::Ok as usize); // 200
}Перечисление как объединение типов
В отличие от C, в Rust перечисление может включать в себя не только значения, но и различные типы (структуры и кортежи). При этом объект перечисления будет принадлежать одному из этих внутренних типов. То есть, объявляя enum, мы объявляем не перечень возможных значений, а перечень типов, к одному из которых должен принадлежать объект энама.
Например, IPv4 адрес кодируется 4 байтами, а IPv6-адрес — 20 байтами. При этом IPv4-адрес, как правило, записывают при помощи 4 чисел в диапазоне 0 - 255, а IPv6-адрес обычно записывают строкой. Мы можем сделать перечисление, значение которого будет представлено либо кортежем из 4 байт, либо строкой:
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
fn main() {
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
}Теперь рассмотрим пример перечисления со структурами. Напишем перечисление “фигура”, которое состоит из двух типов: квадрат и прямоугольник.
enum Shape {
Square { width: f32 },
Rectangle { width: f32, height: f32 }
}
fn main() {
let square = Shape::Square { width: 4.0 };
}Одним из преимуществ использования энамов является то, что ими удобно пользоваться в match операторе, так как компилятор заставит нас проверить все варианты перечисления.
enum Shape {
Square { width: f32 },
Rectangle { width: f32, height: f32 }
}
fn calc_area(shape: &Shape) -> f32 {
match shape { // Нужно проверить и Square, и Rectangle
Shape::Square { width } => width * width,
Shape::Rectangle { width, height } => width * height,
}
}
fn main() {
let square = Shape::Square { width: 4.0 };
println!("{}", calc_area(&square));
}Для перечислений можно добавлять методы точно так же, как и для структур:
enum Shape {
Square { width: f32 },
Rectangle { width: f32, height: f32 }
}
impl Shape {
fn calc_area(&self) -> f32 {
match self {
Shape::Square { width } => width * width,
Shape::Rectangle { width, height } => width * height,
}
}
}
fn main() {
let square = Shape::Square { width: 4.0 };
println!("{}", square.calc_area());
}Note
Перечисления в Rust основаны на, так называемых, ADT (Algebraic data type — алгебраические типы данных). Это раздел теории, которая рассматривает составные типы данных как комбинации объединений и пересечений других типов.
if-let
Как мы уже сказали, оператор match заставит нас перебрать все возможные варианты перечисления. Однако если мы заинтересованы только в одном варианте, то мы можем использовать конструкцию if-let — версия оператора if с деструктурирующим шаблоном.
if let шаблон = объект {
// здесь работаем с переменными из деструктурирующего шаблона
}Например, при помощи if-let проверим, является ли объект типа Shape квадратом:
enum Shape {
Square { width: f32 },
Rectangle { width: f32, height: f32 }
}
fn main() {
let s = Shape::Square { width: 4.0 };
if let Shape::Square { width } = s {
println!("This is square of width {width}");
}
}Разумеется, у if-let, как и у обычного if, может быть else ветка.
Лэйаут в памяти
При помощи энамов мы фактически можем хранить значения разных типов в массиве.
enum MyEnum {
Byte(u8),
UInt(u32),
}
fn main() {
let arr = [MyEnum::Byte(1), MyEnum::UInt(5)];
}Это достигается за счёт того, что под элементы энама резервируется такое количество памяти, которое необходимо для записи наибольшего из возможных вариантов перечисления. То есть за гибкость приходится платить потенциальным перерасходом памяти.
Также, кроме непосредственно самого значения, каждый объект энама содержит дискриминатор — число (может быть размером от u8 до u32), которое позволяет узнать, какой именно из вариантов перечисления хранится в данном объекте.
Массив из примера выше выглядит в памяти примерно так:
┏━━━━━━━━━━━━━┯━━━━━━━━━━━┯━━━━━━━━━━━━┳━━━━━━━━━━━━━┯━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃дискриминатор┆u8 значение┆пустое место┃дискриминатор┆ u32 значение ┃ ┗━━━━━━━━━━━━━┷━━━━━━━━━━━┷━━━━━━━━━━━━┻━━━━━━━━━━━━━┷━━━━━━━━━━━━━━━━━━━━━━━━┛
Именно дискриминатор проверяют операторы match и let-if, когда проверяют, к какому внутреннему типу относится объект перечисления.
Еще раз про перечисление “как в C”
Теперь, когда мы знаем, как устроены перечисления, мы можем ещё раз взглянуть на самый первый пример из этой главы и понять, как он устроен.
#![allow(unused)]
fn main() {
enum IpAddrKind {
V4,
V6,
}
}С семантической точки зрения V4 и V6 — это никакие не значения, а просто синглтон структуры. Соответственно, в памяти объекты таких перечислений, представлены только дискриминатором.
Более того, когда мы присваиваем элементам перечисления некое числовое значение, то мы просто задаём конкретные значения для дискриминатора.
#![allow(unused)]
fn main() {
enum HttpStatus {
Ok = 200, // дискриминатор = 200
NotModified = 304, // дискриминатор = 304
NotFound = 404, // дискриминатор = 404
}
}Option
К этому моменту мы уже разобрались со всеми основными языковыми конструкциями. Однако чтобы завершить изучение основ языка, нам всё еще нужно рассмотреть несколько стандартных типов, которые очень тесно связаны с самим языком Rust, а также пронизывают всю его стандартную библиотеку.
Первым мы рассмотрим наиболее часто используемый тип — Option.
Предыстория
При написании реальных программ часто возникает ситуация, когда необходимо каким-то образом обозначить отсутствие значения. Например, для хранения полного имени человека (имя, фамилия и отчество) мы можем создать структуру вида:
#![allow(unused)]
fn main() {
struct FullName {
first_name: String,
last_name: String,
middle_name: String,
}
}Однако есть ситуации, когда отчество может отсутствовать, и это надо как-то отобразить в коде.
Другой вездесущий пример связан с операциями ввода/вывода: читая данные из внешнего источника, мы никогда не можем гарантировать, что получим все ожидаемые значения. Например, мы запрашиваем из базы данных значение записи по её ID, однако такой записи в БД может просто не существовать.
Традиционно в императивных языках предыдущих поколений эта проблема решается одним из трёх способов:
Способ 1. Резервирование одного из значений, чтобы обозначить отсутствие значения. Например, использовать -1 для отсутствующего ID или пустую строку для отсутствующего отчества. Этот подход очень широко распространён в стандартной библиотеке C и различных системных API. Его недостатком является то, что, во-первых, не всегда можно выделить значение, которое будет индикатором отсутствия значения, а во-вторых, пользователь API должен знать о таком соглашении.
Способ 2. Введение дополнительного флага — булевого поля, которое указывает, что другое поле “пусто”. Например:
#![allow(unused)]
fn main() {
struct FullName {
first_name: String,
last_name: String,
middle_name: String,
is_middle_name_empty: bool,
}
}Этот подход лишён недостатка, связанного с необходимостью выделения “пустого” значения, однако для написания логики программы он крайне неудобен.
Способ 3. Использование нулевого указателя как индикатора отсутствия значения. Этот подход хоть и удобен, но является причиной самой распространённой ошибки в программах на C — ошибка сегментации (и на Java — NullPointerException). К тому же такой подход требует размещения значений в куче, что может негативно сказаться на производительности программы.
Option для “пустых” значений
Для представления отсутствующих значений в Rust используется тип Option, который объявлен так:
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Как мы видим, это обобщённый перечислимый тип, состоящий из:
- обобщённой кортежной структуры
Some(T) - структуры синглтона
None
Давайте разбираться, как работать с Option.
Допустим, мы хотим сделать переменную типа i32, которая может быть “пустой”.
#![allow(unused)]
fn main() {
let mut maybe_i32: Option<i32>;
maybe_i32 = Some(5); // Записываем в переменную значение
maybe_i32 = None; // А теперь переменная "пуста"
}С помощью Option мы можем переписать наш пример структуры для хранения полного имени следующим образом:
#![allow(unused)]
fn main() {
struct FullName {
first_name: String,
last_name: String,
middle_name: Option<String>,
}
}Другой пример: функция, которая возвращает запись из базы данных по её ID, может иметь вид:
fn get_record_by_id(id: u64) -> Option<Record> { ... }Как мы видим, Option позволяет хранить потенциально пустое значение, при этом:
- не выделять какое-то из возможных значений для индикации отсутствия значения
- не вводить дополнительных неудобных флагов, потому что
Option— enum, и он уже содержит в себе этот флаг (дискриминатор) - не бояться получить ошибку обращения по нулевому указателю
Извлечение значения из Option
Теперь давайте разберёмся, как извлекать значение из Option.
Самый прямолинейный способ — метод unwrap, который работает следующим образом:
- если опшион содержит значение, т.е. является объектом типа
Some(T), то методunwrapвернёт значение, хранящееся в нём - в противном случае программа завершится с паникой.
fn main() {
let o: Option<i32> = Some(5);
let i: i32 = o.unwrap();
}Очевидно, что использовать метод unwrap очень небезопасно, поэтому существует метод unwrap_or, который позволяет задать значение по умолчанию на случай, если опшион “пуст”.
fn main() {
let o: Option<i32> = None;
let i: i32 = o.unwrap_or(1); // 1
}Другим способом извлечения значения является использование оператора match.
fn main() {
let o: Option<i32> = Some(5);
let i: i32 = match o {
Some(v) => v,
None => 1,
};
}Разумеется, нам не обязательно возвращать значение из оператора match, если того не требует логика нашей программы. Например, мы можем просто напечатать различный вывод:
fn main() {
let o: Option<i32> = Some(5);
match o {
Some(v) => println!("Number is {v}"),
None => println!("Number is empty"),
};
}Также вместе с Option очень удобно использовать оператор if-let.
fn main() {
let o: Option<i32> = Some(5);
if let Some(v) = o {
println!("Number is {v}");
} else {
println!("Number is empty");
};
}Комбинаторы Option
Стиль работы с Option на первый взгляд может показаться слегка громоздким, однако у Option есть целый ряд удобных комбинаторов, которые позволяют сделать работу с ним проще и выразительнее.
Первый комбинатор — метод map (“отобразить”) позволяет преобразовать значение опшиона, если оно существует, или не сделать ничего, если опшион пуст. В качестве аргумента метод map принимает замыкание (или указатель на функцию), которое применяет к значению внутри Option, если оно — Some.
┌─────────┐ ┌─────────┐ │Option │ .map(|x| x+1) │Option │ │ │ │ │ │ │┌───────┐│ V │┌───────┐│ ││Some(5)├───────> 5+1 ────>│Some(6)││ │└───────┘│ │└───────┘│ └─────────┘ └─────────┘ ┌─────────┐ ┌─────────┐ │Option │ .map(|x| x+1) │Option │ │ │ │ │ │┌───────┐│ │┌───────┐│ ││ None ├─────────────────>│ None ││ │└───────┘│ │└───────┘│ └─────────┘ └─────────┘
Пример:
fn main() {
let s1: Option<i32> = Some(5);
let s2: Option<i32> = s1.map(|a| { a + 1 });
println!("{s2:?}"); // Some(6)
let e1: Option<i32> = None;
let e2: Option<i32> = e1.map(|a| { a + 1 });
println!("{e2:?}"); // None
}Более приближенный к жизни пример: есть функция, которая извлекает из базы данных объект пользователя по его ID. Если объект пользователя с заданным ID существует в БД, то мы берём из него значение поля “имя”.
struct User {
id: u64,
name: String,
}
fn get_user_by_id(id: u64) -> Option<User> {
// Запрос в БД
}
fn get_user_name_by_id(id: u64) -> Option<String> {
get_user_by_id(id)
.map(|user| user.name)
}Другой комбинатор — метод flatten (“сгладить”) преобразует двойную обёртку Option<Option<T>> в Option<T>.
fn main() {
let o1: Option<i32> = Some(1);
let o2: Option<Option<i32>> = o1.map(|a| Some(a + 1)); // Some(Some(2))
let o3: Option<i32> = o2.flatten(); // Some(2)
}Этот комбинатор может понадобиться, когда в нашей логике присутствует несколько Option значений. Например, мы хотим получить отчество, которого может не быть, из объекта пользователя в БД, который может отсутствовать.
struct User {
id: u64,
first_name: String,
last_name: String,
middle_name: Option<String>,
}
fn get_user_by_id(id: u64) -> Option<User> {
// Запрос в БД
}
fn get_user_middle_name_by_id(id: u64) -> Option<String> {
get_user_by_id(id)
.map(|user| user.middle_name)
.flatten()
}Метод and_then работает как комбинация map и flatten: он сначала применяет к содержимому опшиона функцию, которая возвращает Option, а затем “сглаживает” два опшиона в один.
fn main() {
let o1: Option<i32> = Some(1);
let o2: Option<i32> = o1.and_then(|a| Some(a + 1)); // Some(2)
}Result
Рассмотрим еще один вездесущий тип — перечисление Result.
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}Как мы видим, Result чем-то напоминает Option, только если Option хранит либо значение, либо “пустоту”, то Result хранит либо значение, либо ошибку.
Result используется в качестве типа результата для функций, которые могут завершиться с ошибкой.
Давайте рассмотрим простейший пример:
fn square_root(num: f32) -> Result<f32, String> {
if num < 0.0 {
Err("Cannot calculate for negative number".to_string())
} else {
Ok(num.sqrt())
}
}
fn main() {
println!("sqrt(-4) = {:?}", square_root(-4.0));
// sqrt(-4) = Err("Cannot calculate for negative number")
println!("sqrt(4) = {:?}", square_root(4.0));
// sqrt(4) = Ok(2.0)
}Функция square_root извлекает квадратный корень из переданного ей аргумента. Если аргумент имеет неотрицательное значение, то она возвращает Ok(значение), иначе — Err (так как в арифметике нельзя извлекать корень из отрицательных чисел).
Извлечение значения из Result очень похоже на извлечение значения из Option:
- методом
unwrap/unwrap_or - оператором
match - оператором
if-let
fn square_root(num: f32) -> Result<f32, String> {
if num < 0.0 {
Err("Cannot calculate for negative number".to_string())
} else {
Ok(num.sqrt())
}
}
fn main() {
match square_root(-4.0) {
Ok(v) => println!("sqrt(-4)={v}"),
Err(e) => println!("Cannot calculate sqrt(-4): {e}"),
}
let v = square_root(4.0).unwrap_or(0.0);
println!("sqrt(4)={v}");
}Представление ошибок
В примере выше в качестве ошибки мы использовали просто строку с описанием проблемы. Разумеется, такой подход крайне неудобен для программной обработки ошибки. Гораздо удобнее хранить информацию об ошибке в перечислении, в котором каждый элемент представляет отдельную проблему.
Для примера напишем функцию, которая принимает строку, содержащую ФИО, и возвращает отчество.
#[derive(Debug)]
enum NameParseError{
EmptyString, // Попытка парсить пустую строку
NoMiddleName, // Строка не содержит отчество
}
// Принимает строку, содержающую имя, отчество и фамилию, разделённые
// символом пробела, и возвращает либо отчество, либо ошибку.
fn get_middle_name(full_name: &str) -> Result<String, NameParseError> {
if full_name.is_empty() {
return Err(NameParseError::EmptyString);
}
let mut words = split_to_words(full_name);
if words.len() < 3 {
return Err(NameParseError::NoMiddleName);
}
let middle_name = words.remove(1);
Ok(middle_name)
}
// Эта функция разбивает строку на слова.
// В стандартной библиотеке для этого имеется готовая функциональность,
// но мы пока не готовы её использовать.
fn split_to_words(text: &str) -> Vec<String> {
let mut words: Vec<String> = Vec::new();
let mut current_word = String::new();
for c in text.chars() {
if c.is_whitespace() {
if !current_word.is_empty() {
words.push(current_word);
current_word = String::new();
}
} else {
current_word.push(c);
}
}
if !current_word.is_empty() {
words.push(current_word);
}
words
}
fn main() {
let m_name_1 = get_middle_name("");
println!("{m_name_1:?}"); // Err(EmptyString)
let m_name_2 = get_middle_name("John Doe");
println!("{m_name_2:?}"); // Err(NoMiddleName)
let m_name_3 = get_middle_name("Сергей Петрович Иванов");
println!("{m_name_3:?}"); // Ok("Петрович")
}Трэйт Error
Как мы сказали, тип Result позволяет использовать любой тип для представления ошибки.
Однако стандартная библиотека предоставляет трэйт std::error::Error, который создан специально для типов, используемых в качестве ошибки в Result:
#![allow(unused)]
fn main() {
pub trait Error: Debug + Display {
// Если данная ошибка является обёрткой для другой ошибки,
// то этот метод возвращает оборачиваемую ошибку.
fn source(&self) -> Option<&(dyn Error + 'static)> { ... }
// Устаревший, используйте fmt::Debug вместо него
fn description(&self) -> &str { ... }
// Устаревший, используйте source
fn cause(&self) -> Option<&dyn Error> { ... }
// Доступен только в ночной сборке RustSDK
fn provide<'a>(&'a self, request: &mut Request<'a>) { ... }
}
}Этот трэйт используется для унификации ошибок. Все типы ошибок из API стандартной библиотеки Rust реализуют std::error::Error.
Давайте реализуем трэйт Error для типа ошибки из секции Представление ошибок.
#![allow(unused)]
fn main() {
#[derive(Debug)]
enum NameParseError{
EmptyString,
NoMiddleName,
}
impl std::fmt::Display for NameParseError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
NameParseError::EmptyString =>
write!(f, "Attempt to parse empty string"),
NameParseError::NoMiddleName =>
write!(f, "No middle name found"),
}
}
}
impl std::error::Error for NameParseError {}
}После этого нашу ошибку можно будет связывать в цепочку с другими ошибками из стандартной библиотеки.
Note
Подобной ручной реализацией трэйта
std::error::Errorзанимаются очень редко, так как в экосистеме Rust есть библиотеки, заметно упрощающие этот процесс. Но о них мы поговорим позже.
Композиция объектов Result
Давайте взглянем на простую программу, которая печатает на консоль текстовый файл.
Note
Мы еще не разбирали API для работы с файловой системой и сделаем это только в главе Файловая система. Однако если вы хотя бы раз работали с файловой системой на других языках программирования, то этот код должен выглядеть понятным:
use std::fs::File;
use std::io::{Error, prelude::*};
/// Функция, которая читает содержимое текстового файла с заданным именем,
/// и возвращает содержимое файла в виде объекта строки.
fn read_text_file(file_name: &str) -> Result<String, Error> {
// Открытие файла
let mut file = match File::open(file_name) {
Ok(file) => file,
Err(e) => return Err(e),
};
// Создание строки буфера, в которую будет произведено считывание
let mut contents = String::new();
// Читаем содержимое файла в строку
match file.read_to_string(&mut contents) {
Ok(read_bytes) => Ok(contents),
Err(e) => return Err(e),
}
}
fn main() {
// Файл /etc/fstab присутствует в каждой Linux системе.
// Если у вас Windows, то замените его на путь к любому текстовому файлу
match read_text_file("/etc/fstab") {
Ok(txt) => println!("{}", txt),
Err(e) => println!("Failed, because {}", e)
}
}Нетрудно заметить, что в функции read_text_file шаблонного кода, пробрасывающего ошибку, не меньше, чем “полезного”. Можно ли как-то улучшить ситуацию?
Тип Result, подобно типу Option, имеет комбинаторы map и and_then. Используя их, мы можем переписать функцию read_text_file так:
use std::fs::File;
use std::io::{Error, prelude::*};
fn read_text_file(file_name: &str) -> Result<String, Error> {
File::open(file_name).and_then(|mut file| {
let mut contents = String::new();
file.read_to_string(&mut contents).map(|_| {
contents
})
})
}
fn main() {
match read_text_file("/etc/fstab") {
Ok(txt) => println!("{}", txt),
Err(e) => println!("Failed, because {}", e)
}
}Такой вариант read_text_file значительно короче, однако теперь он потерял в читабельности.
К счастью, Rust предоставляет специальный оператор ?, который позволяет и сохранить линейность кода, и избавиться от шаблонного пробрасывания ошибки. Этот оператор работает так:
- если объект типа
ResultсодержитOk(значение), то значение просто извлекается - если объект типа
ResultсодержитErr(ошибка), то функция завершает свою работу, а ошибка возвращается из функции.
use std::fs::File;
use std::io::{Error, prelude::*};
fn read_text_file(file_name: &str) -> Result<String, Error> {
let mut file = File::open(file_name)?;
let mut contents = String::new();
file.read_to_string(&mut contents)?;
Ok(contents)
}
fn main() {
match read_text_file("/etc/fstab") {
Ok(txt) => println!("{}", txt),
Err(e) => println!("Failed, because {}", e)
}
}Как видите, благодаря оператору ?, код функции стал абсолютно линейным: словно у нас и нет никакой обёртки Result. При этом ни одна ошибка не осталась незамеченной. Именно благодаря этой мощной комбинации типа Result, трэйта Error и оператора ? в Rust удобно работать с ошибками, несмотря на то что в языке отсутствует механизм исключений.
Разумеется, оператор ? можно использовать только внутри функций, которые сами возвращают Result.
Игнорирование Result
Если мы вызываем функцию, которая возвращает Result, и при этом не присваиваем её результат какой-то переменной и не проверяем Result на наличие ошибки, то компилятор выдаст предупреждение, так как будет считать, что мы просто забыли проверить результат на возможную ошибку.
Если мы сознательно хотим проигнорировать результат, то следует его явно отбросить путём присваивания “выброшенной” переменной — let _ = .
Например:
fn function_that_may_fail() -> Result<(), String> {
Err("Something is wrong".to_string())
}
fn main() {
let _ = function_that_may_fail();
}Итераторы
Как мы знаем, цикл for можно использовать для перебора элементов разных типов: массив, слайс, вектор, диапазон и т.д. Но за счёт чего достигается такая гибкость?
Дело в том, что цикл for умеет перебирать только итераторы, которые, в свою очередь, являются единым интерфейсом для работы с последовательностями. Итератор представлен трэйтом Iterator.
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// ... более 70 других методов
}
}Фактически, итератор определяет интерфейс, который позволяет последовательно перебирать объекты в некой коллекции (массив, слайс, вектор), с которой итератор связан.
Самый главный метод этого трэйта — next, который возвращает:
- либо следующий элемент в перебираемой последовательности в форме
Some(значение) - либо
None, если все элементы перебраны
Именно метод next используется циклом for для получения следующего элемента.
Note
Следует отметить, что обычно трэйт
Iteratorреализуется не для типа самой коллекции (массив, вектор и т.д.), а для отдельного типа, чей объект используется для перебора элементов в связанной с итератором коллекции (массиве, векторе и т.д.).

Делаем итератор
Чтобы было проще разобраться, давайте создадим свой итератор для вектора. Стандартная библиотека уже содержит стандартную реализацию итератора для вектора — тип Iter. Поэтому чтобы не смущать компилятор попытками понять, какую же реализацию итератора он должен использовать (стандартную или нашу), мы сделаем обёртку над вектором.
struct MyVec<T>(Vec<T>);Теперь сделаем итератор для нашей обёртки:
struct MyVecIter<'a, T> {
data: &'a MyVec<T>,
current_ind: usize,
}
impl <'a, T> Iterator for MyVecIter<'a, T> {
type Item = &'a T;
fn next(&mut self) -> Option<Self::Item> {
if self.current_ind < self.data.0.len() {
let current_element = &self.data.0[self.current_ind];
self.current_ind += 1;
Some(current_element)
} else {
None
}
}
}Наш итератор — просто структура, которая хранит ссылку на объект MyVec и индекс того элемента, который будет извлечен при вызове next().
Если индекс еще не вышел за границы итерируемого вектора, то мы возвращаем ссылку на элемент, находящийся по этому индексу, после чего инкрементируем индекс. Если индекс вышел за границы вектора, то возвращаем None, который служит сигналом того, что итерация завершена.
Пример использования нашего итератора:
struct MyVec<T>(Vec<T>);
struct MyVecIter<'a, T> {
data: &'a MyVec<T>,
current_ind: usize,
}
impl <'a, T> Iterator for MyVecIter<'a, T> {
type Item = &'a T;
fn next(&mut self) -> Option<Self::Item> {
if self.current_ind < self.data.0.len() {
let current_element = &self.data.0[self.current_ind];
self.current_ind += 1;
Some(current_element)
} else {
None
}
}
}
fn main() {
let my_vec = MyVec(vec![1,2,3]);
let iterator = MyVecIter { data: &my_vec, current_ind: 0 };
for n in iterator {
print!("{n} ");
}
// Напечатает: 1 2 3
}Разумеется, создавать объект итератора вот так вручную — очень неудобно. Поэтому в коллекцию, по которой можно итерироваться, часто добавляют метод iter(), который сам конструирует итератор.
impl <T> MyVec<T> {
// Возвращает итератор для нашей обёртки MyVec
fn iter(&self) -> MyVecIter<'_, T> {
MyVecIter { data: self, current_ind: 0 }
}
}Теперь итерироваться циклом for гораздо удобнее:
struct MyVec<T>(Vec<T>);
impl <T> MyVec<T> {
fn iter(&self) -> MyVecIter<'_, T> {
MyVecIter { data: self, current_ind: 0 }
}
}
struct MyVecIter<'a, T> {
data: &'a MyVec<T>,
current_ind: usize,
}
impl <'a, T> Iterator for MyVecIter<'a, T> {
type Item = &'a T;
fn next(&mut self) -> Option<Self::Item> {
if self.current_ind < self.data.0.len() {
let current_element = &self.data.0[self.current_ind];
self.current_ind += 1;
Some(current_element)
} else {
None
}
}
}
fn main() {
let my_vec = MyVec(vec![1,2,3]);
for n in my_vec.iter() {
print!("{n}, ");
}
}Tip
Имя метода
iter()не регламентировано никаким трейтом и является просто понятным общепринятым именем.
Цикл for и итераторы
Теперь, когда мы выяснили, что цикл for на самом деле работает только с итераторами, давайте выясним, как же цикл for итерируется непосредственно по вектору.
Всё просто: цикл for принимает либо непосредственно итератор, либо тип, который реализует трэйт IntoIterator.
pub trait IntoIterator {
// Тип элемента итератора
type Item;
// Тип итератора
type IntoIter: Iterator<Item = Self::Item>;
// Возвращает объект итератора
fn into_iter(self) -> Self::IntoIter;
}Этот трэйт реализуется типом самой коллекции и позволяет ей создать объект итератора по своим элементам.
То есть если мы хотим передавать объект MyVec в цикл for непосредственно, то мы должны реализовать для него трэйт IntoIterator. Давайте сделаем это.
impl <'a, T> IntoIterator for &'a MyVec<T> {
type Item = &'a T;
type IntoIter = MyVecIter<'a, T>;
fn into_iter(self) -> Self::IntoIter {
MyVecIter { data: self, index: 0 }
}
}Поскольку мы итерируемся по элементам через ссылку, а не по значению, то IntoIterator мы реализуем не для MyVec, а для ссылки &MyVec.
Теперь, когда IntoIterator определён, мы можем итерироваться по объекту MyVec так:
struct MyVec<T>(Vec<T>);
struct MyVecIter<'a, T> {
data: &'a MyVec<T>,
index: usize,
}
impl <T> MyVec<T> {
fn iter(&self) -> MyVecIter<'_, T> {
MyVecIter { data: self, index: 0 }
}
}
impl <'a, T> Iterator for MyVecIter<'a, T> {
type Item = &'a T;
fn next(&mut self) -> Option<Self::Item> {
if self.index < self.data.0.len() {
let current_element = &self.data.0[self.index];
self.index += 1;
Some(current_element)
} else {
None
}
}
}
impl <'a, T> IntoIterator for &'a MyVec<T> {
type Item = &'a T;
type IntoIter = MyVecIter<'a, T>;
fn into_iter(self) -> Self::IntoIter {
self.iter()
}
}
fn main() {
let my_vec = MyVec(vec![1,2,3]);
for n in &my_vec {
print!("{n}, ");
}
}А можно ли итерироваться по элементам нашей обёртки не по ссылке, а по значению? Да, однако нам придётся написать второй итератор, который будет захватывать нашу обёртку по значению:
struct MyVec<T>(Vec<T>);
struct MyVecIterVal<T> {
data: MyVec<T>,
}
impl <T> MyVec<T> {
fn iter_val(self) -> MyVecIterVal<T> {
MyVecIterVal { data: self }
}
}
impl <T> Iterator for MyVecIterVal<T> {
type Item = T;
fn next(&mut self) -> Option<Self::Item> {
self.data.0.pop() // извлекаем и возвращаем первый элемент
}
}
impl <T> IntoIterator for MyVec<T> {
type Item = T;
type IntoIter = MyVecIterVal<T>;
fn into_iter(self) -> Self::IntoIter {
self.iter_val()
}
}
fn main() {
let my_vec = MyVec(vec![1,2,3]);
for n in my_vec {
print!("{n}, ");
}
}Еще раз про итерирование по вектору
Теперь, когда мы познакомились с трэйтами Iterator и IntoIterator, давайте посмотрим на несколько примеров итерирования по уже знакомым типам.
let v = vec![1, 2, 3];
// Метод iter() определен для типа Vec.
// Он явно возвращает объект итератора, который перебирает ссылки на элементы
// Тип i: &i32
for i in v.iter() { }
// На объекте &Vec будет неявно вызван метод into_iter(),
// который вернёт итератор. Тип i: &i32
for i in &v { }
// Явный вызов into_iter() для объекта Vec. Вернёт итератор для перебора
// элементов по значению, т.е. итерирование "поглотит вектор". Тип i: i32
for i in v.into_iter() { }
// Неявно вызовет into_iter() для объекта Vec.
for i in v { }Точно такая же картина и для массивов:
let arr = [1, 2, 3];
// Перебор по ссылке - i: &i32
for i in arr.iter() { }
// Перебор по ссылке - i: &i32
for i in &arr { }
// Перебор по значению - i: i32
for i in arr.into_iter() { }
// Перебор по значению - i: i32
for i in arr { }Резюмируя:
- если мы хотим проитерироваться по коллекции, перебирая значения по ссылке, тогда следует передавать в оператор
forлибо ссылку на коллекцию, либо вызывать на объекте коллекции методiter()(если таков имеется). - если нам нужны именно значения элементов (и нам подходит разрушение самой коллекции), то следует передавать в оператор
forлибо объект коллекции непосредственно, либо вызвать методinto_iter()
Range
В главе Циклы мы видели такую форму перебора чисел:
#![allow(unused)]
fn main() {
for i in 0 .. 20 {
println!("{i}");
}
}Наконец-то мы готовы разобраться с тем, как это работает.
Дело в том, что оператор .. создаёт диапазон — объект структуры Range, которая имеет вид:
pub struct Range<Idx> {
pub start: Idx, // начальный элемент диапазона
pub end: Idx, // конечный элемент диапазона
}Как мы видим, Range просто хранит начальное и конечное значения диапазона. При этом тип Range реализует интерфейс Iterator, что позволяет итерироваться по его элементам.
При желании мы можем использовать Range и без цикла for.
use std::ops::Range;
fn main() {
let mut range: Range<i32> = 0..20;
println!("{:?}", range.next()); // Some(0)
println!("{:?}", range.next()); // Some(1)
}Note
В начале главы мы сказали, что
Iteratorобычно реализуется не для самой коллекции, а для отдельного типа, который используется для перебора элементов этой коллекции. ТипRangeявляется одним из исключений, так как трэйтIteratorреализован непосредственно для него самого. При этом итерирование реализовано просто инкрементированием поляstart.
API итераторов
Как мы заметили в самом начале, в трэйте Iterator, кроме метода next(), определено еще более 70 методов, которые имеют реализацию по умолчанию. Что же это за методы?
Это методы, позволяющие декларативно обрабатывать и преобразовывать коллекции.
Tip
Программисты на Java могут провести аналогию с Stream API, а программисты на C# — с Linq.
Начнём с примера: у нас имеется вектор чисел, и мы хотим:
- Взять из него только чётные числа.
- Далее каждое из этих чётных чисел возвести в квадрат.
#![allow(unused)]
fn main() {
let v1 = vec![1,2,3,4,5];
let v2 = v1.into_iter() // Превращаем вектор в итератор
.filter(|x| x % 2 == 0) // фильтруем только чётные элементы
.map(|x| x * x) // возводим элементы в квадрат
.collect::<Vec<_>>(); // перепаковываем итератор в вектор
println!("{v2:?}"); // [4, 16]
}Давайте подробно разберём этот пример.
1) Сначала мы получаем итератор для вектора. Так как после завершения обработки нам больше не нужен оригинальный вектор, мы используем метод into_iter(), который создаст итератор, перебирающий элементы вектора по значению, а значит, оригинальный вектор будет “поглощён”.
2) На полученном итераторе мы вызываем метод filter, который имеет вид:
#![allow(unused)]
fn main() {
fn filter<P>(self, predicate: P) -> Filter<Self, P>
where Self: Sized, P: FnMut(&Self::Item) -> bool
{
Filter::new(self, predicate)
}
}Как мы видим, этот метод принимает некий предикат и возвращает объект Filter.
#![allow(unused)]
fn main() {
pub struct Filter<I, P> {
pub(crate) iter: I,
predicate: P,
}
}Тип Filter — это обёртка над итератором, которая хранит в себе итератор и предикат, которым его надо профильтровать. И разумеется, тип Filter тоже реализует трэйт Iterator.
3) Уже на объекте Filter мы вызываем другой метод, определённый в трэйте Iterator — метод map:
#![allow(unused)]
fn main() {
fn map<B, F>(self, f: F) -> Map<Self, F>
where Self: Sized, F: FnMut(Self::Item) -> B,
{
Map::new(self, f)
}
}Как видим, этот метод очень напоминает filter, за исключением того, что он возвращает объект типа Map, который объявлен так:
#![allow(unused)]
fn main() {
pub struct Map<I, F> {
pub(crate) iter: I,
f: F,
}
}То есть Map — это обёртка над итератором, которая хранит функцию, при помощи которой нужно преобразовать элементы обёрнутого итератора.
4) На объекте Map мы вызываем метод collect(), определённый в трэйте Iterator, и только в этот момент начинается раскрутка обёрток и вычисление результата.
Каким будет тип результата, зависит от генерик тип-аргумента метода collect().
Эта “матрёшка” из вектор-итератора, завёрнутого в Filter, и завёрнутого в Map, выглядит примерно так:

В примере выше мы обработали вектор и получили результат тоже в форме вектора (так как в метод collect передали тип-аргумент Vec). Если бы мы хотели получить результирующие элементы в виде, например, HashSet (хеш-множество — мы поговорим о нём позже), то просто должны были бы указать этот вид коллекции в методе collect().
use std::collections::HashSet;
fn main() {
let v1: Vec<i32> = vec![1,2,3,4,5];
let v2: HashSet<i32> = v1.into_iter()
.filter(|x| x % 2 == 0)
.map(|x| x * x)
.collect::<HashSet<_>>();
println!("{v2:?}"); // {16, 4}
}Для большинства коллекций из стандартной библиотеки можно получить итератор, и большинство коллекций из стандартной библиотеки могут быть построены из итератора методом collect. Получается, что итератор — универсальное API для обработки и преобразования типов-коллекций.

Большинство коллекций из сторонних библиотек также работают вместе с итераторами.
Свёртки
Итератор не обязательно использовать для создания другой коллекции, он также позволяет “сворачивать” (агрегировать) элементы. Для этого трэйт Iterator предоставляет метод fold:
fn fold<B, F>(mut self, init: B, mut f: F) -> B
where F: FnMut(B, Self::Item) -> B
{ ... }Этот метод принимает два аргумента:
- начальное значение, с которым мы будем “сворачивать” (агрегировать)
- агрегирующую функцию, которая принимает уже предагрегированное значение и следующий элемент из итератора, и возвращает результат агрегации
Для примера давайте суммируем элементы массива при помощи свёртки.
#![allow(unused)]
fn main() {
let arr = [1, 2, 3];
let sum = arr.into_iter()
.fold(0, |x, y| x + y);
println!("{sum}"); // 6
}Здесь свёртка происходит примерно так:

Возможно, у вас появился вопрос: а для чего нам начальное значение 0, если в качестве начального значения агрегации мы просто могли использовать первый элемент?
Во-первых, на самом деле в трэйте Iterator есть метод reduce, который работает практически так же, как и fold, только в качестве начального значения берётся как раз первый элемент.
fn main() {
let arr = [1, 2, 3];
let sum: Option<i32> = arr.into_iter()
.reduce(|x, y| x + y);
println!("{sum:?}"); // Some(6)
}(reduce возвращает Option, так как в сворачиваемой коллекции может вообще не быть элементов)
А во-вторых, при использовании fold, результат агрегации может иметь тип, отличный от типа итерируемых элементов. Например, при помощи fold мы можем проитерироваться по массиву строк и подсчитать количество символов во всех строках:
#![allow(unused)]
fn main() {
let arr = ["aa", "bbb", "cccc"];
let char_count = arr.iter()
.fold(0, |count, s| count + s.len());
println!("{char_count}"); // 9
}Также следует заметить, что для итератора определён ряд специализаций.
Например, для итератора с элементами числового типа, имеется дополнительный метод sum, который считает сумму всех элементов:
fn main() {
let arr = [1, 2, 3];
let sum: i32 = arr.into_iter().sum();
println!("{sum}");
}Другие методы
filter_map
Метод filter_map работает как обычный map, однако функция-преобразователь, которую он принимает в качестве аргумента, должна возвращать значение, завёрнутое в Option.
- Если функция-преобразователь после применения к очередному элементу вернёт
Some(значение), то значение будет автоматически извлечено и пойдёт “дальше по конвейеру итератора”. - Если функция-преобразователь вернёт
None, то этотNoneбудет просто отброшен.
Пример: получение квадратных корней всех элементов, из которых можно извлечь корень.
fn safe_sqrt(n: f32) -> Option<f32> {
if n < 0.0 {
None
} else {
Some(n.sqrt())
}
}
fn main() {
let arr = [4.0, -25.0, 9.0];
let result = arr.into_iter()
.filter_map(safe_sqrt)
.collect::<Vec<_>>();
println!("{result:?}"); // [2.0, 3.0]
}find
Метод find принимает предикат и возвращает первый элемент, который удовлетворяет этому предикату.
Пример: поиск первого чётного элемента.
#![allow(unused)]
fn main() {
let arr = [1, 3, 5, 7, 8, 9];
let first_even: Option<i32> = arr.into_iter()
.find(|x| x % 2 == 0);
println!("{first_even:?}");
}Метод возвращает значение, завёрнутое в Option, так как есть вероятность, что ни один элемент не удовлетворит предикату.
Tip
В трэйте
Iteratorопределено много полезных методов, тем не менее на практике вам, скорее всего, окажется их недостаточно. Однако существует замечательная библиотека itertools, которая предлагает целое множество дополнительных методов.
Умные указатели
До этого момента явно мы работали только с данными, размещаемыми на стеке. Мы, конечно, рассмотрели много примеров с векторами и строками, которые хранят свои элементы в куче, однако эти типы инкапсулируют работу с кучей в себе, полностью скрывая от нас все детали. В этой же главе мы явно разберём работу с кучей при помощи умных указателей.
Note
Умный указатель (smart pointer) — термин, пришедший из C++, где, в отличие от C, в котором указатель является просто ячейкой, хранящей в себе адрес, умный указатель представляет из себя класс, который не просто предоставляет доступ к данным по адресу, но и умеет автоматически очищать память, на которую он ссылается.
Box
Первым указателем, который мы рассмотрим, является Box. Мы уже вскользь упоминали его в разделе Возврат трэйта из функции.
Box<T> — это обобщённый тип, который хранит адрес значения типа T, размещённого в куче. Box является владельцем данных в куче, т.е. при выходе переменной Box из скоупа происходит автоматическое освобождение соответствующей памяти в куче.
Tip
Проводя аналогию с C++,
Boxявляется прямым аналогом умного указателяunique_ptr.
С точки зрения лэйаута в памяти, Box является так называемой “zero cost abstraction”. То есть представляет из себя просто ячейку с адресом, которая располагается на стеке, и не более.
┌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┐ ┌╌╌╌╌╌╌╌╌┐ ┆Stack ┆ ┆Heap ┆ ┆ ┌────────────┐ ┆ ┆ ┌────┐ ┆ ┆ │Box: pointer├────────>│Data│ ┆ ┆ └────────────┘ ┆ ┆ └────┘ ┆ └╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┘ └╌╌╌╌╌╌╌╌┘
Наиболее простой способ создать Box — использовать метод-конструктор Box::new(T), который принимает в качестве аргумента значение и переносит это значение в кучу.
Рассмотрим пример:
// Структура для хранения координат точки в двухмерном пространстве
struct Point2D { x: i32, y: i32 }
fn main() {
let p: Point2D = Point2D {x: 5, y: 2}; // Создаём значение на стеке
let b: Box<Point2D> = Box::new(p); // Перемещаем значение в кучу
}Чем же нам может быть полезно такое хранение значений в куче? Дело в том, что для того, чтобы значение можно было хранить на стеке, его размер должен быть известен во время компиляции. Например, как со структурой Point2D: размер значения всегда будет одинаковым (два поля размером i32). Однако полный размер таких структур, как вектор, не известен на этапе компиляции, потому что количество элементов вектора не известно.
Для наглядности давайте напишем классическую структуру данных — односвязный список.
┌──────────┐ ┌──────────┐ ┌──────────┐ │значение 1│ ╭─>│значение 2│ ╭─>│значение 3│ ├──────────┤ │ ├──────────┤ │ ├──────────┤ │next: ptr ├─╯ │next: ptr ├─╯ │next: nil │ └──────────┘ └──────────┘ └──────────┘
На первый взгляд, эту конструкцию можно было бы описать так:
// Список — это:
enum List<T> {
Nil, // либо пустой список
Elem(T, List<T>), // либо пара: значение + список
}Однако компилятор выдаст такую ошибку:
enum List<T> {
Nil,
Elem(T, List<T>),
}// ------- recursive without indirection
// error[E0072]: recursive type `List` has infinite size
// insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
// Elem(T, Box<List<T>>),
// ++++ +Это как раз то, о чём мы говорили раньше: рекурсивная структура имеет неопределённый размер, что делает невозможным её размещение на стеке. Компилятор любезно предлагает нам использовать Box, что как раз решит нашу проблему:
#[derive(Debug)]
enum List<T> {
Nil,
Elem(T, Box<List<T>>),
}
use List::*;
fn main() {
let list: List<i32> =
Elem(1, Box::new(
Elem(2, Box::new(
Elem(3, Box::new(Nil))
))));
println!("{:?}", list); // Elem(1, Elem(2, Elem(3, Nil)))
}Трэйты Deref и DerefMut
Для объекта типа Box можно использовать оператор разыменовывания *, словно это обычная ссылка. Также при помощи оператора & из объекта типа Box можно получить прямую ссылку на данные в куче.
fn main() {
let mut b = Box::new(1);
*b = 2;
println!("{b}"); // 2
increment(&mut b);
println!("{b}"); // 3
}
fn increment(i: &mut i32) {
*i += 1;
}Такое поведение объекта Box (словно он ссылка) возможно благодаря тому, что тип Box реализует трэйт Deref.
pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}Этот трэйт позволяет типу предоставлять некую ссылку. Разумеется, в случае с Box это будет ссылка его на данные в куче.
Если тип реализует трэйт Deref, то для его объектов компилятор подменяет &объект на объект.deref().
Как мы могли заметить, метод deref возвращает немутабельную ссылку. Для случаев, когда мы хотим иметь возможность изменять значение по ссылке, существует трэйт DerefMut.
pub trait DerefMut: Deref {
fn deref_mut(&mut self) -> &mut Self::Target;
}Вызов *объект=значение подменяется на *(объект.deref_mut())=значение.
Rc — совместное владение
Концепция владения Rust не позволяет совместное владение одним и тем же объектом, однако есть целый ряд структур данных, где это необходимо (например, двусвязный список). Для таких ситуаций стандартная библиотека Rust предоставляет умный указатель Rc (Reference Counted).
В отличие от Box<T>, который по сути представляет из себя просто указатель на данные в куче, Rc<T> — структура из двух полей:
- указатель на данные в куче
- указатель на счётчик копий объекта
Rc
Рассмотрим простой пример использования Rc:
use std::rc::Rc;
fn main() {
let rc1 = Rc::new("Hello".to_string());
let rc2 = rc1.clone();
}Когда мы создаём новый объект при помощи Rc::new(значение):
- На стеке создаётся объект структуры
Rc - В куче выделяется место для данных и в него переносится значение, переданное в
Rc::new(). Далее адрес этого значения в куче присваивается полю объектаRc— “указателю на данные”. - На куче выделяется место под счётчик копий
Rcи инициализируется единицей. Адрес этого счётчика присваивается полю объектаRc— “указателю на счётчик”.
Когда мы клонируем объект Rc:
- На стеке создаётся новый объект
Rc. - Значение указателя на данные копируется из клонируемого объекта
Rc. - Значение указателя на счётчик числа копий
Rcкопируется из клонируемого объектаRc, при этом сам счётчик инкрементируется.
Когда переменная, хранящая объект Rc, выходит из скоупа:
- Счётчик копий
Rcуменьшается на1. - Если при этом значение счётчика стало равным
0, то память, в которой хранятся данные, и память, в которой хранится сам счётчик, очищаются.
Расположение Rc в памяти выглядит примерно так:

Tip
Проводя аналогию с C++,
Rcявляется прямым аналогом умного указателяshared_ptr.
Cell
Основное неудобство Rc заключается в том, что в отличие от Box, он не реализует трэйт DerefMut, а значит, не позволяет менять его содержимое.
use std::rc::Rc;
fn main() {
let mut rc1 = Rc::new(1);
*rc1 += 1;
// ^^^^^^^^^ cannot assign
// trait `DerefMut` is required to modify through a dereference,
// but it is not implemented for `Rc<i32>`
}Почему так сделано? Давайте вспомним правило безопасности ссылок в Rust: на объект одновременно можно иметь либо одну мутабельную ссылку, либо сколько угодно немутабельных. И само это правило обусловлено тем, что в общем случае, без дополнительных механизмов синхронизации, нельзя гарантировать корректность немутабельной ссылки после того, как данные были изменены по мутабельной ссылке.
Именно поэтому Rc и позволяет множественное владение одним и тем же объектом (аналог множества немутабельных ссылок), но без возможности менять значение.
Как мы заметили выше, одновременное наличие немутабельной и мутабельной ссылок небезопасно БЕЗ дополнительных механизмов синхронизации. Стандартная библиотека Rust предлагает механизм синхронизации специально для таких ситуаций — структура-обёртка Cell.
Cell<T> — обёртка, которая позволяет заменять своё содержимое целиком, безопасно и атомарно, и при этом НЕ позволяет:
- получать мутабельную ссылку на своё содержимое, что предотвращает возможность “порчи данных”
- получать немутабельную ссылку, которая могла бы стать недействительной при замене значения в
Cell.
Для работы с Cell, в основном, используются три метода:
- new(значение) — создаёт новый объект
Cellи инициализирует его заданным значением - replace(значение) — атомарно помещает в
Cellновое значение, а старое возвращается в качестве результата вызова - set(значение) — атомарно помещает в
Cellновое значение, а старое просто уничтожается
Рассмотрим пример работы с Cell:
use std::cell::Cell;
fn main() {
let cell = Cell::new("aaa".to_string());
// При замещении новым значение, прошлое возвращается как результат
let old_string = cell.replace("bbb".to_string());
println!("{old_string}");
// Если нам не нужно прошлое значение, то можно просто перезаписать его новым.
cell.set("ccc".to_string());
}Note
Обратите внимание: переменная
cellобъявлена без модификатораmut, однако мы смогли заместить хранящуюся в ней строку другой строкой. Так происходит, потому что замена значения происходит атомарно и безопасно, поэтому переменной не обязательно иметь семантику мутабельности со всеми сопутствующими ограничениями.
Если тип реализует интерфейс Copy, то из Cell можно извлекать его копию методом get.
use std::cell::Cell;
fn main() {
let cell = Cell::new(1);
println!("{}", cell.get()); // c1 = 1
}Итак, теперь, используя комбинацию Rc<Cell<T>>, мы можем создавать структуры данных, которые требуют как совместное владение, так и возможность заменять хранимое значение.
use std::{cell::Cell, rc::Rc};
fn main() {
let rc1 = Rc::new(Cell::new(1));
let rc2 = rc1.clone();
// Получаем ссылку на разделяемый Cell и записываем в него новое значение
rc2.as_ref().set(5);
println!("{:?}", rc1); // Cell { value: 5 }
}Important
Важно заметить, что
Cellзащищает только от сценариев порчи немутабельной ссылки путём изменения данных через мутабельную ссылку в рамках одного потока. Какой-либо защиты от гонок данныхCellне предоставляет.
RefCell
Очевидным недостатком Cell является то, что он позволяет только заменять хранимое значение, но не модифицировать. Обёртка RefCell<T> позволяет как раз изменять хранимое значение по ссылке.
use std::cell::{RefCell, RefMut};
fn main() {
let ref_cell = RefCell::new(1);
{
// Получаем "мутабельную ссылку": RefMut реализует DerefMut
let mut mut_ref: RefMut<'_, i32> = ref_cell.borrow_mut();
// изменяем значение внутри RefCell
*mut_ref = 5;
}
println!("{:?}", ref_cell);
}RefCell не нарушает правило безопасности ссылок, а просто переносит проверку из времени компиляции в рантайм. То есть попытка получить одновременно мутабельную и немутабельную ссылки на содержимое RefCell вызовет панику.
use std::cell::{RefCell, RefMut, Ref};
fn main() {
let ref_cell = RefCell::new(1);
let immut_ref: Ref<'_, i32> = ref_cell.borrow(); // borrowing immutable
let mut mut_ref: RefMut<'_, i32> = ref_cell.borrow_mut();
*mut_ref = 5; // ^^^ already borrowed: BorrowMutError
println!("{:?}", ref_cell);
}Теперь мы можем переписать наш односвязный список с использованием RefCell:
use std::rc::Rc;
use std::cell::RefCell;
#[derive(Debug)]
enum List<T> {
Elem(Rc<RefCell<T>>, Rc<List<T>>),
Nil,
}
use List::*;
fn main() {
let v = Rc::new(RefCell::new(1));
let a = Rc::new(Elem(Rc::clone(&v), Rc::new(Nil)));
let b = Elem(Rc::new(RefCell::new(2)), Rc::clone(&a));
let c = Elem(Rc::new(RefCell::new(3)), Rc::clone(&a));
*v.borrow_mut() += 10;
println!("a after = {:?}", a);
// Elem(RefCell { value: 11 }, Nil)
println!("b after = {:?}", b);
// Elem(RefCell { value: 2 }, Elem(RefCell { value: 11 }, Nil))
println!("c after = {:?}", c);
// Elem(RefCell { value: 3 }, Elem(RefCell { value: 11 }, Nil))
}Arc
Rc позволяет совместное владение объектом, однако Rc не является потокобезопасным типом, то есть не позволяет совместное владение объектом из разных потоков. Для многопоточной среды имеется потокобезопасная версия — Arc (Atomically Reference Counted).
Мы будем разбирать многопоточное программирование на Rust в главе Многопоточность, поэтому пока что просто запомните, что в многопоточном программировании вместо Rc используется Arc.
Cargo
Использовать напрямую компилятор rustc можно для сборки небольших тестовых программ, однако при написании реального приложения, которое использует сторонние библиотеки, не обойтись без системы сборки.
В большинстве языков программирования система сборки поставляется отдельно от тулчейна самого языка. Например, в Java популярны Maven и Gradle, которые распространяются отдельно от JDK. Но в случае с Rust, утилита rustup устанавливает систему сборки одновременно вместе с компилятором. И называется эта система сборки — Cargo.
Cargo умеет:
- создавать новый Rust проект
- собирать исполняемый файл / библиотеку
- автоматически скачивать и компилировать зависимости (библиотеки)
- запускать юнит и интеграционные тесты
- запускать бенчмарки, и агрегировать результаты
- скачивать и собирать различные утилиты из экосистемы Rust
Создание проекта
Для того чтобы создать новый Rust проект, управляемый системой сборки Cargo, нужно выполнить команду cargo new имя_проекта.
Для примера, создадим hello world проект:
cargo new hello_world --bin
Опция --bin указывает, что мы хотим создать исполняемую программу (тип проекта по умолчанию). Если бы мы хотели создать библиотеку, то следовало бы указать опцию --lib.
После выполнения команды, Cargo создаст такое дерево каталогов:
hello_world/
├── Cargo.toml
└── src/
└── main.rs
Это стандартная структура Cargo проекта:
- исходный код располагается внутри директории
src.- Если мы создаём исполняемую программу, то главным файлом программы является
main.rs. - Если мы создаём библиотеку, то главным файлом является
lib.rs
- Если мы создаём исполняемую программу, то главным файлом программы является
Cargo.toml— файл конфигурации проекта, из которого Cargo берёт основные настройки
Cargo наполнит src/main.rs “болванкой” программы Hello world:
fn main() {
println!("Hello, world!");
}Cargo.toml
Файл Cargo.toml содержит конфигурацию проекта на языке TOML (Tom’s Obvious, Minimal Language).
Сразу после создания, наш Cargo.toml должен выглядеть примерно так:
[package]
name = "hello_world"
version = "0.1.0"
edition = "2024"
[dependencies]
Секция package содержит основную информацию о проекте:
name— имя крэйта (о них мы поговорим позже). По умочанию имя исполняемого файла будет таким же, как это имя.version— версия программы или библиотеки.edition— версия языка Rust, которой соответствует код программы. Подробнее.
Секция dependencies служит для указания внешних зависимостей (библиотек) для программы. О них мы поговорим позже.
Сборка и запуск
Для того чтобы собрать исполняемый файл надо воспользоваться командой
cargo build
После этого исполняемый файл должен появиться в поддиректории target/debug. Запустим его, чтобы убедиться, что он работает:
На Linux/Mac:
$ ./target/debug/hello_world
Hello, world!
На Windows:
target\debug\hello_world
Hello, world!
Как вы могли догадаться по имени директории target/debug, Cargo по умолчанию собрал исполняемый файл с отладочными настройками. Если нам нужна оптимизированная релизная сборка без отладочной информации, то в команду сборки нужно передать флаг --release.
cargo build --release
Исполняемый файл появится в директории target/release.
Также, у Cargo есть команда, которая объединяет сборку и запуск — run:
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/hello_world`
Hello, world!
Зависимости
Практически любая реальная программа, помимо стандартной библиотеки, использует ряд сторонних библиотек. Когда для сборки программы необходима некая библиотека, то принято говорить, что программа зависит от этой библиотеки.
Именно для указания этих зависимостей служит секция [dependencies] в файле Cargo.toml.
Пример использования зависимости
Предположим, что мы решили написать программу — аналог “подбрасывания монетки”, которая при запуске случайным образом печатает “да” или “нет”.
Проблема в том, что в стандартной библиотеке Rust отсутствует функциональность для работы со случайными числами. Стандартным решением является — воспользоваться сторонней библиотекой rand. Давайте сначала рассмотрим реализацию программы, а потом разберёмся, что, как и откуда мы брали.
1) Создадим новый проект
cargo new decision_maker --bin
2) В Cargo.toml добавим зависимость на библиотеку rand версии 0.9 (актуальная на момент написания этого текста).
[package]
name = "decision_maker"
version = "0.1.0"
edition = "2024"
[dependencies]
rand = "0.9"
3) В главном файле программы src/main.rs напишем такое:
use rand::random;
fn main() {
let is_yes: bool = random();
if is_yes {
println!("YES");
} else {
println!("NO");
}
}4) Соберём наше приложение:
$ cargo build
Compiling libc v0.2.176
Compiling cfg-if v1.0.3
Compiling zerocopy v0.8.27
Compiling getrandom v0.3.3
Compiling rand_core v0.9.3
Compiling ppv-lite86 v0.2.21
Compiling rand_chacha v0.9.0
Compiling rand v0.9.2
Compiling decision_maker v0.1.0 (/home/stas/dev/proj/rust/decision_maker)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.60s
Running `target/debug/decision_maker`
и запустим его:
$ ./target/debug/decision_maker
YES
Работает! Теперь давайте разбираться в том, что мы сделали.
Репозиторий библиотек
В Cargo.toml мы добавили зависимость rand = "0.9". Этим мы подключили библиотеку rand версии 0.9. Каким же образом эта библиотека попадает к нам в проект?
Дело в том, что для Rust библиотек существует централизованный репозиторий — crates.io.
Когда Cargo встречает запись о библиотеке в секции [dependencies] файла Cargo.toml, он выкачивает код этой библиотеки с crates.io. Если у библиотеки имеются транзитивные зависимости, то Cargo автоматически выкачивает и их.
В предыдущем примере, когда мы выполнили cargo build, в логе сборки можно было видеть как Cargo компилирует rand и все его транзитивные зависимости: libc, cfg-if, zerocopy, и т.д.
Поиск бибилотек
Остаётся вопрос: как мы узнали о библиотеке rand?
При работе с Rust, поиск библиотек ничем не отличается от поиска библиотек на другом языке программирования: искать в интернете. Если “вбить” в поисковый движок (или ИИ ассистент) запрос о том, как на Rust сгенерировать случайное число, то, скорее всего, первой рекомендацией будет пример с использованием библиотеки rand.
Также можно ознакомиться со сборником популярных библиотек и программ — awesome-rust.
Просмотр дерева зависимостей
Чтобы посмотреть все зависимости, включая транзитивные, которые Cargo выкачал для нашего проекта, можно воспользоваться командой cargo tree:
$ cargo tree
decision_maker v0.1.0 (/home/user/projects/rust/decision_maker)
└── rand v0.9.2
├── rand_chacha v0.9.0
│ ├── ppv-lite86 v0.2.21
│ │ └── zerocopy v0.8.27
│ └── rand_core v0.9.3
│ └── getrandom v0.3.3
│ ├── cfg-if v1.0.3
│ └── libc v0.2.176
└── rand_core v0.9.3 (*)
Как видим, в нашем проекте есть только одна зависимость верхнего уровня — rand, при этом сам rand зависит от восьми других крэйтов.
Фичи библиотек
Очень часто в библиотеках часть функциональности “выключена” по умолчанию и для того чтобы её “включить”, нужно при объявлении зависимости указать определённый флаг — фичу (feature).
Например, мы хотим написать приложение, которое генерирует UUID идентификаторы 4-й версии UUID спецификации.
Сначала создадим проект:
cargo new uuid_v4_generator
На crates.io имеется библиотека uuid, которая поддерживает UUID версий с 1-й по 7-ю. Добавим её в зависимости:
[package]
name = "uuid_v4_generator"
version = "0.1.0"
edition = "2024"
[dependencies]
uuid = "1"
После ознакомления с документацией библиотеки uuid можно написать следующий корректный код программы (src/main.rs), которая генерирует UUID v4.
use uuid::Uuid;
fn main() {
let uuid_v4 = Uuid::new_v4();
println!("UUID: {uuid_v4}");
}Однако при попытке собрать программу мы узнаем, что метод Uuid::new_v4 недоступен. Дело в том, что по умолчанию функциональность, связанная с UUID v4 “выключена”, и чтобы её включить, необходимо объявить зависимость uuid следующим образом:
[package]
name = "uuid_v4_generator"
version = "0.1.0"
edition = "2024"
[dependencies]
uuid = { version = "1", features = ["v4"] }
Теперь всё дожно работать. Соберём и запустим программу:
$ cargo run
Compiling libc v0.2.180
Compiling getrandom v0.3.4
Compiling cfg-if v1.0.4
Compiling uuid v1.19.0
Compiling test_rust v0.1.0 (/home/stas/dev/proj/test_rust)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.26s
Running `target/debug/test_rust`
UUID: 38cfd8a3-06c1-4c90-905c-59c2b010ad0a
Как узнать о фичах, которые предоставляет библиотека?
Как правило информация о доступных фичах, и их описание приводится в официальной документации, которая отображается на странице библиотеки на crates.io.
Однако наиболее достоверным источником информации о фичах является секция [features] в Cargo.toml крэйта.
Например, на crates.io на странице крэйта uuid есть ссылка на github репозиторий с исходным кодом библиотеки.
Перейдя на страницу github репозитория библиотеки и открыв там Cargo.toml, мы легко найдём секцию [features]:
[features]
default = ["std"]
std = ["wasm-bindgen?/std", "js-sys?/std"]
v1 = ["atomic"]
v3 = ["md5"]
v4 = ["rng"]
v5 = ["sha1"]
v6 = ["atomic"]
v7 = ["rng"]
v8 = []
js = ["dep:wasm-bindgen", "dep:js-sys"]
Здесь default — это список фич, включённых по умолчанию. Всё, что следует после: std, v1, v2, и т.д. — доступные фичи. Если фича не присутствует в списке default, значит, она по умолчанию “выключена”, и представленная в ней функциональность не может быть использована, пока фича не будет “включена” явно.
Версии зависимостей
В Rust для задания версий крэйтов принято использовать семантическое версионирование.
Принцип такой:
- Версия состоит из трёх чисел, резделённых точкой:
мажорная_версия.минорная_версия.патч_версия - Если мы вносим в код изменения, которые ломают совместимость с предыдущей версией, то мы должны инкрементировать номер мажорной версии
- Если мы вносим изменения, которые добавляют новую функциональность, но не ломают API, тогда мы должны инкрементировать минорную версию
- Если мы просто хотим исправить баг, при этом не меняя API и не добавляя новую функциональность, тогда мы инкрементируем патч версию
Почему это важно? Дело в том, что по умолчанию Cargo скачивает самую свежую совместимую по API версию.
Например, на момент написания этого текста, самая свежая версия библиотеки uuid была 1.18.1. И при том, что в Cargo.toml мы указали:
uuid = { version = "1", features = ["v4"] }
фактическая версия, которую взял Cargo — 1.18.1:
$ cargo tree
test_rust v0.1.0 (/home/user/projects/uuid_v4_generator)
└── uuid v1.18.1
└── getrandom v0.3.3
├── cfg-if v1.0.3
└── libc v0.2.176
А что если мы явно укажем версию 1.17.0?
uuid = { version = "1.17.0", features = ["v4"] }
Ничего не изменится. Cargo упорно продолжает брать последнюю совместимую минорную версию — 1.18.1.
Такое поведение логично, если исходить из правил семантического версионирования. Однако мы живём не в идеальном мире, и можем попасть в ситуацию, когда последняя минорная версия совместима с точки зрения API, однако содержит баг. В этой ситуации мы можем явно указать необходимую версию зависимости при помощи знака =:
uuid = { version = "=1.17.0", features = ["v4"] }
Теперь Cargo взял именно ту версию, которая указана:
$ cargo tree
test_rust v0.1.0 (/home/user/projects/uuid_v4_generator)
└── uuid v1.17.0
└── getrandom v0.3.3
├── cfg-if v1.0.3
└── libc v0.2.176
Важно заметить, что принцип “самая свежая совместимая по API версия” не всегда означает “последняя минорная версия”. Для библиотек, чья мажорная компонента версии равна нулю, минорные версии считают несовместимыми по API. Т.е. версии 0.3.0 и 0.4.0 считают несовместимыми. В таких ситуациях Cargo будет брать наиболее свежую патч версию, но именно ту минорную версию, которая указана.
Например, если мы укажем зависимость:
rand = "0.8"
тогда, не смотря на то, что на crates.io имеется версия 0.9.2, Cargo возьмёт версию 0.8.5 — самую свежую доступную патч версию для 0.8.
Cargo.lock
Когда Cargo впервые выкачивает зависимости, рядом с файлом Cargo.toml он создаёт файл Cargo.lock.
В Cargo.lock Cargo фиксирует те номера версий, которые были выкачаны с crates.io при первой сборке проекта. Далее Cargo продолжает работать с этими версиями, даже если на crates.io появились более свежие совместимые версии.
Например, мы подключили библиотеку rand вот так:
rand = "0.8"
На момент первого запуска команды cargo build, самая свежая совместимая версия rand была 0.8.2. Это значит, что Cargo зафиксировал в файле Cargo.lock версию rand=0.8.2.
Позже, на crates.io для rand вышла более свежая совместимая версия — 0.8.3, но Cargo всё равно продолжит использовать версию 0.8.2, потому что она зафиксирована в Cargo.lock файле.
Однако если мы удалим текущий Cargo.lock файл, то Cargo создаст новый, и зафиксирует в нём уже более новые, доступные на текущий момент, версии.
Для чего всё это нужно? Как мы сказали, Cargo пытается брать самые свежие совместимые версии библиотек. Однако, учитывая факт, что новые версии библиотек часто привносят неожиданные баги, было бы хорошо иметь возможность зафиксироваться на некой рабочей конфигурации. Именно для этого и существует Cargo.lock.
Хотите обновиться? Просто удалите Cargo.lock. Хотите продолжать оставаться на уже знакомой и работающей комбинации версий? Просто не трогайте Cargo.lock.
Также, следует отметить, что при разработке библиотек, рекомендуется коммитить Cargo.lock в репозиторий кода. Соответственно, при разработке конечных исполняемых приложений, Cargo.lock, как правило, в репозиторий не коммитят.
Создание библиотеки
Мы уже знаем, что для создания Rust проекта, который компилируется в исполняемый бинарный файл, используется команда cargo new. Для создания библиотеки используется та же команда, но с флагом --lib:
cargo new my_lib --lib
Флаг --lib указывает, что изначально вместо src/main.rs надо создать src/lib.rs.
├── Cargo.toml
└── src/
└── lib.rs
(На самом деле ничто не мешает иметь и src/main.rs и src/lib.rs одновременно, и так часто и делают)
Теперь в Cargo.toml в секции [package] нам надо указать какой тип библиотеки мы делаем. Для этого используется поле crate-type:
[package]
name = "my_lib"
version = "0.1.0"
edition = "2024"
[lib]
crate-type = ["lib"]
[dependencies]
Для crate-type доступны такие варианты:
lib— Библиотека для программы на Rust. Это означает, что проект может собираться в различные типы библиотек, в зависимости от того, как будет собираться программа, которая библиотеку использует. Единственное, что гарантируется: библиотека будет работоспособна для любого другого Rust проекта.rlib— Статическая библиотека, специфичная для программ на Rust. Представлена файлом с расширением*.rlib.dylib— Динамическая библиотека (*.dllна Windows,*.soна Linux,*.dylibна MacOS), которая подходит только для программ на Rustcdylib— Системная динамическая библиотека, которая может быть использована из программ на других языкахstaticlib— Статическая библиотека (*.aили*.lib). Подходит для статической линковки в программу на языке, отличном от Rust.proc-macro— Библиотека, содержащая процедурный макрос.
Как видно, в общем случае, при разработке библиотеки для других Rust приложений, оптимальным вариантом является crate-type=["lib"].
Осталось написать сам код нашей библиотеки — src/lib.rs. Для наших нужд подойдёт, что угодно: например, функция, складывающая два числа.
#![allow(unused)]
fn main() {
pub fn sum2(a: i32, b: i32) -> i32 {
a + b
}
}Обратите внимание, что функции, экспортируемые из библиотеки, обязательно должны быть отмечены ключевым словом pub.
Использование бибилотеки
Как мы знаем, когда мы указываем библиотеку в секции [dependencies] в Cargo.toml, то Cargo пытается найти соответствующий крэйт на crates.io.
Однако, Cargo умеет скачивать зависимости не только с crates.io, но и из:
- git репозиториев
[dependencies] крэйт = { git = "https://github.com/аккаунт/репозиторий.git", branch = "main" } - локальной файловой системы
[dependencies] крэйт = { path = "/путь/к/коду/" } - альтернативных репозиториев
[dependencies] крэйт = { version = "1.0", registry = "репозиторий" }
В том же каталоге, где мы создали проект библиотеки my_lib, создадим новый проект, который подключит нашу библиотеку в качестве зависимости.
cargo new lib_usage --bin
Откроем Cargo.toml для свежесозданного проекта, и подключим зависимость на my_lib, путём указания пути к её каталогу.
[package]
name = "lib_usage"
version = "0.1.0"
edition = "2024"
[dependencies]
my_lib = { path = "../my_lib" }
Теперь в src/main сделаем простейший пример использования нашей библиотеки.
use my_lib::sum2;
fn main() {
println!("sum2(1,2)={}", sum2(1, 1));
}И запустим:
lib_usage$ cargo run
Locking 1 package to latest Rust 1.89.0 compatible version
Compiling my_lib v0.1.0 (/home/user/projects/rust/my_lib)
Compiling lib_usage v0.1.0 (/home/user/projects/rust/lib_usage)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/lib_usage`
sum2(1,2)=2
В логах сборки можно увидеть, как сначала компилируется зависимость my_lib, и затем уже непосредственно наше приложение.
Несколько исполняемых файлов
Как мы знаем, когда мы создаём исполняемую программу, то главным файлом является src/main.rs. Но что делать, если мы хотим сделать несколько исполняемых файлов, которые переиспользуют одни и те же модули?
В таком случае мы можем создать сколько угодно дополнительных главных файлов в каталоге src/bin.
Например, нам нужны три утилиты, работающие с последовательностью Фибоначчи:
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
- Первая утилита будет печатать печатать первые 10 элементов последовательности.
- Вторая будет печатать сумму первых 10 элементов последовательности.
- Третья будет печатать произведение элементов со 2-го по 10-й (потому что произведение на 0 всегда даёт 0).
Создадим новый Cargo проект:
cargo new fibonacci_util
Никаких зависимостей у нас не будет, поэтому Cargo.toml мы не трогаем.
Создаём модуль src/fibonacci.rs с реализацией генерации последовательности Фибоначчи в виде итератора:
#![allow(unused)]
fn main() {
// Сколько элементов из последовательности Фибоначчи мы хотим взять
pub struct FibonacciSequence(pub usize);
// Итератор для последовательности Фибоначчи заданной длины
pub struct FibonacciIter {
current_index: usize,
len: usize,
prev: u64,
before_prev: u64,
}
impl Iterator for FibonacciIter {
type Item = u64;
fn next(&mut self) -> Option<Self::Item> {
match self.current_index {
0 => {
self.current_index += 1;
Some(0)
},
1 => {
self.current_index += 1;
Some(1)
},
n if n < self.len => {
let nth = self.before_prev + self.prev;
self.before_prev = self.prev;
self.prev = nth;
self.current_index += 1;
Some(nth)
},
_ => None,
}
}
}
impl IntoIterator for FibonacciSequence {
type Item = u64;
type IntoIter = FibonacciIter;
fn into_iter(self) -> Self::IntoIter {
FibonacciIter {
current_index: 0,
len: self.0,
prev: 1,
before_prev: 0,
}
}
}
}Поскольку эта функциональность будет использоваться тремя программами, оформим её как библиотеку. Создадим src/lib.rs:
#![allow(unused)]
fn main() {
pub mod fibonacci;
}К этому моменту дерево файлов должно выглядеть так:
fibonacci_util/
├── Cargo.toml
└── src/
├── fibonacci.rs
├── lib.rs
└── main.rs
Теперь настало время первой программы, которая просто печатает 10 элементов последовательности. Поместим её в src/main.rs:
use fibonacci_util::fibonacci::FibonacciSequence;
fn main() {
let s = FibonacciSequence(10).into_iter().collect::<Vec<_>>();
println!("First 10 elements of fibonacci sequence: {s:?}");
}Здесь мы видим кое-что новое: вместо того, чтобы подключать модули через mod, мы просто импортировали модуль через use, причём первой компонентой имени является имя самого проекта (крэйта) — fibonacci_util. Это стало возможным, так как у нас уже есть библиотека lib.rs, которая по умолчанию подключена с тем же именем, что и у нашего крэйта, и которая импортирует модуль fibonacci. Таким образом, обращаясь к имени текущего проекта fibonacci_util, мы обращаемся к нашей библиотеке lib.rs.
Могли ли мы вместо этого, как раньше, просто подключить модуль fibonacci в наш main.rs?
mod fibonacci;
use fibonacci::FibonacciSequence;
fn main() {
let s = FibonacciSequence(10).into_iter().collect::<Vec<_>>();
println!("First 10 elements of fibonacci sequence: {s:?}");
}Да, могли. Такой код тоже работает. Но этот вариант не подойдёт для следующих двух утилит, которые мы напишем.
В Cargo проекте может быть только один основной главный файл программы — src/main.rs. И только он может подключать в себя модули через mod. Дополнительные главные файлы исполняемых программ помещаются в каталог /src/bin, и для них не доступны модули, которые располагаются непосредственно в src/, поэтому они могут обращаться к ним только через src/lib.rs.
Создадим нашу вторую утилиту, которая печатает сумму первых 10 элементов последовательности — src/bin/fibonacci_sum.rs:
use fibonacci_util::fibonacci::FibonacciSequence;
fn main() {
let sum: u64 = FibonacciSequence(10)
.into_iter()
.sum();
println!("Sum of first 10 elements of fibonacci sequence: {sum}");
}Как мы видим, функциональность из библиотеки src/lib.rs доступна через пространство имён fibonacci_util точно таким же образом, как и в нашем src/main.rs. Как мы уже сказали, для главных файлов в src/bin никакие модули из src/ напрямую не доступны, и единственный способ использовать эти модули — посредством библиотеки lib.rs.
Аналогично создадим последнюю утилиту, которая печатает произведение элементов последовательности со 2-го по 10-й — src/bin/fibonacci_prod.rs:
use fibonacci_util::fibonacci::FibonacciSequence;
fn main() {
let prod: u64 = FibonacciSequence(10).into_iter()
.skip(1) // Отбрасываем первый нулевой элемент
.product();
println!("Product of fibonacci sequence elements from 2nd to 10th: {prod}");
}К этому моменту, дерево файлов проекта должно выглядеть так:
fibonacci_util/
├── Cargo.toml
└── src/
├── bin/
│ ├── fibonacci_sum.rs
│ └── fibonacci_prod.rs
├── fibonacci.rs
├── lib.rs
└── main.rs
Выполнив команду сборки cargo build, мы должны увидеть в target/debug:
libfibonacci_util.rlib— Rust библиотека, собранная изsrc/lib.rsfibonacci_util— исполняемый файл, собранный изsrc/main.rsfibonacci_sum— исполняемый файл, собранный изsrc/bin/fibonacci_sum.rsfibonacci_prod— исполняемый файл, собранный изsrc/bin/fibonacci_prod.rs
Если мы хотим собрать только какой-то конкретный исполняемый файл, то мы должны указать его при помощи опции --bin. Например, чтобы собрать только fibonacci_sum:
cargo build --bin fibonacci_sum
[[bin]]
По умолчанию исполняемые файлы будут иметь те же имена, как и у соответствующих им src/bin/*.rs файлов. Однако имена можно изменить при помощи секции [[bin]] в файле Cargo.toml.
Допустим, мы хотим, чтобы src/bin/fibonacci_sum.rs собирался в исполняемый файл с именем sum_10, а src/bin/fibonacci_prod.rs — в файл prod_10.
[package]
name = "fibonacci_util"
version = "0.1.0"
edition = "2024"
[[bin]]
name = "sum_10"
path = "src/bin/fibonacci_sum.rs"
[[bin]]
name = "prod_10"
path = "src/bin/fibonacci_prod.rs"
[dependencies]
Теперь, после выполнения cargo build, в директории target/debug мы увидим sum_10 и prod_10.
Мы также можем задать другое имя и для исполняемого файла, который собирается из src/main.rs:
[package]
name = "fibonacci_util"
version = "0.1.0"
edition = "2024"
[[bin]]
name = "sequence_10"
path = "src/main.rs"
[[bin]]
name = "sum_10"
path = "src/bin/fibonacci_sum.rs"
[[bin]]
name = "prod_10"
path = "src/bin/fibonacci_prod.rs"
[dependencies]
Пакет, крэйт, модуль
Теперь, когда мы знаем, что в одном проекте может быть и библиотека, и несколько исполняемых файлов, мы наконец можем осознанно ответить на вопрос “что такое крэйт?”.
Всё просто: крэйт — это единица компиляции. И, учитывая, как компилятор Rust обрабатывает модули (сначала включает модули, а потом компилирует один большой файл), можно говорить, что крэйт — это либо библиотека, либо исполняемый файл.
Подытожим:
Пакет — это проект, который мы создаём при помощи cargo new. У нас даже главная секция в Cargo.toml называется [package].
Пакет содержит один или более крэйтов, которые соответствуют файлу lib.rs и главным файлам для исполняемых программ: src/main.rs и src/bin/*.rs.
С модулями мы уже хорошо знакомы из главы Модули. Это просто блоки кода на Rust обрамлённые в секцию mod модуль {}, или файлы с исходным кодом (которым суждено быть включёнными в другие файлы при сборке крэйта).
Workspace проект
Как правило, большие проекты разбивают на подпроекты.
Например, при написании back-end приложений, функциональность очень часто разбивают на слои:
- Слой взаимодействия с хранилищем данных: подключение к БД, функции с SQL запросами, структуры для работы с данными
- Слой с бизнес логикой: функции и структуры, реализующие логику программы
- Слой представления: REST/GRPC эндпоинты, web сокеты, и т.д.
Слои решают проблемы не только разбиения функциональности на подмножества, но и проблему логической изоляции этих подмножеств друг от друга. Например:
- Слой работы с данными не должен “видеть” функциональность из других модулей.
- Слой бизнес логики должен “видеть” сущности, хранимые в БД, и функции для работы с данными, но не должен видеть конкретную реализацию работы с хранилищем. И, очевидно, не должен видеть слой представления.
- А слой представления должен знать и про данные, и про бизнес функциональность, но без деталей реализации.

Во многих языках, например в Java, такой тип проектов, состоящий из отдельных слоёв-подпроектов, принято называть многомодульными проектами (multimodule project). Но так как в Rust слово “модуль” связано с другой сущностью, такие проекты называют воркспейс проектами (workspace).
workspace
Workspace — это такой тип пакета, который вместо кода, содержит в себе другие пакеты.
workspace-package/
├── Cargo.toml
├── пакет-1/
│ ├── Cargo.toml
│ └── src/
│ └── lib.rs
└── пакет-2/
├── Cargo.toml
└── src/
└── main.rs
Файл Cargo.toml в корневой директории имеет вид:
[workspace]
members = ["пакет-1", "пакет-2"]
При запуске Cargo (например, cargo build) в корневой workspace директории, Cargo считает Cargo.toml, поймёт, что мы имеем дело с workspace проектом, и проведёт сборку для всех дочерних пакетов, корректно разрешая зависимости между ними.
Пример workspace проекта
Для примера создадим простую программу, которая печатает некий текст, а также информацию о том, сколько в этом тексте слов.
Оформим программу в виде workspace проекта, который состоит из трёх пакетов:
- Пакет 1: data (библиотека) — функциональность для получения текста
- Пакет 2: processor (библиотека) — функциональность для подсчёта количества слов
- Пакет 3: cli (исполняемый файл) — печатает текст на консоль
В удобном для вас месте, создайте новую директорию с именем workspace_test для нашего workspace проекта.
В этой директории создайте файл Cargo.toml с таким содержимым:
[workspace]
members = [ ]
Теперь создадим дочерние пакеты: находясь консолью внутри workspace_test выполните:
cargo new data --lib
cargo new processor --lib
cargo new cli --bin
Cargo автоматически обновит корневой Cargo.toml после чего он должен выглядеть так:
[workspace]
members = ["cli", "processor","data"]
При этом дерево файлов проекта должно иметь вид:
workspace_test/
├── Cargo.toml
├── data/
│ ├── Cargo.toml
│ └── src/
│ └── lib.rs
├── processor/
│ ├── Cargo.toml
│ └── src/
│ └── lib.rs
└── cli/
├── Cargo.toml
└── src/
└── main.rs
Для начала напишем код библиотеки, которая предоставляет текст. В файле data/src/lib.rs напишем такое:
const TEXT: &str = "One two three four five six seven eight nine ten.";
pub fn get_text() -> String {
TEXT.to_string()
}Теперь в пакете processor в файле processor/Cargo.toml добавим зависимость на пакет data.
[package]
name = "processor"
version = "0.1.0"
edition = "2024"
[dependencies]
data = { path = "../data" }
После этого в пакете processor можно использовать функции, импортированные из пакета data. Напишем функцию, которая возвращает наш текст и количество слов в нём. Файл processor/src/lib.rs:
use data;
pub fn get_text_with_info() -> (String, usize) {
let text = data::get_text();
let words_count = text.split(" ").count();
(text, words_count)
}Теперь аналогичным образом добавим зависимость на processor в модуль cli.cli/Cargo.toml:
[package]
name = "cli"
version = "0.1.0"
edition = "2024"
[dependencies]
processor = { path = "../processor" }
И наконец, создадим исполняемую программу, которая печатает на консоль текст и количество слов в нём. Файл cli/src/main.rs:
use processor;
fn main() {
let (text, words_count) = processor::get_text_with_info();
println!("Text: {text}");
println!("Words count: {words_count}");
}Всё готово. Мы можем собрать и запустить нашу программу:
$ cargo build
Compiling data v0.1.0 (/home/user/project/rust/workspace_test/data)
Compiling processor v0.1.0 (/home/user/project/rust/workspace_test/processor)
Compiling cli v0.1.0 (/home/user/project/rust/workspace_test/cli)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
$ ./target/debug/cli
Text: One two three four five six seven eight nine ten.
Words count: 10
Обратите внимание, что в workspace проекте, мы запускаем программу из директории target, которая находится в корне проекта, а не из cli/target.
Note
Также, в workspace проекте мы можем выполнять команду Cargo для отдельного пакета при помощи опции
-p. Например, чтобы выпонитьcargo runдля пакетаcli:$ cargo run -p cli Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s Running `target/debug/cli` Text: One two three four five six seven eight nine ten. Words count: 10
workspace зависимости
Поскольку в workspace проекте у нас имеется несколько пакетов, легко может возникнуть ситуация, когда в разных пакетах в качестве зависимости нужна одна и те же библиотека. Например, нескольким пакетам может понадобиться библиотека rand.
Таким образом нам придётся быть внимательными, и при обновлении версий зависимостей, следить, чтобы версия была одинаково обновлена по всех пакетах.
В качестве решения этой проблемы, можно прописать версии зависимостей в workspace Cargo.toml, а в дочерних пакетах в Cargo.toml ссылаться на них.
Например, в workspace Cargo.toml объявляем версию библиотеки rand:
[workspace]
members = ["child_package"]
[workspace.dependencies]
rand = "0.8"
Теперь в дочернем пакете можно подключить зависимость rand так:
[package]
name = "child_package"
version = "0.1.0"
edition = "2024"
[dependencies]
rand = { workspace = true }
Теперь обновление версии зависимости в корневом Cargo.toml, будет автоматически отражено во всех дочерних пакетах.
Тестирование
Unit тестирование
В Rust принято писать юнит-тесты в том же файле, в котором находятся тестируемые функции.
Юнит-тест — представляет из себя функцию, помеченную аннотацией #[test].
Например, у нас есть программа, которая инкрементирует число. Делает она это при помощи функции inc.
fn inc(a: i32) -> i32 {
a + 1
}
fn main() {
let a = 5;
let b = inc(a);
println!("{b}");
}Давайте напишем для функции inc пару юнит-тестов: test_inc_1 и test_inc_2.
fn inc(a: i32) -> i32 {
a + 1
}
#[test]
fn test_inc_1() {
assert_eq!(inc(1), 2);
}
#[test]
fn test_inc_2() {
assert_eq!(inc(7), 8);
}
fn main() {
let a = 5;
a = inc(a);
println!("{a}");
}Макрос assert_eq сравнивает аргументы, и если они не равны, то инициируется паника.
Для того чтобы запустить все тесты в пакете, используется команда cargo test:
$ cargo test
running 2 tests
test my_module::test_inc_1 ... ok
test my_module::test_inc_2 ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Запустить отдельный тест можно так:
$ cargo test -- --exact my_module::test_inc_1
Note
С точки зрения организации, все юнит тесты компилируются в отдельный исполняемый бинарный файл, который можно найти в каталоге
target/debug/deps/. Он носит имяимя_крэйта-хеш. Этот бинарный файл содержит в себе всё содержимое тестируемого модуля, плюс сами функции юнит-тесты, плюс код для запуска тестов и генерации отчёта.
Интеграционные тесты
Если юнит-тесты располагаются в тех же модулях, что и тестируемые функции, то интеграционные тесты располагаются в отдельной директории пакета — tests. Как следствие, интеграционные тесты имеют доступ только к публичному API тестируемого крэйта.
├── Cargo.toml
├── src/
│ ├── main.rs
│ ├── module1.rs
│ └── module2.rs
└── tests/
├── integration-tests_1.rs
└── integration-tests_2.rs
В отличие от юнит тестов, каждый tests/*.rs файл компилируется в отдельный исполняемый файл. Фактически *.rs файл с интеграционными тестами является отдельным тестовым крэйтом.
Поэтому имеет смысл, по возможности, группировать интеграционные тесты по типу ресурсов, которые им необходимы для исполнения. Например, собрать в один файл все тесты, которым нужна только реляционная БД, в другой файл — все тесты, которым нужен только распределённый кеш.
Давайте посмотрим на пример, который поможет понять структуру тестов.
Объектом нашего интеграционного тестирования будет крэйт-библиотека с двумя модулями:
data— функциональность для работы с хранилищемuser_service— функциональность работы с записями пользователей
Создадим новый проект:
cargo new test_project --lib
Файл src/data.rs:
// Отражает пользователя, который хранится в неком хранилище.
pub struct User {
pub first_name: String,
pub last_name: String,
}
// Объявляет интерфейс получения объекта пользователя из хранилища.
// Конкретная реализация работы с конкретным хранилищем отдаётся на откуп
// пользователю библиотеки, который должен будет реализовать этот трэйт.
pub trait DataSource {
// Извлекает пользователя с указанным ID из хранилища
fn find_user_by_id(&self, id: u64) -> Option<User>;
}Файл src/user_service.rs:
use crate::data::DataSource;
// Функция, которая принимает реализацию работы с хранилищем и ID пользователя,
// и возвращает полное имя этого пользователя
pub fn get_user_full_name(ds: &dyn DataSource, user_id: u64) -> Option<String> {
ds.find_user_by_id(user_id)
.map(|user| format!("{} {}", user.first_name, user.last_name))
}Файл src/lib.rs:
pub mod data;
pub mod user_service;Теперь напишем интеграционный тест, в котором мы протестируем функцию get_user_full_name из модуля user_service.
Эта функция требует какую-то реализацию трэйта DataSource, чтобы использовать её для извлечения пользователя. В реальной программе реализацией, скорее всего, была бы интеграция с базой данных или неким identity сервисом, но для тестовых целей мы просто сделаем заглушку (mock), которая возвращает заранее подготовленные тестовые данные.
Файл tests/user_service_test.rs:
use test_project::{data::{DataSource, User}, user_service::get_user_full_name};
// Заглушка для тестов
struct DataSourceMock;
impl DataSource for DataSourceMock {
fn find_user_by_id(&self, id: u64) -> Option<User> {
Some(User { first_name: "John".to_string(), last_name: "Doe".to_string() })
}
}
#[test]
fn test_get_user_full_name() {
let result = get_user_full_name(&DataSourceMock, 1);
assert_eq!(Some("John Doe".to_string()), result);
}Теперь запустим наш тест:
$ cargo test
Running tests/user_service_test.rs (target/debug/deps/user_service_test-9f98ad2948b56b39)
running 1 test
test test_get_user_full_name ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Тест проходит.
Tip
Если какие-то зависимости (библиотеки) необходимы только для интеграционных тестов (например, Test containers), то в
Cargo.tomlсуществует отдельная секция зависимостей, которые доступны только для интеграционных тестов — секция[dev-dependencies].
На данном этапе нам нет смысла углубляться в интеграционные тесты. Мы поговорим о них подробнее в главе Тест контейнеры, когда будем рассматривать написание бекендов.
cargo-nextest
Если вам не хватает гибкости стандартного cargo test раннера тестов, то обратите внимание на nextest. Этот — альтернативный раннер, который:
- выдаёт более информативный вывод о запуске тестов
- позволяет запускать легковесные тесты параллельно, а тяжеловесные — последовательно
- позволяет указывать ретраи для тестов
- позволяет генерировать отчёты в JUnit XML формате
- и много другое
Чтобы установить nextest, выполните команду:
cargo install cargo-nextest --locked
После этого вы можете запускать ваши тесты при помощи:
cargo nextest run
Сравните вывод cargo test и cargo nextest.
test:
$ cargo test
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.21s
Running unittests src/main.rs (target/debug/deps/test_rust-ba9e2d97573eceb4)
running 3 tests
test test_1 ... ok
test test_2 ... ok
test test_3 ... ok
test result: ok.
3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
nextest:
$ cargo nextest run
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.05s
────────────
Nextest run ID 06dccce6-29f5-45a0-9ec4-1d9328eaae82 with nextest profile: default
Starting 3 tests across 1 binary
PASS [ 0.006s] test_rust::bin/test_rust test_3
PASS [ 0.006s] test_rust::bin/test_rust test_2
PASS [ 0.006s] test_rust::bin/test_rust test_1
────────────
Summary [ 0.007s] 3 tests run: 3 passed, 0 skipped
Основные трейты
Мы уже успели познакомиться со следующими трэйтами:
- Debug — определяет функциональность, для получения отладочного текстового описания объекта. Используется при выводе макросом
println!посредством форматирующей комбинации{:?} - Clone — определяет метод
clone(), который делает глубокую копию объекта - Copy — маркерный трэйт, который указывает компилятору, что при присваивании или передаче в функцию по значению, вместо перемещения владения, нужно производить копирование путём вызова метода
clone() - Hash — определяет метод для вычисления хеш-кода из объекта
- PartialEq, Eq — определяет методы для сравнения объектов на равенство
- Default — задаёт метод-конструктор, который создаёт объект по умолчанию
- Deref — позволяет брать ссылку на некие данные, которыми владеет объект. Компилятор подменяет выражение
&объектнаобъект.deref(). - Iterator — позволяет итерироваться по элементам объекта
Кроме вышеперечисленных, существуют ещё такие широкоиспользуемые трэйты:
- PartialOrd, Ord — объявляют методы для определения того, какой из двух объектов больше другого (используется при сортировке)
- From / Into — определяют конвертирование из одного типа в другой
- AsRef<T> — имея ссылку на родительский объект, позволяет получить ссылку на внутренние данные
- Borrow — позволяет одалживать ссылку на значение, которым владеет объект
- ToOwned — позволяет получать объект (для владения) из ссылки (как правило, путём клонирования)
- Drop — объявляет метод-деструктор, который вызывается при выходе объекта из скоупа
- Sized — маркерный трэйт, который автоматически имплементируется компилятором, если размер типа известен на этапе компиляции
- Sync — маркерный трэйт, который автоматически добавляется компилятором к типу, если к значению этого типа безопасно обращаться из нескольких потоков. О нём мы подробнее поговорим в главе про Многопоточность.
- Send — маркерный трэйт, который автоматически добавляется компилятором для типов, чьи значения могут передаваться в другой поток. О нём мы также поговорим в главе про Многопоточность.
Подробнее о Eq и PartialEq
Как мы упоминали ранее, в Rust существуют два трэйта, которые используются для проверки на равенство:
PartialEq— частичное равенство#![allow(unused)] fn main() { pub trait PartialEq<Rhs = Self> where Rhs: ?Sized { fn eq(&self, other: &Rhs) -> bool; // оператор == fn ne(&self, other: &Rhs) -> bool { ... } // оператор != } }Eq— равенство#![allow(unused)] fn main() { pub trait Eq: PartialEq { } }
Трэйт Eq требует, чтобы методы eq и ne, которые соответствуют операторам == и !=, были:
- рефлексивны:
a == a - симметричны: если
a == b, тоb == a - транзитивны: если
a == bиb == c, тоa == c
Трэйт PartialEq не имеет таких ограничений, поэтому может быть использован для типов, для которых не определено полное равенство.
Например, f32 и f64 соответствуют спецификации IEEE 754, которая декларирует, что переменные этих типов могут содержать значение NAN (not a number), причём в соответствии с IEEE 754 NAN != NAN.
#![allow(unused)]
fn main() {
let a = f32::NAN;
let b = f32::NAN;
println!("{}", a == b) // false
}Стандартные типы, которые реализуют Eq:
- целые числа:
i8-i128иu8-u128 - булевый тип:
bool - строки:
&strиString - массив, если тип элементов массива реализует
Eq Vec<T>, еслиTреализуетEq- Unit
Реализуют только PartialEq:
- числа с плавающей запятой:
f32,f64.
PartialOrd и Ord
Эти два трэйта используются для реализации сравнения на “больше, меньше или равно”.
Как правило, реализация этих трэйтов необходима для использования объектов в функциональности, подразумевающей сортировку значений по возрастанию/убыванию.
Трэйт PartialOrd используется для сравнения значений, которые не всегда могут быть сравнимы.
#![allow(unused)]
fn main() {
pub trait PartialOrd<Rhs = Self>: PartialEq<Rhs> where Rhs: ?Sized {
fn partial_cmp(&self, other: &Rhs) -> Option<Ordering>;
// Реализации по умолчанию
fn lt(&self, other: &Rhs) -> bool { ... }
fn le(&self, other: &Rhs) -> bool { ... }
fn gt(&self, other: &Rhs) -> bool { ... }
fn ge(&self, other: &Rhs) -> bool { ... }
}
}Как мы видим, основной метод partial_cmp возвращает тип Option<Ordering>.
#![allow(unused)]
fn main() {
pub enum Ordering {
Less = -1, Equal = 0, Greater = 1,
}
}Если значения являются сравнимыми, то partial_cmp возвращает Some(Ordering).
Если значения являются несравнимыми, то partial_cmp возвращает None. За примером снова обратимся к типу f32.
#![allow(unused)]
fn main() {
println!("{:?}", 4.0.partial_cmp(&5.0)); // Some(Less)
println!("{:?}", f32::NAN.partial_cmp(&f32::NAN)); // None
}Соответственно, трэйт Ord используется для задания строгого сравнения.
#![allow(unused)]
fn main() {
pub trait Ord: Eq + PartialOrd {
fn cmp(&self, other: &Self) -> Ordering;
// Реализации по умолчанию
fn max(self, other: Self) -> Self where Self: Sized { ... }
fn min(self, other: Self) -> Self where Self: Sized { ... }
fn clamp(self, min: Self, max: Self) -> Self where Self: Sized { ... }
}
}Для примера создадим тип “Груз” с двумя полями: масса и флаг — является ли груз хрупким. Мы хотим иметь возможность сортировать вектор с грузами так, чтобы груз с меньшей массой оказывался перед грузом с большей массой, но все хрупкие грузы были перед всеми нехрупкими.
#[derive(Debug, PartialEq)]
struct Cargo {
weight: f32,
fragile: bool,
}
impl Eq for Cargo {}
impl PartialOrd for Cargo {
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
Some(self.cmp(other))
}
}
impl Ord for Cargo {
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
if self.fragile && !other.fragile {
return std::cmp::Ordering::Less;
}
if !self.fragile && other.fragile {
return std::cmp::Ordering::Greater;
}
if self.weight < other.weight { std::cmp::Ordering::Less }
else if self.weight > other.weight { std::cmp::Ordering::Greater }
else { std::cmp::Ordering::Equal }
}
}
fn main() {
let mut v = vec![
Cargo { weight: 2.0, fragile: false },
Cargo { weight: 1.0, fragile: false },
Cargo { weight: 3.0, fragile: true },
];
v.sort(); // Требует, чтобы тип элемента реализовал Ord
println!("{v:?}");
//Cargo{weight:3.0,fragile:true},Cargo{weight:1.0,fragile:false},Cargo{weight:2.0,fragile:false}
}Обычно логику сравнения пишут в реализации PartialOrd только в том случае, если реализация Ord для этого же типа не планируется. В противном случае реализация PartialOrd должна заключаться просто в перевызове Ord::cmp, как в примере выше.
Default
Этот трэйт декларирует метод-конструктор, который позволяет создать объект по умолчанию.
#![allow(unused)]
fn main() {
pub trait Default: Sized {
fn default() -> Self;
}
}Трэйт Default определён для многих стандартных типов:
fn main() {
println!("{}", i32::default()); // 0
println!("{}", f32::default()); // 0
println!("{}", bool::default()); // false
println!("{}", String::default()); // ""
println!("{:?}", Vec::<i32>::default()); // []
}Многие функции стандартной библиотеки работают с трэйтом Default. Например, тип Option имеет метод unwrap_or_default(), который возвращает значение по умолчанию, в случае вызова на объекте None.
#![allow(unused)]
fn main() {
let o: Option<i32> = None;
let v = o.unwrap_or_default();
println!("{v}"); // 0
}Реализовать Default для своего типа можно либо при помощи аннотации derive:
#[derive(Debug, Default)]
struct Ip4Addr(u8, u8, u8, u8);
fn main() {
let default_ip_addr = Ip4Addr::default();
println!("{default_ip_addr:?}"); // Ip4Addr(0, 0, 0, 0)
}либо вручную:
#[derive(Debug)]
struct Ip4Addr(u8, u8, u8, u8);
impl Default for Ip4Addr {
fn default() -> Self {
Ip4Addr(127, 0, 0, 1)
}
}
fn main() {
let default_ip_addr = Ip4Addr::default();
println!("{default_ip_addr:?}"); // Ip4Addr(127, 0, 0, 1)
}From и Into
Трэйты From и Into — два трэйта “собрата”, которые используются для конвертации между типами.
Трэйт From позволяет задать функциональность для преобразования из некоего типа T в тип, для которого мы реализуем трэйт From. Трэйт декларирует метод-конструктор from, который используется для построения одного значения из другого:
#![allow(unused)]
fn main() {
pub trait From<T>: Sized {
fn from(value: T) -> Self;
}
}Например, сделаем реализацию From, которая позволяет создать объект структуры “IP4 адрес” из массива.
#[derive(Debug)]
struct Ip4Addr(u8, u8, u8, u8);
fn ping(addr: Ip4Addr) {
println!("Ping {addr:?}");
}
impl From<[u8; 4]> for Ip4Addr {
fn from(value: [u8; 4]) -> Self {
let [a, b, c, d] = value;
Ip4Addr(a, b, c, d)
}
}
fn main() {
let arr = [127, 0, 0, 1];
let addr = Ip4Addr::from(arr);
ping(addr);
}Трэйт Into делает то же самое, только “с другой стороны”:
#![allow(unused)]
fn main() {
pub trait Into<T>: Sized {
fn into(self) -> T;
}
}Если From обычно используется как конструктор — для явного создания объекта нужного нам типа из объекта другого типа, то Into используется при передаче аргументов в виде: arg: impl Into<T>, что позволяет уже внутри функции преобразовать аргумент в нужный тип. Например:
#[derive(Debug)]
struct Ip4Addr(u8, u8, u8, u8);
fn ping(into_addr: impl Into<Ip4Addr>) { // Принимаем аргумент как Into
println!("Ping {:?}", into_addr.into());
}
impl Into<Ip4Addr> for [u8; 4] {
fn into(self) -> Ip4Addr {
let [a, b, c, d] = self;
Ip4Addr(a, b, c, d)
}
}
fn main() {
let arr = [127, 0, 0, 1];
ping(arr);
}Однако трэйт Into очень редко реализуют явно. Дело в том, что когда мы реализуем From<X> for Y, мы автоматически получаем и реализацию Into<Y> for X.
AsRef
Трэйт AsRef<T> декларирует метод as_ref(), который используется для того, чтобы из ссылки на объект получить другую ссылку — на внутреннее поле объекта или другие данные, которыми объект владеет.
#![allow(unused)]
fn main() {
pub trait AsRef<T> where T: ?Sized {
fn as_ref(&self) -> &T;
}
}Этот трэйт используют для того, чтобы получать ссылку на данные в том виде, в котором они уже хранятся в объекте. Какие-то преобразования данных не предполагаются. Как правило, этот трэйт используется для указания типа аргумента функций в виде impl AsRef<T>.
Рассмотрим пример: имеется тип “Отправление”, который инкапсулирует в себе “Товар” и “Адрес”. Мы используем AsRef для получения доступа к этим внутренним полям.
struct Product(String);
struct Address(String);
struct Shipment {
product: Product,
address: Address,
}
impl AsRef<Product> for Shipment {
fn as_ref(&self) -> &Product {
&self.product
}
}
impl AsRef<Address> for Shipment {
fn as_ref(&self) -> &Address {
&self.address
}
}
fn process_product(prod: impl AsRef<Product>) {
// ...
}
fn process_address(addr: impl AsRef<Address>) {
// ...
}
fn main() {
let s = Shipment {
product: Product("laptop".to_string()),
address: Address("In the middle of the nowhere".to_string()),
};
process_product(&s);
process_address(&s);
}Note
Теоретически мы можем использовать метод
as_ref()вне контекста передачи аргументов в функцию, а просто вызывать:#![allow(unused)] fn main() { let addr: &Address = s.as_ref(); }или даже
#![allow(unused)] fn main() { let addr = AsRef::<Address>::as_ref(&s); }но обычно на практике это не имеет смысла.
Кроме AsRef, который предоставляет немутабельную ссылку, имеется соответствующий трэйт AsMut, который служит той же цели, но возвращает мутабельную ссылку.
Borrow
Сигнатурно трэйт Borrow очень похож на AsRef: он так же служит для предоставления ссылки на некий внутренний объект.
#![allow(unused)]
fn main() {
pub trait Borrow<Borrowed> where Borrowed: ?Sized {
fn borrow(&self) -> &Borrowed;
}
}Единственная разница заключается в том, что вся функциональность, определённая в стандартной библиотеке для трэйта Borrow, предполагает связь в реализации ряда трэйтов и для владеющего объекта, и для полученной из него ссылки.
А именно, для неких объектов x и y типа T, реализующего трэйт Borrow<R>, предполагается, что:
- если
TиRреализуют трэйтEq, выражениеx.borrow() == y.borrow()должно возвращать то же, что иx == y - если
TиRреализуют трэйтOrd, выражениеx.borrow().cmp(&y.borrow())должно возвращать то же, что иx.cmp(&y) - если
TиRреализуют трэйтHash, то хеш-код отxдолжен быть равен хеш-коду отx.borrow()
Существует также трэйт BorrowMut, который возвращает мутабельную ссылку.
ToOwned
Трэйт ToOwned декларирует метод to_owned(), который позволяет из ссылки получить новый объект для владения.
#![allow(unused)]
fn main() {
pub trait ToOwned {
type Owned: Borrow<Self>;
fn to_owned(&self) -> Self::Owned;
// Реализация по умолчанию
fn clone_into(&self, target: &mut Self::Owned) { ... }
}
}Часто ToOwned делает то же самое, что и Clone, но в некоторых ситуациях, он возвращает другой тип.
Например, реализация ToOwned для &str возвращает объект String.
#![allow(unused)]
fn main() {
let slice: &str = "aaa";
let owned: String = slice.to_owned();
}Drop
Трэйт Drop используется для задания функциональности, которая должна быть выполнена при выходе значения из скоупа. Как правило, при помощи этого трэйта задают деструктор.
Для типов, которые захватывают I/O ресурс, Drop можно использовать для освобождения этого ресурса. Для типов, которые владеют объектом в куче, Drop используют для освобождения памяти.
Например, сделаем структуру — примитивный аналог Box, которая инкапсулирует в себе указатель на кучу, и воспользуемся Drop для того, чтобы освободить аллоцированную память.
struct MyBox<T> {
ptr: *mut T,
}
impl <T> MyBox<T> {
fn new(val: T) -> MyBox<T> {
let ptr = unsafe {
let layout = std::alloc::Layout::for_value(&val);
let ptr = std::alloc::alloc(layout) as *mut T;
*ptr = val;
ptr
};
MyBox {
ptr
}
}
fn get(&self) -> &T {
unsafe { self.ptr.as_ref().unwrap() }
}
fn set(&self, new_val: T) {
unsafe { *self.ptr = new_val; }
}
}
impl<T> Drop for MyBox<T> {
fn drop(&mut self) {
unsafe {
std::alloc::dealloc(self.ptr as *mut u8, std::alloc::Layout::new::<T>());
}
println!("Released memory");
}
}
fn main() {
{
let my_box = MyBox::new(5);
println!("Boxed num: {}", my_box.get());
} // my_box выходит из скоупа
println!("Box memory is already released here");
}Программа печатает:
Boxed num: 5
Released memory
Box memory is already released here
Note
Не акцентируйте внимание на работе с кучей из данного примера (особенно учитывая, что, обычно, работают с ней не совсем так). Высока вероятность, что при написании бекендов на Rust, вам никогда не придётся работать с кучей напрямую.
Sized
Трэйт Sized — маркерный трэйт, который автоматически реализуется компилятором для типов, чей размер известен на этапе компиляции.
Примером не-Sized типа является тип str. Не &str, а именно str. Да, на самом деле тип строкового литерала — это str, но мы всегда работаем с ними посредством слайс-ссылки &str. А слайс-ссылка, как мы знаем, имеет известный и постоянный размер (два поля: указатель и длина). Таким образом, str — не Sized, а &str — Sized.
По аналогии с str, не-Sized типом является и [T] — последовательность элементов в памяти неопределённого размера. Точно так же как и с str, с [T] мы работаем посредством слайса &[T], который — Sized.
Ещё один пример не-Sized типа — трэйт-объект (dyn Трэйт). Именно поэтому мы работаем с трэйт объектами либо по ссылке &dyn Трэйт, либо путём упаковки в умный указатель Box<dyn Трэйт>.
При этом тип Vec — Sized: хоть размер буфера, хранимого в куче, и не известен на этапе компиляции, но с точки зрения системы типов, тип Vec — это только та часть, которая хранится на стеке, а её размер известен. Аналогичным образом тип String тоже Sized.
Как мы видим, все типы, которые мы можем самостоятельно создать, используя безопасный Rust (без unsafe и работы с памятью через указатель), являются Sized, даже если они хранят данные в куче.
Также надо упомянуть, что по умолчанию для всех генерик тип-аргументов компилятор задаёт неявную границу Sized.
То есть когда мы пишем код:
#![allow(unused)]
fn main() {
fn my_func<T>() { ... }
}компилятор расценивает его как:
#![allow(unused)]
fn main() {
fn my_func<T: Sized>() { ... }
}Иногда это ограничение нужно снять, для чего указывается явная трэйт граница ?Sized:
#![allow(unused)]
fn main() {
fn my_func<T: ?Sized>() { ... }
}Просматривая генерик код в сторонних библиотеках или стандартной библиотеке, можно часто встретить такое послабление трэйт границы через ?Sized.
Any
Проблема даункаста
Как мы знаем, Rust не является ООП языком. Тем не менее, благодаря системе трэйтов, Rust предлагает мощные возможности полиморфизма.
Благодаря трэйт-объектам, мы в любой момент можем сделать “upcast”, то есть начать общаться с типом через его трэйт, абстрагируясь от того, какой конкретно тип скрыт за трэйт-объектом.
trait Person {}
struct Student {}
impl Person for Student {}
struct Teacher {}
impl Person for Teacher {}
fn work_with_person(person: &dyn Person) {}
fn main() {
let child1 = Student {};
work_with_base(&child1); // upcast &Student к &dyn Person
let child2 = Teacher {};
work_with_base(&child2); // upcast &Teacher к &dyn Person
}Но что делать в ситуации, когда необходимо узнать, какой конкретный тип скрывается за трэйт-объектом? То есть, обращаясь к нашему примеру выше, как, имея ссылку &dyn Person, получить из неё ссылку &Student или &Teacher? Другими словами, сделать “downcast”.
Note
Upcast и downcast — термины из мира ООП, где классы могут наследовать друг друга. Приведение указателя на объект дочернего класса к указателю на родительский класс называется upcast. Словно движение вверх (up) по иерархии. Соответственно, приведение типа указателя с родительского класса на дочерний называется downcast.
Допустим, у нас есть такая иерархия классов на C++:
class Shape { protected: float x, y; // location } class Circle : public Shape { float radius; }Тогда
Circle* circle1 = new Circle(); Shape* shape = dynamic_cast<Shape*>(circle1); // upcast Circle* circle2 = dynamic_cast<Circle*>(shape); // downcast
К сожалению, на данный момент в Rust нет никакой возможности узнать, какой реальный тип скрывается за трэйт-объектом. Напомним, ссылка на трэйт-объект — это просто пара указателей: первый — на сам объект, второй — на vtable. При этом vtable не содержит название или ID типа, только указатели на методы, указатель на деструктор (если таков имеется), а также информацию о размере и выравнивании.
Однако есть обходной путь. При компиляции каждому типу присваивается уникальный идентификатор — TypeId, который является просто обёрткой над 128-битным числом:
#![allow(unused)]
fn main() {
pub struct TypeId {
t: (u64, u64),
}
}Чтобы узнать TypeId для некого типа, используется метод-конструктор TypeId::of.
Например:
use std::any::TypeId;
struct Student {}
struct Teacher {}
fn main() {
println!("{:?}", TypeId::of::<Student>()); // TypeId(0xaf8ebb053b28606d84daaf35f1eae84c)
println!("{:?}", TypeId::of::<Teacher>()); // TypeId(0x318ec7010fde8de82dedcdc9562881fd)
}При этом важно заметить, что TypeId::of выполняется на этапе компиляции.
Имея в арсенале TypeId, мы можем самостоятельно реализовать проверку: является ли трэйт-объект экземпляром нужного типа или нет. Давайте перепишем самый первый пример из главы, добавив в него downcast.
use std::any::TypeId;
trait Person where Self: 'static {
fn exact_type(&self) -> TypeId {
TypeId::of::<Self>()
}
}
/// Обратите внимание, что impl не для Person, а для dyn Person - трэйт-объекта
impl dyn Person {
/// Этот метод даункастит трэйт-объект к ссылке на конкретный тип, если
/// этот конкретный тип соответствует типу объекта, сокрытого за трэйт-объектом
fn downcast<T: 'static>(&self) -> Option<&T> {
if TypeId::of::<T>() == self.exact_type() {
unsafe {
let (data, _vtable): (*const u8, *const u8) =
std::mem::transmute(self);
let data: *const T = std::mem::transmute(data);
data.as_ref()
}
} else {
None
}
}
}
struct Student {
name: String,
year_of_education: u32,
}
impl Person for Student {}
struct Teacher {
name: String,
subject: String,
}
impl Person for Teacher {}
fn work_with_person(base: &dyn Person) {
// При помощи нашего метода downcast, проверяем кто скрыт
// за трэйт-объектом: Student или Teacher
if let Some(s) = base.downcast::<Student>() {
println!("This is {}, a {}-year student", s.name, s.year_of_education);
} else if let Some(t) = base.downcast::<Teacher>() {
println!("This is {}, a teacher of {}", t.name, t.subject);
}
}
fn main() {
let student = Student {
name: "John".to_string(),
year_of_education: 3,
};
work_with_person(&student);
let teacher = Teacher {
name: "Ivan".to_string(),
subject: "Programming".to_string(),
};
work_with_person(&teacher);
}Программа работает как от неё и требовалось:
$ cargo run
This is John, a 3-year student
This is Ivan, a teacher of Programming
Теперь давайте разберёмся в коде.
Для трэйта Person мы добавили метод, который возвращает TypeId того типа, который этот трэйт реализует. Если Person реализуется структурой Student, то вернётся TypeId для Student, а если структурой Teacher, то соответственно TypeId для Teacher.
#![allow(unused)]
fn main() {
trait Person where Self: 'static {
fn exact_type(&self) -> TypeId {
TypeId::of::<Self>()
}
}
}Tip
Про границу трэйта
'static.Граница трэйта
'staticговорит, что объект, реализуюший этот трэйт, не должен содержать ссылок, чей лайфтайм короче, чем'staticлайфтайм.Рассмотрим пример:
struct MyIntRef<'a> { r: &'a i32, } /// Функция, которая принимает объект со статическим лайфтаймом fn prove_static<T: 'static>(v: T) {} fn main() { // Это работает static VAR_STATIC: i32 = 5; let my1 = MyIntRef { r: &VAR_STATIC }; prove_static(my1); // Это не скомпилируется let var_local = 5; let my2 = MyIntRef { r: &var_local }; // doesn not live long enough prove_static(my2); }Получается, что наш пример даункаста от Person к Student/Teacher не будет работать, если мы добавим еще одну стукруту, которая реализует трэйт
Person, но содержит не'staticссылки? Да, именно так. Увы, но на сегодняшний существует такое ограничение. Впрочем, на практике, врядли вы когда-либо столкнётесь с ситуаций, когда вам нужно делать downcast для типа содержащего неstaticссылки.
Далее в коде, специально для трэйт-объекта dyn Person, мы определили метод, который проверяет, равно ли значение TypeId для типа, к которому хотят даункастить наш трэйт-обект, значению TypeId для типа объекта, который сокрыт за трэйт-объектом (Student или Teacher). Если да, то мы извлекаем из трэйт-объекта указатель на данные и приводим к желаемому типу ссылки. Иначе — возвращаем None.
#![allow(unused)]
fn main() {
impl dyn Base {
fn downcast<T: 'static>(&self) -> Option<&T> {
if TypeId::of::<T>() == self.exact_type() {
unsafe {
// Деструктурируем сслыку на трэйт-объект в пару указателей
let (data, _vtable): (*const u8, *const u8) =
std::mem::transmute(self);
// Приводим сырой указатель, к указателю на конкретный тип
let data: *const T = std::mem::transmute(data);
// Превращаем указатель в ссылку: as_ref() возвращает Option
data.as_ref()
}
} else {
None
}
}
}
}Чтобы понять, каким образом мы получаем ссылку на объект, сокрытый за трэйт-объектом, мы должны еще раз вспомнить, что из себя представляет ссылка на трэйт-объект. Она состоит из пары указателей:
- первый — непосредственно на данные
- второй — на vtable (таблицу виртуальных вызовов).
Поэтому мы сначала преобразовываем self (ссылку на трэйт-объект) в пару указателей, затем берём первый указатель и приводим его к ссылке желаемого типа.
Для приведения self к кортежу из двух указателей мы используем функцию transmute. Эта функция позволяет как бы посмотреть на одну и ту же память (последовательность байт) через призму другого типа. Разумеется, этой функцией надо пользоваться очень осторожно и учитывать не только размеры значений, но и возможные выравнивания. К счастью, в нашем случае мы имеем дело с двумя указателями, а они всегда имеют размер, равный размеру машинного слова, поэтому не нуждаются в выравнивании.
Tip
На самом деле фрагмент
#![allow(unused)] fn main() { let (data, _vtable): (*const u8, *const u8) = std::mem::transmute(self); let data: *const T = std::mem::transmute(data); data.as_ref() }можно записать куда проще:
#![allow(unused)] fn main() { Some(&*(self as *const dyn Person as *const T)); }однако такая запись прячет те детали работы с трэйт-объектом, которые мы хотели продемонстрировать явно.
Остальной код из примера должен быть понятен.
Даункаст с Any
Разумеется, реализовывать такой даункаст вручную неудобно и опасно, и в примере выше мы сделали это лишь для того, чтобы показать, как происходит даункаст на уровне памяти.
На практике же стандартная библиотека Rust предоставляет удобную (относительно) трэйт обёртку Any, которая инкапсулирует в себе TypeId, тем самым позволяя делать даункаст.
Трэйт Any имеет вид:
#![allow(unused)]
fn main() {
pub trait Any: 'static {
fn type_id(&self) -> TypeId;
}
impl<T: 'static + ?Sized> Any for T {
fn type_id(&self) -> TypeId {
TypeId::of::<T>()
}
}
}Как видно из объявления, абсолютно для любого типа, реализующего 'static, определена реализация Any, которая просто получает TypeId типа. По сути, это то же самое, что мы делали методом exact_type в примере выше.
Также для dyn Any определены такие методы:
pub fn is<T: Any>(&self) -> bool
Возвращаетtrue, если реальный тип, сокрытый за трэйт-объектом — этоTpub fn downcast_ref<T: Any>(&self) -> Option<&T>
Если реальный тип, сокрытый за трэйт-объектом — этоT, то возвращаетSome(&T), иначеNone.pub fn downcast_mut<T: Any>(&mut self) -> Option<&mut T>
Если реальный тип, сокрытый за трэйт-объектом — этоT, то возвращаетSome(&mut T), иначеNone.
Пример простого даункаста посредством Any:
use std::any::Any;
fn main() {
let s = "hello".to_string();
let any = &s as &dyn Any;
println!("any is i32: {}", any.is::<i32>()); // any is i32: false
println!("any is String: {}", any.is::<String>()); // any is String: true
println!("{:?}", any.downcast_ref::<i32>()); // None
println!("{:?}", any.downcast_ref::<String>()); // Some("hello")
}Если трэйт наследует Any, то его трэйт-объект автоматически получает возможность делать даункаст.
Перепишем с использованием Any наш пример с самописным даункастом.
use std::any::Any;
trait Person: Any {}
struct Student {
name: String,
year_of_education: u32,
}
impl Person for Student {}
struct Teacher {
name: String,
subject: String,
}
impl Person for Teacher {}
fn work_with_person(person: &dyn Person) {
let any = person as &dyn Any;
if let Some(s) = any.downcast_ref::<Student>() {
println!("This is {}, a {}-year student", s.name, s.year_of_education);
} else if let Some(t) = any.downcast_ref::<Teacher>() {
println!("This is {}, a teacher of {}", t.name, t.subject);
}
}
fn main() {
let student = Student {
name: "John".to_string(),
year_of_education: 3,
};
work_with_person(&student);
let teacher = Teacher {
name: "Ivan".to_string(),
subject: "Programming".to_string(),
};
work_with_person(&teacher);
}Результат работы программы такой же, как и с нашим собственным даункастом:
$ cargo run
This is John, a 3-year student
This is Ivan, a teacher of Programming
Коллекции
Стандартная библиотека Rust предоставляет такие типы коллекций:
- Vec<T> — Вектор: с ним мы уже знакомы
- LinkedList<T> — Двусвязный список
- VecDeque<T> — Динамически расширяемый кольцевой буфер. Ведёт себя как вектор, который позволяет добавлять элементы как в начало, так и в конец.
- HashMap<R,V> — Хеш-таблица
- HashSet<T> — Хеш-множество
- BTreeMap<K,V> — Словарь (ключ-значение), основанный на структуре B-дерево (B-Tree).
- BinaryHeap<T> — Очередь с приоритетом, основанная на двоичной куче.
Vec
Мы уже познакомились с вектором и его устройством в памяти в главе Вектор.
Давайте просто взглянем на примеры часто используемых методов.
use std::cmp::Ordering;
fn main() {
// Создаём вектор с буфером на 8 элементов
let mut v: Vec<i32> = Vec::with_capacity(10);
// Добавляем элементы
v.push(0);
v.push(4);
v.push(1);
v.push(3);
v.push(2);
// Добавляем в вектор сразу несколько элементов из слайса
v.extend_from_slice(&[5, 6]);
// Добавляем в вектор сразу несколько элементов из итератора
v.extend([8, 7, 9].iter());
println!("{v:?}"); // [0, 4, 1, 3, 2, 5, 6, 8, 7, 9]
// Сортируем вектор (по возрастанию)
v.sort();
println!("{v:?}"); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// Сортируем по убыванию
v.sort_by(|a, b| {
if a > b {
Ordering::Less
} else if a < b {
Ordering::Greater
} else {
Ordering::Equal
}
});
println!("{v:?}"); // [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
// Извлекаем последний элемент из вектора
println!("Last: {:?}", v.pop()); // Last: Some(0)
v.extend_from_slice(&[1, 2, 3]);
println!("{v:?}"); // [9, 8, 7, 6, 5, 4, 3, 2, 1, 1, 2, 3]
// Удаляем рядомстоящие дубликаты
v.dedup();
println!("{v:?}"); // [9, 8, 7, 6, 5, 4, 3, 2, 1, 2, 3]
}
LinkedList
LinkedList представляет из себя классический двусвязный список.
Каждый элемент представлен типом Node — структурой с тремя полями:
- значение элемента
- указатель на предыдущий элемент в списке
- указатель на следующий элемент.
Сам же список LinkedList — структура с полями:
- указатель на первый элемент списка
- указатель на последний элемент списка
- длина списка

В отличие от вектора, двусвязный список позволяет эффективно вставлять/удалять элементы в середину и начало списка.
Пример:
use std::collections::LinkedList;
fn main() {
let mut list = LinkedList::<i32>::new();
list.push_back(1); // [1]
list.push_back(2); // [1,2]
list.push_back(3); // [1,2,3]
list.push_front(0); // [0,1,2,3];
println!("{list:?}"); // [0, 1, 2, 3]
let last: Option<i32> = list.pop_back();
println!("{:?}", last); // Ok(3)
let first: Option<i32> = list.pop_front();
println!("{:?}", first); // 0
println!("{list:?}"); // [1, 2]
}VecDeque
Двусвязный список позволяет вставлять и удалять элементы в середине и в начале списка, но его недостатком является то, что операция доступа к элементу по индексу имеет сложность O(n/2), в отличие от сложности O(1) у вектора. Этот недостаток стремится исправить коллекция VecDeque.
VecDeque реализован как кольцевой буфер, что позволяет эффективно добавлять элементы в начало списка и относительно эффективно в середину списка. При этом VecDeque, как и вектор, имеет O(1) сложность доступа к элементу по индексу.

Пример использования:
use std::collections::VecDeque;
fn main() {
let mut v = VecDeque::from([1, 2, 3]);
v.insert(2, 99);
v.push_front(0);
println!("{v:?}"); // [0, 1, 2, 99, 3]
let last: Option<i32> = v.pop_back();
println!("{:?}", last); // Ok(3)
let first: Option<i32> = v.pop_front();
println!("{:?}", first); // 0
println!("{v:?}"); // [1, 2, 99]
}HashMap — Хеш-таблица
HashMap<K,V> — словарь, который хранит пары ключ-значение в виде хеш-таблицы.
Элементы хранятся в непрерывном буфере, поделённом на секции — бакеты (bucket).
При вставке новой пары:
- для ключа вычисляется хеш-код
- к хеш-коду применяется маска (bucket_mask), чтобы определить номер бакета, в котором будет храниться эта пара
- По номеру бакета (и “Control Bytes” преамбуле в начале буфера) определяется позиция в буфере, куда должна быть вставлена пара ключ-значение
- Если после вставки количество элементов (хранится в Control Bytes) в бакете превысило предельное значение (growth_left), то выделяется новый буфер большего размера и в него переносятся значения из текущего буфера.

Тип ключа должен реализовать трэйты Eq и Hash, а тип значения — PartialEq.
Пример использования:
use std::collections::HashMap;
fn main() {
let mut h: HashMap<i32, String> = HashMap::new();
h.insert(1, "one".to_string());
h.insert(2, "two".to_string());
h.insert(3, "three".to_string());
h.insert(4, "three".to_string());
h.insert(5, "three".to_string());
println!("Pairs:");
for (key, value) in h.iter() {
println!(" {key} -> {value}");
}
println!("Keys:");
for key in h.keys() {
println!(" {key}");
}
println!("Values:");
for value in h.values() {
println!(" {value}");
}
println!("Getting reference to value for key=1:");
if let Some(reference) = h.get(&1) {
println!(" {reference}");
}
println!("Extracting value for key=1:");
if let Some(value) = h.remove(&1) {
println!(" {value}");
}
println!("Contains key 1: {}", h.contains_key(&1));
}HashSet — Хеш-множество
HashSet<T> — хеш-множество, позволяющее быстро вставлять и искать элементы. Реализовано как обёртка над HashMap<T, ()>, поэтому всё, что справедливо для HashMap, справедливо и для HashSet.
Пример использования:
use std::collections::HashSet;
fn main() {
let mut s: HashSet<String> = HashSet::new();
s.insert("one".to_string());
s.insert("two".to_string());
s.insert("three".to_string());
for value in s.iter() {
println!("{value}");
}
if let Some(reference) = s.get(&"one".to_string()) {
println!("{reference}");
}
if let Some(value) = s.take(&"one".to_string()) {
println!("{value}");
}
println!("HashSet contains 'one': {}", s.contains(&"one".to_string()));
}BTreeMap
BTreeMap<K,V>, как и HashMap<K,V>, является словарём, который хранит пары ключ-значение. Разница лишь в том, что BTreeMap хранит данные в виде структуры B-дерево (B-Tree).

С точки зрения API, BTreeMap практически идентичен HashMap: в примере для HashMap вы можете заменить тип словаря на с HashMap на BTreeMap, и программа скомпилируется.
Единственная разница: для HashMap тип ключа должен реализовать трэйты Hash и Eq, а для BTreeMap тип ключа должен реализовать трэйт Ord.
Операции вставки и поиска для BTreeMap работают немного медленнее, чем для HashMap, особенно при большом размере словаря (больше тысячи элементов). Однако BTreeMap хранит элементы в отсортированном по ключу порядке, что может быть удобно в некоторых сценариях использования.
BinaryHeap
BinaryHeap<T> — очередь с приоритетом (priority queue), реализованная как двоичная куча (binary heap).
Куча реализована поверх вектора.

Note
Если читатель не знаком с двоичной кучей, то может создаться впечатление, что это не что иное, как двоичное дерево. Однако это не так. В двоичном дереве значения в левой ветви обязательно должны быть меньше значений в правой ветви, в то время как куча такого ограничения не имеет. Главное, только чтобы значение в родительском узле было больше/меньше (в зависимости от типа кучи), чем в дочерних.
При добавлении новых элементов или удалении существующих куча перестраивается таким образом, что самый верхний узел всегда содержит наибольший элемент. Просто снимая с кучи самый верхний элемент, мы получаем последовательность, отсортированную по убыванию.
Пример использования:
use std::collections::BinaryHeap;
fn main() {
let mut queue: BinaryHeap<i32> = BinaryHeap::new();
queue.push(2);
queue.push(7);
queue.push(1);
queue.push(4);
queue.push(9);
while let Some(element) = queue.pop() {
print!(" {element}"); // 9 7 4 2 1
}
}Так как BinaryHeap упорядочивает элементы путём сравнения, тип элементов должен реализовать трэйт Ord.
Ввод/вывод
Стандартная библиотека Rust предоставляет модуль std::io, который содержит универсальные интерфейсы и типы для операций ввода/вывода.
В этом модуле находятся два базовых трэйта, задающих единый интерфейс для чтения и записи: Read и Write.
Read
Трэйт Read определяет один необходимый к реализации метод — read и несколько вспомогательных методов, работающих поверх него.
#![allow(unused)]
fn main() {
pub trait Read {
fn read(&mut self, buf: &mut [u8]) -> Result;
// ...
}
}Вызов read заполняет переданные ему слайс байтами и возвращает количество байт, которые были записаны в слайс. Если размер слайса меньше, чем количество доступных байт, то метод read придётся вызвать несколько раз.
Остальные методы трэйта Read имеют реализацию по умолчанию. Некоторые из них:
fn read_to_end(&mut self, buf: &mut Vec<u8>) -> Result<usize>
Считывает всё содержимое в вектор байт.fn read_to_string(&mut self, buf: &mut String) -> Result<usize>
Считывает всё содержимое в в строку. Предполагается, что считываемые данные — текст.fn read_buf(&mut self, buf: BorrowedCursor<'_>) -> Result<()>
Считывает содержимое в курсор (о них мы поговорим позже).
Трэйт Read реализован для целого ряда типов: файл, сетевой сокет, Unix канал, STDIN (стандартный ввод), т.д.
Давайте рассмотрим работу с трэйтом Read на примере коллекции VecDeque<u8>, которую мы изучили в прошлой главе и которая также реализует трэйт Read.
Note
Программисты на Java могут провести аналогию с чтением из массива байт при помощи класса
java.io.ByteArrayInputStream.
use std::{collections::VecDeque, io::Read};
fn main() {
// Создаём VecDeque, из которого будем читать посредством трэйта Read
let mut v: VecDeque<u8> = VecDeque::from(vec![1, 2, 3, 4, 5, 6, 7, 8, 9]);
// Буфер размером в 2 байта. В него мы будем производить чтение
let mut buf: [u8; 2] = [0; 2];
// Считываем первый байт
let read_bytes: Result<usize, std::io::Error> = v.read(&mut buf);
println!("Buffer: {buf:?}, Number of read bytes: {read_bytes:?}");
// В цикле считываем оставшиеся байты
while let Ok(read_bytes) = v.read(&mut buf) && read_bytes > 0 {
println!("Buffer: {buf:?}, Number of read bytes: {read_bytes:?}");
}
}Вывод программы:
Buffer: [1, 2], Number of read bytes: Ok(2)
Buffer: [3, 4], Number of read bytes: 2
Buffer: [5, 6], Number of read bytes: 2
Buffer: [7, 8], Number of read bytes: 2
Buffer: [9, 8], Number of read bytes: 1
Если источник данных небольшой (все данные можно легко считать в оперативную память), то удобнее воспользоваться методом read_to_end:
use std::{collections::VecDeque, io::Read};
fn main() {
let mut v = VecDeque::from(vec![1, 2, 3, 4, 5, 6, 7, 8, 9]);
let mut buf: Vec<u8> = Vec::new();
let read_bytes: Result<usize, std::io::Error> = v.read_to_end(&mut buf);
println!("Buffer: {buf:?}, Number of read bytes: {read_bytes:?}");
// Buffer: [1, 2, 3, 4, 5, 6, 7, 8, 9], Number of read bytes: Ok(9)
}В случае если считываемые данные — текст, то подойдёт метод read_to_string:
use std::{collections::VecDeque, io::Read};
fn main() {
// 65 - 'A', 66 - 'B', 67 - 'C', 68 - 'D', 69 - 'E'
let mut v = VecDeque::from(vec![65, 66, 67, 68, 69]);
let mut buf = String::new();
let read_bytes: Result<usize, std::io::Error> = v.read_to_string(&mut buf);
println!("Buffer: {buf}, Number of read bytes: {read_bytes:?}");
// Buffer: ABCDE, Number of read bytes: Ok(5)
}Cursor
Коллекция VecDeque<u8> реализует трэйт Read, но коллекция Vec<u8> — нет. Так было сделано потому, что VecDeque позволяет эффективно извлекать элементы из начала коллекции (элементы, считанные из VecDeque посредством read, удаляются), а из Vec извлекать элементы эффективно можно только с конца. Однако если необходимо иметь возможность работать с Vec<u8> как с Read, то это можно сделать при помощи обёртки std::io::Cursor.
Cursor имеет два поля: оборачиваемая коллекция и текущая позиция курсора.
#![allow(unused)]
fn main() {
pub struct Cursor<T> {
inner: T,
pos: u64,
}
}Эта позиция позволяет эффективно реализовать операцию чтения: вместо того, чтобы удалять вычитанные элементы из вектора, курсор будет просто “сдвигать” позицию к еще не считанным байтам. Именно таким образом и реализован трэйт Read для Cursor.
#![allow(unused)]
fn main() {
impl<T> Read for Cursor<T> where T: AsRef<[u8]> {
fn read(&mut self, buf: &mut [u8]) -> io::Result<usize> {
let n = Read::read(&mut Cursor::split(self).1, buf)?;
self.pos += n as u64;
Ok(n)
}
}
}Как видим, Read реализован для любой вариации Cursor, которая хранит в себе любой тип, реализующий AsRef<u8>. Тип Vec<u8> как раз реализует AsRef<u8>.
use std::{io::Read, io::Cursor};
fn main() {
let v: Vec<u8> = vec![65, 66, 67, 68, 69];
let mut c: Cursor<Vec<u8>> = Cursor::new(v);
let mut buf = String::new();
let read_bytes: Result<usize, std::io::Error> = c.read_to_string(&mut buf);
println!("String: {buf}, Number of read bytes: {read_bytes:?}");
}Вывод программы:
String: ABCDE, Number of read bytes: Ok(5)
Write
Трэйт Write определяет универсальный интерфейс для записи данных.
В трэйте объявлены два обязательных к реализации метода и еще несколько методов с реализацией по умолчанию.
#![allow(unused)]
fn main() {
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
// ...
}
}Метод write записывает все байты из буфера-аргумента и возвращает количество фактически записанных байт. В конкретной реализации допускается записывать только часть байт, если эта часть может быть записана быстро, а запись оставшихся байт займёт существенно больше времени.
Метод flush имеет смысл для типов, которые перед фактической записью данных, предварительно буферизируют их в памяти. Вызов метода должен приводить к сбросу буферов в конечное хранилище данных.
Также трэйт содержит метод с реализацией по умолчанию — write_all.
#![allow(unused)]
fn main() {
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
}Этот метод, в отличие от write, должен записывать все байты, даже если это займёт существенно больше времени.
Как и Read, трэйт Write реализован для файла, сетевого сокета, Unix канала, STDOUT, т.д.
В отличие от Read, трэйт Write реализован не только для VecDeque<u8>, но и для Vec<u8>, так как вектор позволяет эффективно добавлять элементы в свой конец.
Рассмотрим пример записи байт в Vec<u8> посредством трэйта Write:
use std::io::Write;
fn main() {
let mut v: Vec<u8> = vec![1, 2, 3, 4, 5];
let count = v.write(&[6, 7, 8, 9]);
println!("Written: {count:?}, vec: {v:?}");
// Written: Ok(4), vec: [1, 2, 3, 4, 5, 6, 7, 8, 9]
}Стандартный вывод STDOUT также позволяет работать с собой через трэйт Write:
use std::io::Write;
fn main() {
let mut stdout = std::io::stdout();
let _ = stdout.write(&[65, 66, 67, 68, 69, 10]);
}Программа напечатает:
ABCDE
В следующей главе мы рассмотрим работу с Read и Write на примере файловой системы.
Файловая система
Note
Работа с файловой системой редко нужна при написании бекенд приложений, поэтому мы касаемся этой темы очень поверхностно.
Для работы с файловой системой стандартная библиотека Rust предоставляет такие модули:
- std::fs — содержит функциональность для работы непосредственно с объектами файловой системы: файлами, директориями, ссылками.
- std::io — содержит функциональность для работы с операциями ввода/вывода
Чтение и запись файла
Для примера работы с файлом напишем простую программу, которая:
- открывает новый файл, записывает в него текст, закрывает файл
- открывает этот же файл, добавляет в него строку, закрывает файл
- опять открывает файл и считывает из него всё содержимое в строку
use std::fs::{File, OpenOptions};
use std::io::{self, Read, Write};
fn main() -> io::Result<()> {
{
// Создаёт новый файл (или перезаписывает имеющийся)
let mut file = File::create("file.txt")?;
// Записывает в файл байты
file.write_all("First line\n".as_bytes())?;
file.flush()?; // Очистка буфера вывода
file.write_all("Second line\n".as_bytes())?;
}
{
// Открываем файл для добавления
let mut file = OpenOptions::new()
.append(true)
.create(false)
.open("file.txt")?;
file.write_all("Third line\n".as_bytes())?;
}
{
// Открываем файл для чтения
let mut file = File::open("file.txt")?;
let mut buffer = String::new();
file.read_to_string(&mut buffer)?;
println!("{buffer}");
}
Ok(())
}Первое, что бросается в глаза: мы открываем файл для записи, но не закрываем его. Дело в том, что для типа File реализован трэйт Drop: при выходе объекта из скоупа деструктор сбросит буфер вывода (вызовом flush), а после закроет файл.
Тип io::Result<T>, в который завёрнут результат всех методов ввода/вывода — это псевдоним, который объявлен как:
#![allow(unused)]
fn main() {
pub type Result<T> = result::Result<T, std::io::Error>;
}то есть это обычный Result, который параметризирован стандартной ошибкой для I/O операций.
Чтение директории
Напишем программу, которая выводит имена файлов и директорий, находящихся в текущем каталоге:
use std::{ffi::OsString, fs::FileType};
fn main() -> std::io::Result<()> {
for read_entry in std::fs::read_dir(".")? {
if let Ok(entry) = read_entry {
let entry_name: OsString = entry.file_name();
let file_type: FileType = entry.file_type()?;
println!("{entry_name:?} {file_type:?}");
}
}
Ok(())
}Вывод программы:
"target" FileType { is_file: false, is_dir: true, is_symlink: false, .. }
"Cargo.lock" FileType { is_file: true, is_dir: false, is_symlink: false, .. }
"src" FileType { is_file: false, is_dir: true, is_symlink: false, .. }
"Cargo.toml" FileType { is_file: true, is_dir: false, is_symlink: false, .. }
Как видите, имя директории хранится в объекте типа OsString. Это важный момент, который следует разобрать подробнее.
OsString
Почти все функции для работы с файловой системой в качестве строк используют не String, а OsString. Этот тип хранит строки в том представлении, в котором строки хранятся в текущей операционной системе.
Отдельный тип строки используется, потому что:
- В Unix-подобных системах имена файлов хранятся в виде последовательности ненулевых байт, которая содержит строку в UTF-8 или другой кодировке.
- На Windows имена файлов представлены последовательностями ненулевых двухбайтных значений (UTF-16).
- Rust строки всегда хранятся в UTF-8 кодировке, причем нулевые символы допустимы.
Для OsString реализованы From<String> и From<&str>, которые позволяют легко преобразовать “обычную” строку в OsString.
use std::ffi::OsString;
fn main() {
let string = "text";
let os_string = OsString::from(string);
}Как для типа String есть парный тип — строковый-слайс &str, так и для OsString есть соответствующий тип — &OsStr.
use std::ffi::{OsStr, OsString};
fn main() {
let string = "text";
let os_string = OsString::from(string);
let os_str: &OsStr = &os_string;
}В большинстве функций для работы с путями и именами файлов используется тип Path. Фактически, этот тип является просто обёрткой над OsStr:
#![allow(unused)]
fn main() {
pub struct Path {
inner: OsStr,
}
}Стандартная библиотека предоставляет From/Into и AsRef преобразования, которые позволяют бесшовно конвертировать Rust строки в Path.
Например, сигнатура метода File::create, который мы использовали в примере создания файла, имеет такой вид:
#![allow(unused)]
fn main() {
pub fn create<P: AsRef<Path>>(path: P) -> io::Result<File>
}И именно потому что для &str определён AsRef<Path>, мы смогли вызвать этот метод как:
#![allow(unused)]
fn main() {
let mut file = File::create("file.txt")?;
}Newtype паттерн
Одно из самых неудобных ограничений Rust — Orphan rule, о котором мы уже упоминали в главе Трэйты. Напомним, Orphan Rule гласит:
трэйт можно реализовать для типа только в том случае, если либо трэйт, либо тип (либо оба) принадлежит крэйту (библиотеке или программе), в которой осуществляется реализация.
Другими словами, если мы хотим реализовать трэйт A для типа B, то код реализации должен располагаться либо в крэйте, где объявлен тип B, либо в крэйте, где объявлен трэйт A.
А теперь давайте представим, что у нас есть задача, в рамках которой нам надо сортировать вектор с объектами файлов:
use std::fs::File;
fn main() {
let mut v = vec![
File::open("/etc/fstab").unwrap(),
File::open("/etc/resolv.conf").unwrap(),
File::open("/etc/hosts").unwrap(),
];
v.sort();
}Note
Для пользователей, не знакомых с Linux:
/etc/fstab— стандартный файл конфигурации разделов жесткого диска/etc/resolv.conf— файл с адресами DNS серверов/etc/hosts— файл для задания соответствий доменных имён и IP адресовАвтор взял эти файлы без какого-то специального умысла. Проверяя примеры из главы, вы вольны использовать любые имеющиеся у вас файлы или создать новые.
Метод .sort() требует, чтобы тип сортируемых объектов реализовал трэйт Ord. Тип std::fs::File не реализует Ord, поэтому компиляция завершится с ошибкой:
error[E0277]: the trait bound `File: Ord` is not satisfied
--> src/main.rs:8:7
|
8 | v.sort(); // the trait `Ord` is not implemented for `File`
| ^^^^ the trait `Ord` is not implemented for `File`
Допустим, мы хотим реализовать Ord для File так, чтобы сортировка происходила на основании размера файла. Здесь и проявляется Orphan Rule: и тип File, и трэйт Ord объявлены не в нашем крэйте, а в стандартной библиотеке.
Стандартным решением этой проблемы является Newtype паттерн. Смысл его заключается в том, что мы оборачиваем “чужой” тип в кортежную структуру, и получается, что эта обёртка уже располагается в нашем крэйте.
#![allow(unused)]
fn main() {
struct Обёртка(ЧужойТип);
}Теперь для этой обёртки мы можем реализовать Ord. Давайте сделаем это, и сразу напишем нашу программу для сортировки файлов по возрастанию их размера.
use std::{cmp::Ordering, fs::File};
// Newtype обёртка для File.
struct FileWrapper(File);
impl PartialEq for FileWrapper {
fn eq(&self, other: &Self) -> bool {
match (self.0.metadata(), other.0.metadata()) {
(Ok(m1), Ok(m2)) => m1.len() == m2.len(),
_ => false,
}
}
}
impl Eq for FileWrapper {}
impl Ord for FileWrapper {
fn cmp(&self, other: &Self) -> Ordering {
match (self.0.metadata(), other.0.metadata()) {
(Ok(m1), Ok(m2)) => m1.len().cmp(&m2.len()),
_ => Ordering::Equal,
}
}
}
impl PartialOrd for FileWrapper {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
Some(self.cmp(other))
}
}
fn main() {
let mut v: Vec<FileWrapper> = vec![
FileWrapper(File::open("/etc/fstab").unwrap()),
FileWrapper(File::open("/etc/resolv.conf").unwrap()),
FileWrapper(File::open("/etc/hosts").unwrap()),
];
println!("Before sorting");
for file in v.iter() {
println!("Size: {}", file.0.metadata().unwrap().len());
}
v.sort();
println!("After sorting");
for file in v.iter() {
println!("Size: {}", file.0.metadata().unwrap().len());
}
}Запустим программу:
$ cargo run
Before sorting
Size: 866
Size: 920
Size: 219
After sorting
Size: 219
Size: 866
Size: 920
Всё работает. Однако, как вы могли заметить, нам приходится явно запаковывать объекты File в обёртку FileWrapper. К тому же для доступа к объекту файла внутри обёртки, нам приходится использовать индекс .0 (в примере: file.0.metadata()), что не очень элегантно.
Для решения этой проблемы, при использовании newtype паттерна, для типа обёртки принято реализовывать трэйты From и Deref. Это позволит:
- заворачивать оригинальный тип в обёртку вызовом метода
.into() - обращаться к обёрнутому объекту без использования поля
.0
Полный пример программы:
use std::{cmp::Ordering, fs::File, ops::Deref};
struct FileWrapper(File);
impl PartialEq for FileWrapper {
fn eq(&self, other: &Self) -> bool {
match (self.0.metadata(), other.0.metadata()) {
(Ok(m1), Ok(m2)) => m1.len() == m2.len(),
_ => false,
}
}
}
impl Eq for FileWrapper {}
impl Ord for FileWrapper {
fn cmp(&self, other: &Self) -> Ordering {
match (self.0.metadata(), other.0.metadata()) {
(Ok(m1), Ok(m2)) => m1.len().cmp(&m2.len()),
_ => Ordering::Equal,
}
}
}
impl PartialOrd for FileWrapper {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
Some(self.cmp(other))
}
}
impl From<File> for FileWrapper {
fn from(value: File) -> Self {
FileWrapper(value)
}
}
impl Deref for FileWrapper {
type Target = File;
fn deref(&self) -> &Self::Target {
&self.0
}
}
fn main() {
let mut v: Vec<FileWrapper> = vec![
// Вызовом .into() преобразовываем File в Newtype обёртку
File::open("/etc/fstab").unwrap().into(),
File::open("/etc/resolv.conf").unwrap().into(),
File::open("/etc/hosts").unwrap().into(),
];
println!("Before sorting");
for file in v.iter() {
// Ниже мы вызываем file.metadata(), а не file.0.metadata()
// так как мы реализовали Deref
println!("Size: {}", file.metadata().unwrap().len());
}
v.sort();
println!("After sorting");
for file in v.iter() {
println!("Size: {}", file.metadata().unwrap().len());
}
}Паника
panic
Когда в программе происходит какое-то недопустимое действие, например, деление на ноль или вызов unwrap() на объекте None, то происходит паника.
Например:
fn main() {
let a: Option<i32> = None;
a.unwrap();
}выведет
$ cargo run
thread 'main' panicked at src/main.rs:3:7:
called `Option::unwrap()` on a `None` value
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Паника аварийно завершает программу и печатает на стандартный вывод информацию о случившейся ошибке.
Панику также можно инициировать вручную при помощи макроса panic. Синтаксис его использования такой же, как у макроса println!, но вместо вывода на консоль, он завершит программу и напечатает переданное сообщение.
Например, такой код:
fn main() {
let a = 5;
panic!("Ending the program here. Num: {}", a);
}выведет:
$ cargo run
thread 'main' panicked at src/main.rs:3:5:
Ending the program here. Num: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Перехват паники
По умолчанию паника аварийно завершает выполнение программы. Однако это не всегда является желаемым поведением. Например, при разработке веб-сервера при возникновении паники в обработчике запроса от пользователя, как правило, мы предпочитаем просто возвращать HTTP 500, а не завершать работу всего сервера.
Стандартная библиотека предоставляет функцию-обёртку catch_unwind, которая принимает на вход замыкание и выполняет его.
pub fn catch_unwind<F: FnOnce() -> R + UnwindSafe, R>(f: F) -> Result<R>Если замыкание отрабатывает без ошибок, то его результат возвращается завёрнутым в Ok, если же при выполнении возникла паника, то будет возвращено Err.
Note
Напомним, что если функция ожидает в качестве аргумента
FnOnceзамыкание, то в неё можно передавать иFnMut, иFn, и просто указатель на функциюfn.
Рассмотрим пример:
use std::panic;
use std::panic::catch_unwind;
use std::any::Any;
fn main() {
let result: Result<(), Box<dyn Any + Send + 'static>> = catch_unwind(|| {
panic!("My panic msg");
});
println!("Result: '{:?}'", result);
println!("Continue working...");
}эта программа печатает
$ cargo run
thread 'main' panicked at src/main.rs:5:9:
My panic msg
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Result: 'Err(Any { .. })'
Continue working...
Тот факт, что catch_unwind возвращает панику как Err, содержащий Any, словно намекает, что паника может содержать некий объект. И это так. Для случаев, когда через панику надо передать объект, существует функция panic_any, которая принимает объект любого типа, реализующего Any.
#![allow(unused)]
fn main() {
pub fn panic_any<M: 'static + Any + Send>(msg: M) -> !
}Для примера напишем простую функцию, которая эмулирует обработчик запроса от пользователя. Эта функция будет принимать текстовый запрос и возвращать текстовый ответ. В случае возникновения ошибки, функция может выбросить панику, содержащую объект, который описывает проблему.
use std::{any::Any, panic, panic::panic_any};
/// Тип для ошибки, которая будет пробрасываться через панику
#[derive(Debug)]
enum ProcessingErr {
NotAuthorized,
AnotherImportantError,
}
/// Некий обработчик ошибки, который может паниковать
fn serve_request(req: &str) -> String {
panic_any(ProcessingErr::NotAuthorized);
}
fn main() {
let request = "Some request"; // Эмулирует некий запрос
let closure_result: Result<String, Box<dyn Any + Send + 'static>> =
panic::catch_unwind(|| serve_request(request));
if let Err(a) = closure_result {
if let Some(panic_obj) = a.downcast_ref::<ProcessingErr>() {
println!("Panic object: {panic_obj:?}");
}
}
}Программа напечатает:
# cargo run
thread 'main' panicked at src/main.rs:12:5:
Box<dyn Any>
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Panic object: NotAuthorized
Таким образом, мы смогли через панику получить информацию о проблеме, которая привела к ошибке.
Caution
Имейте в виду, что мы написали такую программу исключительно для демонстрации возможностей проброса объектов через панику. Использовать панику подобно исключениям для обработки ошибок — очень плохая затея. Паника должна использоваться только для серьёзных проблем, которые не являются нормой. Для остальных случаев используйте
Result.
Обработчик паники
Как мы заметили в примере выше, даже при том, что мы перехватываем панику функцией catch_unwind, на консоль всё равно печатается сообщение паники, и место, откуда она была выброшена:
thread 'main' panicked at src/main.rs:5:9:
My panic msg
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Так происходит, потому что по умолчанию для паники установлен стандартный предобработчик, который выполняется до того, как паника будет перехвачена в catch_unwind.
Если нам нужно другое поведение, то мы можем задать свой предобработчик для паники при помощи функции set_hook.
use std::panic::{self, PanicHookInfo};
fn my_panic_hook<'a>(p: &PanicHookInfo<'a>) {
println!("Hello from panic hook");
println!("Location: {:?}", p.location());
println!("Payload: {:?}", p.payload());
}
fn main() {
panic::set_hook(Box::new(my_panic_hook));
panic!("Original panic msg");
}Такая программа напечатает:
$cargo run
Hello from panic hook
Location: Some(Location { file: "src/main.rs", line: 12, column: 5 })
Payload: Any { .. }
Макросы, инициирующие панику
Чтобы завершить тему макросов, стоит упомянуть несколько макросов, которые также инициируют панику.
todo и unimplemented
Макросы todo и unimplemented служат одной и той же цели: они являются заполнителями для кода, который еще не имплементирован. Отличительной особенностью этих макросов является то, что они “возвращают” тот тип, который от них ожидается. Например:
fn my_func() -> String {
todo!("Don't forget to implement")
}
fn main() {
let s = my_func();
println!("{s}");
}Этот код компилируется без ошибок, но при попытке выполнить программу она паникует:
$ cargo run
thread 'main' panicked at src/main.rs:2:5:
not yet implemented: Don't forget to implement
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Функция my_func возвращает значение типа String, поэтому вызов макроса todo как бы возвращает тип String. Это очень удобно, так как можно вставлять todo в любом месте, какой бы сложный тип там ни ожидался, и компилятор будет удовлетворён.
Причём todo можно использовать в любом контексте, а не только при возврате значений из функции:
#![allow(unused)]
fn main() {
let r: Result<(), Box<dyn Error>> = todo!();
}Макрос unimplemented работает точно таким же образом, как и todo, различие исключительно семантическое: todo подразумевает, что функциональность должна быть реализована в текущей итерации разработки, а unimplemented предполагает, что функциональность может быть реализована позже.
unreachable
Макрос unreachable также инициирует панику. Однако в отличие от todo и unimplemented, он используется для участков кода, которые чисто технически могут быть выполнены, но на практике выполнение никогда не должно доходить до них (обычно вследствие предварительной проверки аргументов).
Например:
#![allow(unused)]
fn main() {
/// Данная функция ожидает версию API либо 1, либо 2.
/// Проверка версии API ложится на вызывающий код
fn get_user_by_id(id: u64, api_version: u32) {
match api_version {
1 => v1_get_user_by_id(id),
2 => v2_get_user_by_id(id),
_ => unreachable!("Unknown api version"),
}
}
}Многопоточность
Когда речь заходит о параллельном программирования, Rust предоставляет:
- традиционную многопоточность, основанную на потоках, управляемых операционной системой
- асинхронность, позволяющую выполнять функциональность на асинхронном рантайме, работающем в пользовательском пространстве (user space)
В этой главе мы рассмотрим работу с потоками операционной системы.
Создание потока
Для создания нового потока используется функция std::thread::spawn:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T + Send + 'static,
T: Send + 'static,В качестве аргумента функция spawn принимает замыкание FnOnce, которое запускается на новом потоке. Разумеется, можно передать не только FnOnce, но и FnMut, и Fn, и fn(). Про трэйт Send мы поговорим немного позже.
Функция spawn возвращает объект типа JoinHandle, который позволяет:
- получить информацию о потоке
- ожидать завершения потока
- получить результат, с которым завершилась функция потока
Рассмотрим простой пример: создадим два потока, каждый из которых просто возвращает число. Потоки будут создаваться на основе анонимных функций.
use std::thread::{self, JoinHandle};
fn main() {
let t1: JoinHandle<i32> = thread::spawn(||{ 1 });
let t2: JoinHandle<i32> = thread::spawn(||{ 2 });
let sum = t1.join().unwrap() + t2.join().unwrap();
println!("{sum}"); // 3
}Поток можно создать и из обычной функции:
use std::thread;
fn print_nums() {
let thread_id = thread::current().id(); // ID текущего потока
for i in 1 .. 5 {
println!("thread: {thread_id:?}, num: {i}");
thread::sleep(std::time::Duration::from_millis(100));
}
}
fn main() {
let t1 = thread::spawn(print_nums);
let t2 = thread::spawn(print_nums);
let _ = t1.join();
let _ = t2.join();
}Эта программа печатает:
thread: ThreadId(2), num: 1
thread: ThreadId(3), num: 1
thread: ThreadId(2), num: 2
thread: ThreadId(3), num: 2
thread: ThreadId(2), num: 3
thread: ThreadId(3), num: 3
thread: ThreadId(2), num: 4
thread: ThreadId(3), num: 4
На самом деле для запуска потоков используется билдер std::thread::Builder, который позволяет относительно тонкую настройку для создаваемого потока. Функция std::thread::spawn просто перевызывает std::thread::Builder::new().spawn(замыкание) с параметрами по умолчанию. Однако если необходимо задать такие параметры, как имя потока или размер стека, то это можно сделать, создав поток непосредственно при помощи билдера.
fn main() {
let t = std::thread::Builder::new()
.name("my_thread".to_string())
.stack_size(8192)
.spawn(|| {
println!("thread name: {:?}", std::thread::current().name())
})
.unwrap();
let _ = t.join();
}трэйт Send
Настало время поговорить о перемещении объектов между потоками и о роли трэйта Send.
Давайте взглянем на такой пример:
use std::thread;
fn main() {
let user = "John Doe".to_string();
let t1 = thread::spawn(move || {
println!("{}", user);
});
let _ = t1.join();
}Здесь всё просто: в главном потоке мы создаём объект строки, а дальше используем этот объект в порождённом потоке.
С ключевым словом move мы уже знакомы: оно означает, что если какое-то значение из внешнего контекста используется замыканием (включая использование по ссылке), то владение этим объектом должно быть перемещено к замыканию.
Теперь давайте модифицируем эту программу: обернём строку в умный указатель Rc.
use std::{rc::Rc, thread};
fn main() {
let user = Rc::new("John Doe".to_string());
let t1 = thread::spawn(move || {
println!("{}", user);
});
let _ = t1.join();
}Компиляция завершится с ошибкой:
error[E0277]: `Rc<String>` cannot be sent between threads safely
--> src/main.rs:5:28
|
5 | let t1 = thread::spawn(move || {
| ------------- ^------
| | |
| ______________|_____________within this `{closure@src/main.rs:5:28: 5:35}`
| | |
| | required by a bound introduced by this call
6 | | println!("{}", user);
7 | | });
| |_____^ `Rc<String>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:5:28: 5:35}`,
the trait `Send` is not implemented for `Rc<String>`
Ошибка говорит, что объект типа Rc нельзя пересылать между потоками, так как тип Rc не реализует трэйт Send.
Send — маркерный трэйт, который указывает на то, что объект данного типа можно пересылать между потоками.
Объекты типа Rc небезопасно пересылать между потоками. Чтобы понять почему, давайте представим себе такой сценарий:
- В главном потоке мы создаём объект
Rc. Как мы помним, Rc состоит из двух полей: указатель на данные в куче и указатель на счётчик (количество владельцев), который также расположен в куче. - Мы клонируем
Rcи получаем уже два объектаRcссылающихся на один и тот же объект в куче. - Мы передаём второй объект
Rcв другой поток. - Одновременно в главном потоке и во втором потоке мы клонируем объекты
Rc.
Так как счётчик, находящийся в куче, никак не синхронизирован для многопоточного доступа, есть вероятность, что одновременное инкрементирование счётчика из разных потоков приведёт к записи некорректного значения. Отсюда легко понять, что Rc небезопасно пересылать между потоками, поэтому для Rc не реализован трэйт Send.
Трэйт Send автоматически реализуется компилятором для любого типа, если он не содержит полей, которые не Send (например, полей типа PhantomData или *mut T).
Для демонстрации создадим свой тип, который не является Send:
struct User {
name: String,
ptr: *mut u32, // *mut T указатель - не Send
}
// Эту функцию можно вызвать только параметризировав Send типом
fn prove_send<T: Send>() {}
fn main() {
prove_send::<User>(); // ошибка, User не Send
}Если нам всё-таки понадобится иметь возможность пересылать объекты типа User между потоками, т.е. сделать его Send, то мы всегда можем явно реализовать трэйт Send так:
struct User {
name: String,
ptr: *mut u32, // *mut T указатель - не Send
}
unsafe impl Send for User { } // явно реализуем Send
fn prove_send<T: Send>() {}
fn main() {
prove_send::<User>(); // работает без ошибок
}Разумеется, unsafe имплементация трэйта — явно говорит о том, что теперь вся ответственность по корректной работе с указателями ложится на плечи разработчика. А следовательно, нам самим придётся позаботиться о синхронизации доступа к полю ptr.
Sync
Другой важный в контексте многопоточности трэйт — Sync. Этот трэйт тоже маркерный, и он автоматически реализуется компилятором для любого типа, если немутабельную ссылку на значение этого типа можно безопасно использовать из разных потоков.
Формально говоря: T является Sync, если немутабельная ссылка &T является Send.
Большая часть стандартных типов реализует Sync. Как и в случае с Send, исключение составляют типы, которые инкапсулируют в себе указатель, и при этом не предусматривают никакого механизма синхронизации работы с этим указателем из разных потоков. Например, такие типы, как Rc и Cell, не реализуют Sync.
Рассмотрим пример, который демонстрирует, что String реализует Sync.
fn main() {
static s: String = String::new();
let r1 = &s;
let r2 = &s;
let t1 = std::thread::spawn(move || {
println!("{}", r1);
});
let t2 = std::thread::spawn(move || {
println!("{}", r2);
});
let _ = t1.join();
let _ = t2.join();
}Так как String является Sync, мы можем использовать ссылки на один и тот же объект из разных потоков.
Также в этом примере нам пришлось объявить строку как статическую переменную. Это необходимо ввиду того, что в текущей реализации компилятор не может отследить, что запущенный поток не переживёт скоуп, которому принадлежит переменная, владеющая объектом String, захваченным по ссылке. А объявив переменную как static, мы продлеваем время её жизни до момента завершения программы.
Теперь давайте заменим String на Cell, который не реализует Sync, и попытаемся скомпилировать программу.
use std::cell::Cell;
fn main() {
static c: Cell<i32> = Cell::new(5);
let t1 = std::thread::spawn(move || {
println!("{:?}", &c);
});
let t2 = std::thread::spawn(move || {
println!("{:?}", &c);
});
let _ = t1.join();
let _ = t2.join();
}Ожидаемо компилятор выдал ошибку, сообщающую, что Cell не реализует Sync`:
error[E0277]: `Cell<i32>` cannot be shared between threads safely
--> src/main.rs:4:15
|
4 | static c: Cell<i32> = Cell::new(5);
| ^^^^^^^^^ `Cell<i32>` cannot be shared between threads safely
|
= help: the trait `Sync` is not implemented for `Cell<i32>`
= note: shared static variables must have a type that implements `Sync
Как и в случае с Send, мы можем явно реализовать Sync для нашего типа, при этом вся ответственность за безопасную работу с несинхронизированными полями ляжет на нас.
#![allow(unused)]
fn main() {
unsafe impl Sync for НашТип {}
}Механизмы синхронизации
Теперь, когда мы познакомились с Send и Sync, мы готовы рассмотреть механизмы синхронизации доступа к данным из разных потоков. Стандартная библиотека Rust предлагает такие механизмы синхронизации:
- Mutex — позволяет в любую единицу времени иметь эксклюзивный доступ к ресурсу только для одного потока
- RwLock — позволяет либо множественный доступ для чтения, либо эксклюзивный доступ для записи
- Condvar — позволяет одному потоку уснуть и ждать, пока другой поток не пробудит его
- Barrier — позволяет синхронизировать между собой несколько потоков в некоторой точке
Mutex
Как и в других языках программирования, в Rust мьютекс — механизм, который позволяет только одному потоку получить эксклюзивный доступ к ресурсу. Все остальные потоки, желающие в этот момент получить доступ к ресурсу, находятся в состоянии ожидания до момента, пока поток, захвативший ресурс, не отпустит его.
Мьютекс представлен типом std::sync::Mutex. Чтобы обернуть объект в мьютекс, используется метод конструктор new:
use std::sync::Mutex;
fn main() {
let m: Mutex<i32> = Mutex::new(5);
}Для того, чтобы получить доступ к объекту внутри мьютекса, используется метод lock(). Этот метод позволяет получить объект умного указателя MutexGuard, который предоставляет мутабельную ссылку на объект внутри мьютекса (MutexGuard реализует трэйт DerefMut).
use std::sync::{Mutex, MutexGuard, PoisonError};
fn main() {
let m: Mutex<i32> = Mutex::new(5);
{
// захватываем ресурс мьютекса
let lock_attempt: Result<MutexGuard<'_, i32>, PoisonError<_>> = m.lock();
let mut guard = lock_attempt.unwrap();
*guard = 6;
} // отпускаем мьютекс
}Мы не зря вызвали lock в отдельном блоке из фигурных скобок — скоупе. Дело в том, что пока существует объект MutexGuard, мьютекс остаётся захваченным, но как только он уничтожается, мьютекс освобождается. Именно поэтому желательно минимизировать область, в которой существует объект MutexGuard.
Теперь поговорим о работе с мьютексом из разных потоков. Как мы знаем, на потоке выполняется функция или замыкание. В обоих случаях, чтобы поток мог работать с неким объектом, этот объект надо отдать потоку во владение. Проблема в том, что мы не можем отдать один объект мьютекса во владение двум потокам. Мы также не можем клонировать мьютекс. Здесь на помощь приходит умный указатель Arc (Atomic Reference Counting) — потокобезопасная версия Rc. Мы просто оборачиваем мьютекс в Arc, и это позволяет передавать разделяемую ссылку на мьютекс в разные потоки.
use std::{sync::{Arc, Mutex}, thread};
fn main() {
let m_original: Arc<Mutex<i32>> = Arc::new(Mutex::new(5));
let m_clone = m_original.clone();
let t = thread::spawn(move|| {
if let Ok(mut guard) = m_clone.lock() {
*guard = 6;
}
});
let _ = t.join();
println!("{m_original:?}"); // Mutex { data: 6, poisoned: false, .. }
}Как видите, мьютекс был распечатан как Mutex { data: 6, poisoned: false, .. }.
Здесь поле data — значение внутри мьютекса, а поле poisoned — индикатор, отравлен ли мьютекс (об этом мы поговорим в следующей секции).
Рассмотрим пример счётчика, который одновременно инкрементируется из двух разных потоков.
use std::{sync::{Arc, Mutex}, thread::{self, JoinHandle}};
fn start_counter_thread(counter: Arc<Mutex<i32>>) -> JoinHandle<()> {
thread::spawn(move || {
for _ in 0 .. 1000 {
if let Ok(mut guard) = counter.lock() {
*guard += 1;
}
}
})
}
fn main() {
let counter = Arc::new(Mutex::new(0));
let t1 = start_counter_thread(counter.clone());
let t2 = start_counter_thread(counter.clone());
let _ = t1.join();
let _ = t2.join();
println!("{counter:?}"); // Mutex { data: 2000, poisoned: false, .. }
}Благодаря мьютексу все операции инкремента произошли корректно.
Warning
Про лайфтайм mutex guard.
В случае, когда со значением, завёрнутым в мьютекс, надо выполнить только одно действие, можно обойтись одним выражением
lock()без открытия нового скоупа. Например, если мы хотим извлечь элемент из вектора, завёрнутого в мьютекс, то мы можем написать такое:#![allow(unused)] fn main() { let list: Mutex<Vec<i32>> = ...; let last: Option<i32> = list.lock().unwrap().pop(); if let Some(element) = last { process_element(element); } }Здесь на второй строке, вызовом
.lock()создаётся объект guard, который сразу же и уничтожается по завершении выражения. Таким образом, область захвата мьютекса ограничивается только этим одним выражением.Может появиться соблазн сократить этот код таким образом:
#![allow(unused)] fn main() { let list: Mutex<Vec<i32>> = ...; if let Some(element) = list.lock().unwrap().pop() { process_element(element); } }Однако, если вы ожидали, что мьютекс будет использован только для получения элемента, а затем сразу же освободится, то это не так. Объекты, созданные в заголовке выражений if-let и while-let, живут до самого конца скоупа этих выражений. То есть в течение всего выполнения функции
process_element, мьютекс будет оставаться захваченным.
Отравленный мьютекс
Если поток, уже захвативший мьютекс, завершается с паникой, то мьютекс помечается как отравленный (poisoned).
Если другой поток попытается захватить отравленный мьютекс, то вызов метода .lock() вернет ошибку PoisonError.
use std::{sync::{Arc, Mutex}, thread};
fn main() {
let m = Arc::new(Mutex::new(5));
let m1 = m.clone();
let t1 = thread::spawn(move|| {
let guard = m1.lock().unwrap();
// Инициируем панику, чтобы отравить мьютекс
panic!("poisoning mutex...");
});
let _ = t1.join();
// Проверяем отравлен ли мьютекс
println!("{}", m.is_poisoned()); // true
let lock_attempt_1 = m.lock();
// Отравленный мьютекс вместо Ok(Guiard) возвращает PoisonError
println!("{lock_attempt_1:?}"); // Err(PoisonError { .. })
// При этом, из PoisonError всё равно можно извлечь объект Guard.
// Извлекая Guard из PoisonError мы явно понимаем, что мьютекс отправлен.
if let Err(e) = lock_attempt_1 {
let guard = e.into_inner();
println!("Value: {}", *guard); // 5
}
// Отравленный мьютекс можно вернуть к нормальному состоянию.
m.clear_poison();
println!("{}", m.is_poisoned()); // false
}Основное назначение PoisonError — явно проинформировать, что другой поток, захвативший мьютекс, завершился с паникой. В некоторых сценариях, эта информация поможет корректно завершить или откатить операцию, которую не смог выполнить поток, завершившийся с паникой.
RwLock
Если мьютекс предоставляет только эксклюзивный доступ к ресурсу, то RwLock разделяет доступ на чтение и доступ на запись. Сколько угодно потоков могут одновременно захватывать ресурс на чтение, но захват на запись происходит эксклюзивно, как у мьютекса.
use std::sync::RwLock;
fn main() {
let rw_lock = RwLock::new(5);
{ // Захват на чтение
let lock_attempt = rw_lock.read();
if let Ok(guard) = lock_attempt {
println!("Read: {}", *guard);
}
}
{ // Захват на запись
let lock_attempt = rw_lock.write();
if let Ok(mut guard) = lock_attempt {
*guard = 10;
println!("Updated: {}", *guard);
}
}
println!("{rw_lock:?}");
}Аналогично мьютексу, RwLock тоже надо “заворачивать” в Arc, чтобы передать в несколько потоков.
RwLock становится отравленным только если поток, завершившийся с паникой, произвёл захват для записи. Паника при захвате для чтения не приводит к отравлению RwLock.
Condvar
Тип Condvar позволяет одному потоку ожидать, пока другой поток изменит значение некой переменной на ожидаемое.
Condvar всегда используется в паре с мьютексом, и принцип этого взаимодействия проще понять на примере.
В качестве примера возьмём классическую для Condvar задачу: один поток должен ожидать, пока другой поток не выполнит какое-то действие. Реализуется это путём того, что:
- один поток ожидает, пока булевая переменная, завёрнутая в мьютекс, не поменяет своё значение с
falseнаtrue - другой поток после выполнения какой-то работы меняет значение этой булевой переменной, завёрнутой в мьютекс, на
true
use std::sync::{Arc, Mutex, Condvar};
use std::thread;
fn main () {
// Создаём Convdar с булевым флагом
let cond = Arc::new((Mutex::new(false), Condvar::new()));
let cond_copy = Arc::clone(&cond);
thread::spawn(move || {
// Этот поток эмулирует некие приготовления,
// в конце которых condvar флаг будет выставлен в true
let (mutex, cvar) = &*cond_copy;
let mut flag_guard = mutex.lock().unwrap();
*flag_guard = true;
cvar.notify_one();
});
let (mutex, cvar) = &*cond;
let mut flag_guard = mutex.lock().unwrap();
// Здесь мы ожидаем, пока в порождённом потоке флаг не будет выставлен в true
while !(*flag_guard) {
flag_guard = cvar.wait(flag_guard).unwrap();
}
}Здесь в строке flag_guard = cvar.wait(flag_guard).unwrap(); главный поток “засыпает” на вызове wait и ожидает, пока на этом же объекте Condvar не будет вызвано notify_one. После вызова notify_one во втором потоке главный поток просыпается и проверяет обновлённое значение флага, скрытое за объектом MutexGuard.
Обратите внимание, что передача MutexGuard в вызов wait освобождает мьютекс. Без этого второй поток не смог бы захватить мьютекс в строке let mut flag_guard = mutex.lock().unwrap(), и произошёл бы так называемый dead lock.
Кроме notify_one, у Condvar существует еще метод notify_all, который можно использовать, если несколько потоков вызвали wait на одном объекте Condvar. То есть notify_one пробуждает только один поток, вызвавший wait, а notify_all пробуждает все.
Barrier
Barrier (барьер) — механизм, который позволяет набору потоков ожидать друг друга, пока все из них не будут готовы начать работу.
use std::sync::{Arc, Barrier, Mutex};
use std::thread;
const WORKERS_NUM: usize = 10;
fn main() {
let data = (0..100).collect::<Vec<_>>();
let mutex = Arc::new(Mutex::new(data));
let barrier = Arc::new(Barrier::new(WORKERS_NUM));
let mut workers = Vec::new();
for _ in 0 .. WORKERS_NUM {
let mutex_clone = mutex.clone();
let barrier_clone = barrier.clone();
let t = thread::spawn(move || {
loop {
// Ждём здесь пока все 10 потоков не вызовут эту строку
barrier_clone.wait();
let Some(element) = mutex_clone.lock().unwrap().pop() else {
break;
};
println!("Processing {element} by {:?}", thread::current().id());
}
});
workers.push(t);
}
workers.into_iter().for_each(|t| t.join().unwrap());
}Запустив этот код, вы можете убедиться, что массив данных (вектор из 100 элементов) обрабатывается порциями по 10 элементов, и каждый элемент обрабатывается отдельным потоком.
scoped thread
Одним из неприятных ограничений потоков является то, что даже если поток запускается в теле функции и прекращает свою работу до того, как эта функция завершилась (потому что на потоке вызывается join), этот поток всё равно не может обращаться по ссылке к локальным переменным функции, без перемещения владения над ними. Например:
fn main() {
let s = "Hello".to_string();
let thread = std::thread::spawn(|| {
println!("{}", &s);
});
let _ = thread.join(); // поток завершается здесь
}Компиляция этой программы завершается со следующей ошибкой:
closure may outlive the current function, but it borrows `s`,
which is owned by the current function
Порождённый поток гарантированно завершается до окончания скоупа функции main, однако компилятор не умеет анализировать вызовы .join(), поэтому всё равно утверждает, что ссылку на s небезопасно использовать из порождённого потока, так как поток, якобы, может прожить дольше, чем функция main.
Именно для таких ситуаций, когда время жизни потоков гаратированно ограничено скоупом функции, в которой эти потоки создаются, существуют scoped thread (потоки, принадлежащие скоупу).
Рассмотрим на примере:
fn main() {
let s = "Hello".to_string();
// создаём скоуп потоков
std::thread::scope(|scope| {
// порождаем поток внутри скоупа
scope.spawn(|| {
println!("{}", &s);
});
}); // здесь все потоки скоупа уже завершены
}Scoped потоки:
- могут обращаться к локальным переменным родительской функции непосредственно по ссылке, без
moveиArc - гарантированно завершаются в конце блока scope, внутри которого они созданы (так, словно перед выходом из скоупа для них вызывается
join)
Давайте перепишем наш пример для барьера, с использованием scoped потоков.
use std::sync::{Barrier, Mutex};
use std::thread;
const WORKERS_NUM: usize = 10;
fn main() {
let data = (0..100).collect::<Vec<_>>();
let mutex = Mutex::new(data);
let barrier = Barrier::new(WORKERS_NUM);
thread::scope(|s| {
// скоуп для запуска потоков
for _ in 0..WORKERS_NUM {
s.spawn(|| {
loop {
barrier.wait();
let Some(element) = mutex.lock().unwrap().pop() else {
break;
};
println!("Processing {element} by {:?}", thread::current().id());
}
});
}
});
}Как видите, код стал значительно проще, так как из него ушли Arc и код, ожидающий завершения потоков.
Атомики
Для примитивных типов данных в Rust есть атомарные обёртки, которые можно безопасно использовать в многопоточной среде.
| Примитивный тип | Атомик |
|---|---|
bool | std::sync::atomic::AtomicBool |
u8 | std::sync::atomic::AtomicU8 |
u16 | std::sync::atomic::AtomicU16 |
u32 | std::sync::atomic::AtomicU32 |
u64 | std::sync::atomic::AtomicU64 |
i8 | std::sync::atomic::AtomicI8 |
i16 | std::sync::atomic::AtomicI16 |
i32 | std::sync::atomic::AtomicI32 |
i64 | std::sync::atomic::AtomicI64 |
usize | std::sync::atomic::AtomicUsize |
isize | std::sync::atomic::AtomicIsize |
*mut T | std::sync::atomic::AtomicPtr<T> |
Все числовые атомик типы позволяют атомарно читать и записывать значение, а также атомарно выполнять арифметические и логические операции.
Например, сделаем на базе AtomicI32 счётчик, который будем инкрементировать из разных потоков.
use std::{
sync::atomic::{AtomicI32, Ordering},
thread,
};
fn main() {
let a = AtomicI32::new(0); // инициализируем атомик нулём
thread::scope(|s| {
for _ in 0..1000 {
s.spawn(|| {
for _ in 0..1000 {
a.fetch_add(1, Ordering::Relaxed); // инкрементируем
}
});
}
});
println!("{}", a.load(Ordering::Relaxed)); // 1000000
}Совершив 1000 инкрементов из 1000 потоков, мы ожидаемо получим значение счётчика, равное 100000.
Tip
Для сравнения, тот же счётчик с указателем вместо атомика
use std::thread; fn main() { let mut a = 0; let address = (&raw mut a).addr(); thread::scope(|s| { for _ in 0..1000 { s.spawn(|| { for _ in 0..1000 { unsafe { *(address as *mut i32) += 1; } } }); } }); println!("{}", a); // 862886 }
Метод fetch_add, реализующий сложение, в качестве аргумента, кроме слагаемого, также принимает некий Ordering. Этот аргумент отвечает за так называемый memory ordering, который определяет, какие гарантии мы получаем касательно порядка синхронизации операций с атомиками между потоками.
Дело в том, что компилятор может переставлять местами инструкции таким образом, что их порядок не будет соответствовать тому порядку, который они имеют в исходном коде. Это делается с целью оптимизации вычислений, и не влияет на логику программы. Если компилятор видит, что значение переменной y вычисляется на основе значения переменной x, то он проследит, чтобы значение x было вычислено до того, как начнётся вычисление y. Однако компилятор может отслеживать такие зависимости только в рамках вычислений в одном и том же потоке, но когда дело касается атомиков, то компилятор не в состоянии отследить, в каком порядке происходит взаимодействие между разными атомиками из разных потоков. Именно для решения этой проблемы и указывается параметр Ordering, который может принимать такие значения:
Relaxed— всё еще гарантирует консистентность одной и той же атомик-переменной при обращении к ней из разных потоков. Но ничего не обещает про относительный порядок операций между разными атомик переменными. Это значит, что два потока, работая с атомиками используяRelaxedордеринг, могут по-разному видеть операции на двух разных атомик-переменных. Например, если первый поток записывает значение в атомикa, и затем в атомикb, то второй поток может увидеть эти записи в противоположном порядке.
Note
Скорее всего, в бэкенд-приложениях вы будете использовать атомики только в качестве счётчиков для некой статистики, и всегда только с
Relaxedордерингом.
Release— используется для операций записи. При записи атомика сReleaseордерингом, все предшествующие операции (включая не атомики иRelaxedатомик записи), должны быть видимы другим потокам, которые читают этот атомик сAcquireордерингом.
Например, если мы записываем атомик-переменнуюa, а потом записываем атомикbс ордерингомRelease, то другой поток, который читает атомикbсAcquireордерингом, должен обязательно увидеть и изменения дляa, предшествующие записи в атомикb.Acquire— используется для операций чтения из атомика, запись в который была сделана с ордерингомRelease.AcqRel— используется для операций, которые имеют одновременно семантику чтения и записи, напримерfetch_add(сначала читает значение, потом вычисляет сложение, а потом делает запись при помощи compare and swap). При выполненииfetch_addс ордерингомAcqRel, чтение значения произойдёт сAcquireордерингом, а запись сRelease.SeqCst— используется и для чтения, и для записи. Это наивысшая гарантия синхронизации изменения происходящих перед записью атомика. Используйте этот вид ордеринга, когда у вас логика завязана на последовательность изменений атомиков. Однако имейте ввиду, что этот вид ордеринга имеет наихудшую производительность.
Кроме fetch_add, числовые атомики также поддерживают:
- вычитание —
fetch_sub - побитовое ИЛИ —
fetch_or - побитовое И —
fetch_and - побитовое И НЕ —
fetch_nand - побитовое исключающее ИЛИ —
fetch_xor
Также, атомики поддерживают Compare And Exchange операцию, которая используется в случаях, когда нужно считать значение атомика, далее вычислить новое значение, и после этого записать новое значение обратно в атомик. Простая комбинация методов load и save в таком сценарии не подойдёт, так как между вызовами load и save (во время вычисления нового значения), другой поток может произвести запись в этот же атомик, и получится, что текущий поток вычисляет новое значение, основываясь на уже устаревших данных.
Операция compare and exchange (по факту, это то же, что и compare and swap) представлена методом:
#![allow(unused)]
fn main() {
pub fn compare_exchange(
&self,
expected: тип_значения_атомика,
new: тип_значения_атомика,
success_ordering: Ordering,
failure_ordering: Ordering,
) -> Result<тип, тип>
}Этот метод принимает ожидаемое текущее значение атомика — expected и новое значение — new и записывает в атомик новое значение только в том случае, если ожидаемое текущее значение равно реальному текущему значению, содержащемуся в атомике.
Метод возвращает Ok(реальное текущее значение до записи), если запись была произведена, или Err(реальное текущее значение), если запись не была произведена.
Параметры memory ordering-а:
success_orderingуказывает memory ordering для успешной read-write-modify операции, которая происходит, если ожидаемое текущее значение атомика совпадёт с реальным текущим значением.failure_orderingуказывает memory ordering для load операции, которой будет считано реальное текущее значение атомика, если оно не совпадёт с ожидаемым.
Пример использования compare_exchange: перепишем нашу инкрементацию счётчика из тысячи потоков, с использованием compare_exchange.
use std::{
sync::atomic::{AtomicI32, Ordering},
thread,
};
fn main() {
let a = AtomicI32::new(0);
thread::scope(|s| {
for _ in 0..1000 {
s.spawn(|| {
for _ in 0..1000 {
let mut old_val = a.load(Ordering::Relaxed);
loop {
let new_val = old_val + 1;
let r = a.compare_exchange(
old_val,
new_val,
Ordering::Relaxed,
Ordering::Relaxed,
);
if let Err(actual_val) = r {
old_val = actual_val;
} else {
break;
}
}
}
});
}
});
println!("{:?}", a); // 1000000
}Для эксперимента можете попробовать заменить внутренний цикл на
#![allow(unused)]
fn main() {
for _ in 0..1000 {
let old_val = a.load(Ordering::Relaxed);
let new_val = old_val + 1;
a.store(new_val, Ordering::Relaxed);
}
}и посмотреть на результат.
Thread local storage
Thread-local storage — механизм, представляющий из себя локальное для потока хранилище.
Идея заключается в том, что в коде мы работаем с thread-local переменной так, словно она глобальная. Однако для каждого потока эта “глобальная” переменная имеет своё значение.
Thread-local переменная объявляется при помощи макроса thread_local:
#![allow(unused)]
fn main() {
thread_local! {
static ПЕРЕМЕННАЯ: Тип = значение;
}
}После этого можно работать с thread-local переменной так словно это это обычная глобальная переменная. При этом изменения переменной будут видны только в рамках того же потока.
Рассмотрим простой пример, в котором хорошо видно, что значение thread-local переменной у каждого потока своё:
use std::{cell::Cell, thread};
thread_local! {
pub static NUM: Cell<u32> = const { Cell::new(0) };
}
fn print_num() {
println!("{}", NUM.get());
}
fn main() {
let t1 = thread::spawn(|| {
NUM.set(1);
print_num();
});
let t2 = thread::spawn(|| {
NUM.set(2);
print_num();
});
let _ = t1.join();
let _ = t2.join();
}Программа напечатает:
1
2
Thread-local переменные часто используют в веб серверах. Например, в самом начале обработки запроса мы помещаем в thread-local информацию о сессии пользователя, сделавшего запрос. Дальше эта информация становится доступной во всей цепочке вызовов обработки запроса. Без thread-local нам бы пришлось пробрасывать объект сессии “сквозь” все вызовы функций.
Каналы
Для общения между потоками стандартная библиотека Rust предоставляет каналы.
По сути, канал является синхронизированной очередью: один поток добавляет элементы в конец очереди, а другой поток извлекает элементы из её начала.
Стандартная библиотека предоставляет канал mpsc (multiple producers, single consumer), который позволяет множеству потоков добавлять сообщения в канал, но только одному потоку — считывать сообщения.
Note
Если необходимо, чтобы множество потоков могли читать из канала, то библиотека crossbeam-channel предоставляет mpmc (multiple producers, multiple consumers) канал.
Также в стандартной библиотеке Rust есть свой канал mpmc, однако на данный момент (Rust 1.92) он доступен только в ночной сборке Rust.
Канал создаётся одной из двух функций:
- channel — создаёт канал неограниченного размера
- sync_channel — создаёт канал заданного размера. Если канал заполнен, то попытка добавить сообщение в канал приводит к блокировке пишущего потока до тех пор, пока читающий поток не извлечет из канала сообщение, тем самым освободив место.
И channel и sync_channel возвращают кортеж из двух элементов: Sender и Receiver.
#![allow(unused)]
fn main() {
pub fn channel<T>() -> (Sender<T>, Receiver<T>)
pub fn sync_channel<T>(bound: usize) -> (SyncSender<T>, Receiver<T>)
}Объект Sender используется для добавления сообщений в канал, а Receiver — для чтения из канала.
Рассмотрим простой пример: один поток отправляет числа в канал, а другой поток их оттуда достаёт и печатает на консоль.
use std::{sync::mpsc, thread};
// Обёртка для чисел, которые будем передавать в канал
enum Element {
Num(i32), // очередное число
Finish, // флаг завершения работы
}
fn main() {
let (producer, receiver) = mpsc::channel::<Element>();
let t1 = thread::spawn(move || {
for i in 0..5 {
let _ = producer.send(Element::Num(i));
}
});
let t2 = thread::spawn(move || {
while let Ok(msg) = receiver.recv() {
match msg {
Element::Num(i) => println!("{i}"),
Element::Finish => break,
}
}
});
let _ = t1.join();
let _ = t2.join();
}В примере выше мы использовали канал неограниченного размера. Теперь давайте посмотрим, как работает канал фиксированного размера.
Создадим канал вместительностью в 3 сообщения. Один поток будет отправлять сообщения в канал и печатать, сколько времени заняла отправка, а другой поток будет в цикле ждать 1 секунду, а потом извлекать очередное сообщение.
use std::{sync::mpsc, thread, time::{Duration, Instant}};
fn main() {
let (snd, rcv) = mpsc::sync_channel::<i32>(3);
let t1 = thread::spawn(move || {
for i in 0..5 {
let start = Instant::now();
let _ = snd.send(i);
println!("Took {} millis to send msg", start.elapsed().as_millis());
}
});
let _ = thread::spawn(move || {
loop {
thread::sleep(Duration::from_secs(1));
match rcv.recv() {
Ok(_) => (),
Err(_) => break,
}
}
});
let _ = t1.join();
}Программа печатает:
Took 0 millis to send msg
Took 0 millis to send msg
Took 0 millis to send msg
Took 1000 millis to send msg
Took 1000 millis to send msg
Так как вместительность канала — 3 сообщения, то первые 3 сообщения отправляются в канал мгновенно. Далее поток отправитель засыпает и ожидает, когда в канале появится место. А так как поток читатель делает паузу в 1 секунду между чтениями сообщения, то канал отправитель начинает ждать по 1 секунде, пока сообщение будет отправлено в канал.
Что почитать
В этой главе мы сделали беглый обзор многопоточности в Rust. Скорее всего, для написания бэкенд-приложений этого материала будет достаточно, однако если вы хотите углубиться в тему многопоточности, то обязательно обратите внимание на бесплатную книгу Rust Atomics and Locks за авторством Mara Bos.
Глобальные данные
Теперь, когда мы разобрались с многопоточностью и понимаем проблемы синхронизации доступа к данным, мы готовы рассмотреть работу с глобальными данными.
Как мы уже знаем, в Rust есть два вида глобальных данных: константы и статические данные.
Константы крайне просты в использовании, потому что они:
- доступны с самого первого момента работы программы (имеют
'staticлайфтайм) - неизменяемы, а значит никакие ссылочные ограничения на них не распространяются
Однако константы имеют существенные ограничения:
- значение константы должно быть вычислено на этапе компиляции, а значит константой не может быть тип данных, который использует кучу (например,
HashMap) - иногда необходимо менять значение глобальных данных во время работы программы, но константы этого не позволяют
Глобальные статические переменные
Если в глобальной переменной необходимо хранить данные, которые нельзя инициализировать на этапе компиляции, или необходимо, чтобы глобальная переменная была мутабельной, то придётся использовать глобальную статическую переменную.
Мы уже видели статические переменные внутри функций. Глобальные статические переменные отличаются лишь тем, что они доступны не только в пределах одной функции, а из всей программы. Всё остальное — одинаково.
Статическая глобальная переменная, как и локальная, объявляется при помощи ключевого слова static.
static VAR1: i32 = 1;
static mut VAR2: i32 = 2;Напомним, что:
- Имена статических переменных записываются заглавными буквами.
- Статические переменные могут быть как мутабельными, так и немутабельными.
- Тип переменной обязателен, даже если компилятор может однозначно вывести его из значения.
Чтение и запись в статическую мутабельную переменную считается потенциально опасной операцией, так как эта переменная может быть одновременно использована из разных потоков. Именно поэтому читать или изменять значение статической мутабельной переменной можно только внутри unsafe блока.
static mut VAR1: i32 = 0;
fn inc_var() {
unsafe {
VAR1 += 1;
}
}
fn get_var() -> i32 {
unsafe {
VAR1
}
}
fn main() {
println!("{}", get_var()); // 0
inc_var();
println!("{}", get_var()); // 1
}На этом этапе уже становится понятным, что использовать мутабельные статические переменные без некоего механизма синхронизации — плохая затея.
Синхронизация глобальных переменных
Из главы про многопоточность мы уже знаем, что разделяемую переменную можно синхронизировать при помощи мьютекса или RwLock. Это работает не только для локальных переменных, захватываемых замыканием, но и для глобальных.
Рассмотрим пример синхронизации доступа к глобальной статической переменной при помощи мьютекса.
use std::{sync::Mutex, thread, time::Duration};
static COUNTER: Mutex<u64> = Mutex::new(0);
fn main() {
thread::scope(|s| {
s.spawn(|| {
for i in 0..100 {
let mut guard = COUNTER.lock().unwrap();
let curr_val = *guard;
thread::sleep(Duration::from_millis(10));
*guard = curr_val + 1;
}
});
s.spawn(|| {
for i in 0..100 {
let mut guard = COUNTER.lock().unwrap();
let curr_val = *guard;
thread::sleep(Duration::from_millis(10));
*guard = curr_val + 1;
}
});
});
println!("{}", *COUNTER.lock().unwrap()); // 200
}Как видим, потоки работают с глобально объявленным мьютексом COUNTER точно так же, как если бы он был создан в теле функции main.
LazyLock
В примере выше мы синхронизировали доступ к глобальной переменной такого типа, который не использует кучу — i32. Однако если мы попытаемся таким же образом создать, например, глобальную хеш-таблицу, то получим ошибку компиляции:
use std::{collections::HashMap, sync::Mutex};
static m: Mutex<HashMap<String, i32>> = Mutex::new(HashMap::new());
fn main() {}ошибка:
error[E0015]: cannot call non-const associated function `HashMap::<String, i32>::new` in statics
--> src/main.rs:3:52
|
3 | static m: Mutex<HashMap<String, i32>> = Mutex::new(HashMap::new());
| ^^^^^^^^^^^^^^
|
= note: calls in statics are limited to constant functions, tuple structs and tuple variants
= note: consider wrapping this expression in `std::sync::LazyLock::new(|| ...)`
Сообщение от компилятора поясняет, что конструировать начальное значение статической переменной можно только при помощи константной функции, коей является Mutex::new, но не является HashMap::new.
Компилятор также любезно предлагает нам решить проблему путём использования LazyLock.
LazyLock — обёртка, которая позволяет отложить инициализацию значения до момента, когда значение будет затребовано впервые. То есть перенести фактическую инициализацию из времени компиляции во время исполнения.
Значение LazyLock создаётся константной функцией LazyLock::new, что позволяет использовать её для инициализации статической глобальной переменной.
pub const fn new(f: F) -> LazyLock<T, F>В качестве аргумента она принимает замыкание, которое должно сконструировать нужный нам объект. Это замыкание будет вызвано при первом обращении к значению LazyLock.
use std::{ collections::HashMap, sync::{LazyLock, Mutex} };
// Создаём хеш-таблицу, синхронизированную при помощи мьютекса,
// и инициализированную при помощи LazyLock
static M: LazyLock<Mutex<HashMap<String, i32>>> = LazyLock::new(
|| Mutex::new(HashMap::new())
);
fn main() {
{ // добавляем элемент в хеш таблицу
let mut guard = M.lock().unwrap();
guard.insert("one".to_string(), 1);
}
{ // считываем значения хеш-таблицы
let guard = M.lock().unwrap();
println!("{:?}", *guard); // {"one": 1}
}
}LazyLock реализует трэйт Deref, что позволяет работать с ним прозрачно: словно мы работаем с его содержимым напрямую.
Note
Если с непривычки трёхэтажный генерик
LazyLock<Mutex<HashMap<String, i32>>>выглядит для вас устрашающе, не переживайте: вы быстро начнёте ценить явность таких объявлений.
Для синхронизации LazyLock используется double-checked locking, что позволяет безопасно использовать его в многопоточной среде.
OnceLock
LazyLock решает проблему инициализации глобальной переменной “сложного” типа, однако он не подходит для случаев, если глобальная переменная может быть инициализирована из нескольких разных мест в коде. Например, в зависимости от каких-то дополнительных условий должны вызываться разные функции, которые инициализируют глобальную переменную по-разному. В такой ситуации нам поможет OnceLock.
OnceLock служит той же цели, что и LazyLock, однако инициализирует своё значение не при первом обращении, а путём явного вызова метода set. Метод set устанавливает значение OnceLock только если это самый первый вызов set. В противном случае вызов set игнорируется.
use std::sync::{Mutex, OnceLock};
static O: OnceLock<Mutex<String>> = OnceLock::new();
fn main() {
{ // Инициализируем значение OnceLock
let r = O.set(Mutex::new("1".to_string()));
if let Err(e) = r {
eprintln!("Cannot init with: {e:?}");
}
}
{ // Попытка повторной инициализации OnceLock
let r = O.set(Mutex::new("2".to_string()));
if let Err(e) = r {
eprintln!("Cannot init with: {e:?}");
}
}
{
let mutex = O.get().unwrap();
let guard = mutex.lock().unwrap();
println!("OnceLock = {:?}", *guard);
}
}Эта программа напечатает:
Cannot init with: Mutex { data: "2", poisoned: false, .. }
OnceLock = "1"
Важно заметить, что вызов get на неинициализированном объекте OnceLock приведёт к панике.
Также для OnceLock есть метод get_or_init, который принимает замыкание для генерации значения по умолчанию. Если OnceLock был проинициализирован, то get_or_init вернёт ссылку на хранящееся в нём значение, иначе использует замыкание для инициализации, а затем вернёт ссылку на только что созданное значение.
use std::sync::{Mutex, OnceLock};
static O: OnceLock<Mutex<String>> = OnceLock::new();
fn main() {
{
let mutex = O.get_or_init(|| Mutex::new("default".to_string()));
let guard = mutex.lock().unwrap();
println!("OnceLock = {:?}", *guard);
}
}Пример хранения сессий пользователей
Теперь давайте рассмотрим пример, который часто возникает при написании бекенд приложений: хранение сессий пользователей.
Допустим, данные пользователя будут представлены некой структурой UserSession (конкретная реализация для нас не важна), и каждая сессия будет идентифицирована уникальным строковым ключом, например UUID.
В качестве основы для такого хранилища сессий удобно взять HashMap<String, UserSession>. Например, эта хеш-таблица может принадлежать некому объекту синглтону (например, структуре SessionManager), или быть глобальной статической переменной. Для большего раскрытия темы давайте использовать статическую переменную.
Мы уже знаем, что нам потребуется синхронизация доступа к этой хеш-таблице. Новые сессии создаются гораздо реже, чем читаются существующие, поэтому в нашем случае RwLock будет эффективнее, чем Mutex. Также мы знаем, что нам понадобится LazyLock.
static SESSIONS: LazyLock<RwLock<HashMap<String, UserSession>>> =
LazyLock::new(|| RwLock::new(HashMap::new()));Бекенд приложения могут одновременно обрабатывать тысячи запросов от пользователей, и при обработке каждого запроса данные сессии могут требоваться многократно, поэтому такое хранилище сессий может стать “узким местом”. Надо сделать так, чтобы в самом начале обработки запроса обработчик получал объект сессии пользователя и дальше работал с ним, не захватывая (пусть и на чтение) весь RwLock. Мы можем достичь этого путём заворачивания объекта сессии в Arc.
static SESSIONS: LazyLock<RwLock<HashMap<String, Arc<UserSession>>>> =
LazyLock::new(|| RwLock::new(HashMap::new()));Теперь обработчик может получить умный указатель на нужный ему объект сессии и работать с ним.
fn serve_request(r: Request) -> Response {
let session: Arc<UserSession> = {
// Захватываем хеш-таблицу для чтения
let hash_table = SESSIONS.read().unwrap();
if let Some(session_ref) = hash_table.get(r.get_session_id()) {
session_ref.clone(); // клонируем Arc
} else {
// Сессия с таким ID не найдена в хеш-таблице
return Response::error_301();
}
};
// Здесь уже спокойно работаем с сессией не блокируя RwLock
Response::ok_200()
}Теперь мы захватываем RwLock на небольшой промежуток времени, чтобы достать объект сессии из хеш-таблицы, после чего сразу отпускаем его. Однако у нас появилась другая проблема: Arc не является синхронизированным, поэтому не позволяет менять своё содержимое, а мы хотим, чтобы обработчик запроса имел возможность менять соответствующий ему объект сессии.
Это ограничение со стороны Arc более чем справедливо: теоретически мы одновременно можем обрабатывать несколько запросов от одного и того же пользователя, и мы не хотим, чтобы эти обработчики повредили данные в сессии из-за несинхронизированного доступа.
К счастью, мы уже знаем решение этой проблемы: нужно поместить Mutex или RwLock внутрь Arc. Допустим, что обработчикам запросов лучше иметь эксклюзивный доступ к данным сессии, поэтому будем использовать Mutex.
static SESSIONS: LazyLock<RwLock<HashMap<String, Arc<Mutex<UserSession>>>>> =
LazyLock::new(|| RwLock::new(HashMap::new()));Теперь наш обработчик запроса от пользователя может иметь вид:
fn serve_request(r: Request) -> Response {
let session_mutex: Arc<Mutex<UserSession>> = {
let hash_table = SESSIONS.read().unwrap();
if let Some(session_ref) = hash_table.get(r.get_session_id()) {
session_ref.clone();
} else {
return Response::error_301();
}
};
// Извлекаем некое значение из сессии
let mut some_value = {
let guard = session_mutex.lock().unwrap();
(*guard).some_field.clone();
};
// Какие-то вычисления с участием some_value
{
// обновляем данные сессии
let guard = session_mutex.lock().unwrap();
// Тут хорошо бы проверить, изменилось ли поле some_field
// другим параллельным обработчиком, который возможно существует
(*guard).some_field = some_value;
}
Response::ok_200()
}Разумеется, мы используем unwrap на объектах RwLock и Mutex исключительно для простоты примера. В реальном приложении необходимо проверять возможную ошибку.
Обработка ошибок
В главе про тип Result мы познакомились с основами обработки ошибок. В этой главе мы рассмотрим, как ошибки принято обрабатывать в бекенд приложениях.
thiserror
Давайте представим, что мы разрабатываем некий сервис, который отвечает за резервирование товаров. Для начала сервис будет содержать только одну функцию, которая принимает два параметра: ID товара для резервирования и желаемое количество экземпляров.
Очевидно, что в такой функциональности могут возникнуть минимум две ошибки:
- попытка резервирования неизвестного товара
- попытка зарезервировать больше экземпляров, чем имеется в наличии
Мы можем написать код этого сервиса следующим образом:
/// Тип объект успешно созданного резерва
struct Reservation {
reservation_id: u64,
product_id: u64,
quantity: u64,
}
trait ReservationService {
/// Резервирует указанный товар в указанном количестве
/// * ID товара
/// * количество экземпляров
fn reserve(&self, id: u64, quantity: u64) -> Result<Reservation, ReserveError>;
}
enum ReserveError {
NoSuchProduct { id: u64 },
NotEnough { asked: u64, available: u64 },
}Также из секции про трэйт Error мы знаем, что для типов, представляющих ошибку, рекомендуется реализовать трэйт std::error::Error, поэтому реализуем его для нашего типа ошибки — ReserveError:
#[derive(Debug)]
enum ReserveError {
NoSuchProduct { id: u64 },
NotEnough { asked: u64, available: u64 },
}
impl std::fmt::Display for ReserveError {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
use ReserveError::*;
match self {
NoSuchProduct { id } =>
write!(f, "No product with ID {id}"),
NotEnough {asked, available} =>
write!(f, "Asked {asked}, but available {available}"),
}
}
}
impl std::error::Error for ReserveError { }Нетрудно заметить, что реализация трэйта Error является громоздкой, и содержит в себе шаблонный код, который был бы одинаковым и в реализациях Error для других типов. К счастью, существует сторонняя библиотека thiserror, которая сильно упрощает создание типов ошибок.
Вот как выглядит эквивалентное определение нашего типа ReserveError при помощи thiserror:
use thiserror::Error;
#[derive(Debug, Error)]
enum ReserveError {
#[error("No product with ID {id}")]
NoSuchProduct { id: u64 },
#[error("Asked {asked}, but available {available}")]
NoEnoughQuantity { asked: u64, available: u64 },
}Библиотека thiserror содержит в себе процедурный макрос, который вызывается для перечислений и структур, аннотированных с #[derive(thiserror::Error)]. Этот макрос генерирует реализацию std::fmt::Display и std::error::Error, фактически делая то, что до этого мы сделали вручную.
Чтобы лучше понять, как это работает в целом, давайте напишем небольшую программу, использующую нашу функциональность по резервированию товаров.
Создайте новый проект:
cargo new test_rust
Добавьте thiserror в Cargo.toml:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
thiserror = "1"
Теперь src/main.rs. Напишем реализацию хранилища, из которого мы будем резервировать товары. Для простоты будем хранить товары в хеш-таблице.
use std::{
collections::HashMap,
sync::{Mutex, atomic::{AtomicU64, Ordering}},
};
#[derive(Debug)]
struct Reservation {
reservation_id: u64,
product_id: u64,
quantity: u64,
}
trait ReservationService {
fn reserve(&self, id: u64, quantity: u64) -> Result<Reservation, ReserveError>;
}
#[derive(Debug, thiserror::Error)]
enum ReserveError {
#[error("No product with ID {id}")]
NoSuchProduct { id: u64 },
#[error("Asked {asked}, but available {available}")]
NotEnough { asked: u64, available: u64 },
}
// Примитивная реализация склада в виде хеш-таблицы: ID товара->количество
struct ReservationImpl {
storage: Mutex<HashMap<u64, u64>>,
last_id: AtomicU64,
}
impl ReservationService for ReservationImpl {
fn reserve(&self, id: u64, quantity: u64) -> Result<Reservation, ReserveError> {
let mut guard = self.storage.lock().unwrap();
if let Some(stock) = guard.get_mut(&id) {
if *stock < quantity {
Err(ReserveError::NotEnough {
asked: quantity,
available: *stock,
})
} else {
*stock -= quantity;
Ok(Reservation {
reservation_id: self.last_id.fetch_add(1, Ordering::Relaxed),
product_id: id,
quantity,
})
}
} else {
Err(ReserveError::NoSuchProduct { id })
}
}
}
fn main() {
let mut products = HashMap::new();
products.insert(111, 50); // Товар 111 в количестве 50 экземпляров
let reservation_service = ReservationImpl {
storage: Mutex::new(products),
last_id: AtomicU64::new(0),
};
println!("{:?}", reservation_service.reserve(112, 1));
// Err(NoSuchProduct { id: 112 })
println!("{:?}", reservation_service.reserve(111, 51));
// Err(NoEnoughQuantity { asked: 51, available: 50 })
println!("{:?}", reservation_service.reserve(111, 10));
// Ok(Reservation { reservation_id: 1, product_id: 111, quantity: 10 })
}Переоборачивание ошибок
Давайте теперь расширим наше приложение: добавим еще функциональность для планирования адресной доставки и функциональность покупки, которая будет объединять в себе резервирование и доставку.
Предполагается такая логика.

API будет представлен тремя сервисами, каждый из которых состоит из:
- трэйта, описывающего интерфейс сервиса
- структуры для представления результата успешного вызова сервиса
- ошибки для представления проблемы в случае неуспешного вызова
Резервирование:
struct Reservation {
reservation_id: u64,
product_id: u64,
quantity: u64,
}
#[derive(Debug, thiserror::Error)]
enum ReserveError {
#[error("No product with ID {id}")]
NoSuchProduct { id: u64 },
#[error("Asked {asked}, but available {available}")]
NotEnough { asked: u64, available: u64 },
}
trait ReservationService {
fn reserve(
&self, id: u64, quantity: u64
) -> Result<Reservation, ReserveError>;
}Доставка:
struct Shipment {
shipment_id: u64,
address: String,
reservation_id: u64,
}
#[derive(Debug, thiserror::Error)]
enum ShipmentError {
#[error("Invalid address: {address}")]
InvalidAddress { address: String },
}
trait ShipmentService {
fn schedule_shipment(
&self, reservation: &Reservation, address: &str
) -> Result<Shipment, ShipmentError>;
}Покупка (резервирование + доставка):
struct Purchase {
purchase_id: u64,
reservation_id: u64,
shipment_id: u64,
}
#[derive(Debug, Error)]
enum PurchaseError {
#[error("Nested servation error: (0)")]
ReservationFailed(#[from] ReserveError)
#[error("Nested shipping error: (0)")]
ShippingFailed(#[from] ShipmentError)
}
trait PurchaseService {
fn purchase(
&self, id: u64, quantity: u64, addr: &str
) -> Result<Purchase, PurchaseError>;
}Обратите внимание, что PurchaseError просто оборачивает ошибки от низлежащих сервисов при помощи аннотации #[from]. Эта аннотация говорит thiserror, что нужно сгенерировать соответствующую реализацию трэйта From, с которым мы познакомились в главе про основные трэйты.
Например, для примера выше будут сгенерированы:
impl From<ReservationError> for PurchaseError { ... }
impl From<ShipmentError> for PurchaseError { ... }Таким образом, “оборачивая” одну ошибку в другую, мы одновременно и сохраняем информацию о причинах возникновения проблемы, и имеем ошибки, специфичные для текущего API.
Давайте расширим наш пример так, чтобы продемонстрировать, как ошибка, возникшая в низлежащих ReservationService и ShipmentService, возвращается из метода PurchaseService::purchase обёрнутой в PurchaseError.
Код для src/main.rs:
use thiserror;
use std::{
collections::HashMap,
sync::{Arc, Mutex, atomic::{AtomicU64, Ordering}},
};
// ----- Код для функциональности резервирования
#[derive(Debug)]
struct Reservation {
id: u64,
product_id: u64,
quantity: u64,
}
#[derive(Debug, thiserror::Error)]
enum ReserveError {
#[error("No product with ID {id}")]
NoSuchProduct { id: u64 },
#[error("Asked {asked}, but available {available}")]
NotEnough { asked: u64, available: u64 },
}
trait ReservationService {
fn reserve(&self, id: u64, quantity: u64) -> Result<Reservation, ReserveError>;
}
struct ReservationImpl {
storage: Mutex<HashMap<u64, u64>>,
last_id: AtomicU64,
}
impl ReservationImpl {
fn new(storage: HashMap<u64, u64>) -> ReservationImpl {
ReservationImpl {
storage: Mutex::new(storage),
last_id: AtomicU64::new(0),
}
}
}
impl ReservationService for ReservationImpl {
fn reserve(&self, id: u64, quantity: u64) -> Result<Reservation, ReserveError> {
let mut guard = self.storage.lock().unwrap();
if let Some(stock) = guard.get_mut(&id) {
if *stock < quantity {
Err(ReserveError::NotEnough {
asked: quantity,
available: *stock,
})
} else {
*stock -= quantity;
Ok(Reservation {
id: self.last_id.fetch_add(1, Ordering::Relaxed),
product_id: id,
quantity,
})
}
} else {
Err(ReserveError::NoSuchProduct { id })
}
}
}
// ----- Код для функциональности доставки
struct Shipment {
id: u64,
address: String,
reservation_id: u64,
}
#[derive(Debug, thiserror::Error)]
enum ShipmentError {
#[error("Invalid address: {address}")]
InvalidAddress { address: String },
}
trait ShipmentService {
fn schedule_shipment(
&self,
reservation: &Reservation,
address: &str,
) -> Result<Shipment, ShipmentError>;
}
#[derive(Debug)]
struct ShipmentImpl {
last_id: AtomicU64,
}
impl ShipmentImpl {
fn new() -> ShipmentImpl {
ShipmentImpl {
last_id: AtomicU64::new(0),
}
}
}
impl ShipmentService for ShipmentImpl {
fn schedule_shipment(
&self, reservation: &Reservation, address: &str,
) -> Result<Shipment, ShipmentError> {
if address.split(" ").count() < 2 {
Err(ShipmentError::InvalidAddress { address: address.to_string() })
} else {
Ok(Shipment {
id: self.last_id.fetch_add(1, Ordering::Relaxed),
address: address.to_string(),
reservation_id: reservation.id,
})
}
}
}
// ----- Код для функциональности покупки
#[derive(Debug)]
struct Purchase {
id: u64,
reservation_id: u64,
shipment_id: u64,
}
#[derive(Debug, thiserror::Error)]
enum PurchaseError {
#[error("Nested servation error: (0)")]
ReservationFailed(#[from] ReserveError),
#[error("Nested shipping error: (0)")]
ShippingFailed(#[from] ShipmentError),
}
trait PurchaseService {
fn purchase(
&self, id: u64, quantity: u64, addr: &str
) -> Result<Purchase, PurchaseError>;
}
struct PurchaseImpl {
reservation_service: Arc<dyn ReservationService>,
shipment_service: Arc<dyn ShipmentService>,
last_id: AtomicU64,
}
impl PurchaseImpl {
fn new(
reservation_service: Arc<dyn ReservationService>,
shipment_service: Arc<dyn ShipmentService>,
) -> PurchaseImpl {
PurchaseImpl {
reservation_service,
shipment_service,
last_id: AtomicU64::new(0),
}
}
}
impl PurchaseService for PurchaseImpl {
fn purchase(
&self, id: u64, quantity: u64, addr: &str
) -> Result<Purchase, PurchaseError> {
let reservation = self.reservation_service.reserve(id, quantity)?;
let shipment = self
.shipment_service
.schedule_shipment(&reservation, addr)?;
Ok(Purchase {
id: self.last_id.fetch_add(1, Ordering::Relaxed),
reservation_id: reservation.id,
shipment_id: shipment.id,
})
}
}
// Подготовка заглушек экземпляров сервисов
fn initialize_purchase_service() -> Arc<dyn PurchaseService> {
let mut products = HashMap::new();
products.insert(111, 50); // Товар 111 в количестве 50 экземпляров
let reservation_service = ReservationImpl::new(products);
let shipment_service = ShipmentImpl::new();
let purchase_service =
PurchaseImpl::new(Arc::new(reservation_service), Arc::new(shipment_service));
Arc::new(purchase_service)
}
fn main() {
let purchase_service = initialize_purchase_service();
println!("{:?}", purchase_service.purchase(112, 1, "addr 1"));
// Err(ReservationFailed(NoSuchProduct { id: 112 }))
println!("{:?}", purchase_service.purchase(111, 51, "addr 1"));
// Err(ReservationFailed(NotEnough { asked: 51, available: 50 }))
println!("{:?}", purchase_service.purchase(111, 10, "invalid"));
// Err(ShippingFailed(InvalidAddress { address: "invalid" }))
println!("{:?}", purchase_service.purchase(111, 10, "addr 1"));
// Ok(Purchase { id: 0, reservation_id: 1, shipment_id: 0 })
}Box<dyn Error>
Существует ряд ситуаций, когда отсутствует возможность как-то корректно обработать ошибку. Например, если в бэкенд-приложении в процессе обработки клиентского запроса возникает ошибка, то довольно часто единственное, что можно сделать — это залогировать ошибку и ответить клиенту 500-м HTTP кодом.
В этом случае переоборачивание ошибок может оказаться бесполезной тратой усилий или даже, наоборот, усложнить код. Поэтому вместо переоборачивания ошибок можно просто “пробрасывать их наверх” в виде “обезличенного” трэйт-объекта Box<dyn Error>.
Рассмотрим пример: мы напишем две функции, которые возвращают два разных типа ошибок, и функцию, которая внутри себя вызывает эти две функции и пробрасывает полученные от них ошибки в виде Box<dyn std::error::Error>>.
#[derive(Debug, thiserror::Error)]
#[error("Error A")]
struct ErrA;
#[derive(Debug, thiserror::Error)]
#[error("Error B")]
struct ErrB;
fn fail_a() -> Result<(), ErrA> {
Err(ErrA)
}
fn fail_b() -> Result<(), ErrB> {
Err(ErrB)
}
fn fail_something(is_a: bool) -> Result<(), Box<dyn std::error::Error>> {
if is_a {
// Оператор ? перепакует ошибку в ожидаемый тип - Box<dyn std::error::Error>>)
// как если бы мы явно вызвали:
// fail_a().map_err(|e| Box::new(e) as Box<dyn std::error::Error>)
let r = fail_a()?;
Ok(r)
} else {
let r = fail_b()?;
Ok(r)
}
}
fn main() {
if let Err(e) = fail_something(true) {
println!("Underlying error: {}", e.to_string());
}
if let Err(e) = fail_something(false) {
println!("Underlying error: {}", e.to_string());
}
}Программы выводит:
Underlying error: Error A
Underlying error: Error B
Итак, теперь мы умеем возвращать любую ошибку, не заботясь о её конкретном типе. Но иногда есть необходимость отдельно обработать какой-то один вид ошибок. Это можно сделать при помощи метода downcast_ref, который определён для трэйт-объекта dyn Error.
#[derive(Debug, thiserror::Error)]
#[error("Error A")]
struct ErrA;
#[derive(Debug, thiserror::Error)]
#[error("Error B")]
struct ErrB;
fn fail_a() -> Result<(), ErrA> {
Err(ErrA)
}
fn fail_b() -> Result<(), ErrB> {
Err(ErrB)
}
fn fail_something(is_a: bool) -> Result<(), Box<dyn std::error::Error>> {
if is_a {
// Оператор ? перепакует ошибку в ожидаемый тип - Box<dyn std::error::Error>>)
// как если бы мы явно вызвали:
// fail_a().map_err(|e| Box::new(e) as Box<dyn std::error::Error>)
let r = fail_a()?;
Ok(r)
} else {
let r = fail_b()?;
Ok(r)
}
}
fn main() {
if let Err(e) = fail_something(true) {
if let Some(err_a) = e.downcast_ref::<ErrA>() {
println!("Handle ErrA separately: {err_a}")
} else {
println!("Underlying error: {}", e.to_string());
}
}
}Anyhow
Если вы не в восторге от ручной работы с Box<dyn std::error::Error>, то экосистема Rust предлагает библиотеку anyhow, которая упрощает работу с “обезличенными” ошибками.
anyhow предлагает свой тип “обезличенной” ошибки anyhow::Error и свой тип результата anyhow::Result<T>, который является псевдонимом для std::result::Result<T, anyhow::Error>.
Для начала рассмотрим простейшую программу, которая демонстрирует, как anyhow встраивается в процесс обработки ошибок.
#[derive(Debug, thiserror::Error)]
#[error("My custom error")]
struct MyError;
fn fail_with_specific_error() -> Result<(), MyError> { // вернёт специфичную ошибку
Err(MyError)
}
fn call_failable() -> anyhow::Result<()> { // вернёт обезличенную anyhow::Error
let r = fail_with_specific_error()?;
Ok(r)
}
fn main() {
match call_failable() {
Ok(_) => println!("It was fine"),
Err(e) => {
if let Some(_my_err) = e.downcast_ref::<MyError>() {
eprintln!("It failed MyError")
} else {
eprintln!("It failed with: {}", e.root_cause())
}
}
}
}Как видите, в теле функции call_failable конкретная ошибка перепаковывается в anyhow::Error, подобно тому, как мы уже перепаковывали конкретную ошибку в Box<dyn Error> в предыдущей секции.
Так какие же преимущества предлагает anyhow?
backtrace
anyhow::Error не просто оборачивает ошибку, но также может добавить бэктрэйс, который позволит легко идентифицировать точное место возникновения ошибки.
По умолчанию бэктрэйсы не создаются (так как это ресурсозатратный процесс) и чтобы их включить, необходимо перед запуском программы выставить переменную окружения RUST_LIB_BACKTRACE=1.
Давайте перепишем предыдущий пример так, чтобы в нём выводился бэктрэйс:
#[derive(Debug, thiserror::Error)]
#[error("My custom error")]
struct MyError;
fn fail_with_specific_error() -> Result<(), MyError> {
Err(MyError)
}
fn call_failable() -> anyhow::Result<()> {
let r = fail_with_specific_error()?;
Ok(r)
}
fn main() {
match call_failable() {
Ok(_) => println!("It was fine"),
Err(e) => {
eprintln!("It failed with: {}", e.root_cause());
eprintln!("Backtrace:\n{}", e.backtrace());
}
}
}Перед запуском выставляем переменную окружения (в Windows cmd это делается командой set RUST_LIB_BACKTRACE=1):
$ export RUST_LIB_BACKTRACE=1
$ cargo run
It failed with: My custom error
Backtrace:
0: anyhow::error::<impl core::convert::From<E> for anyhow::Error>::from
at /home/stas/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/anyhow-1.0.100/src/backtrace.rs:27:14
1: <core::result::Result<T,F> as core::ops::try_trait::FromResidual<core::result::Result<core::convert::Infallible,E>>>::from_residual
at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/result.rs:2177:27
2: test_rust::call_failable
at ./src/main.rs:10:13
3: test_rust::main
at ./src/main.rs:15:11
4: core::ops::function::FnOnce::call_once
at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
5: std::sys::backtrace::__rust_begin_short_backtrace
at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/sys/backtrace.rs:158:18
6: std::rt::lang_start::{{closure}}
at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/rt.rs:206:18
7: core::ops::function::impls::<impl core::ops::function::FnOnce<A> for &F>::call_once
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/core/src/ops/function.rs:287:21
8: std::panicking::catch_unwind::do_call
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/panicking.rs:590:40
9: std::panicking::catch_unwind
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/panicking.rs:553:19
10: std::panic::catch_unwind
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/panic.rs:359:14
11: std::rt::lang_start_internal::{{closure}}
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/rt.rs:175:24
12: std::panicking::catch_unwind::do_call
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/panicking.rs:590:40
13: std::panicking::catch_unwind
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/panicking.rs:553:19
14: std::panic::catch_unwind
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/panic.rs:359:14
15: std::rt::lang_start_internal
at /rustc/ed61e7d7e242494fb7057f2657300d9e77bb4fcb/library/std/src/rt.rs:171:5
16: std::rt::lang_start
at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/rt.rs:205:5
17: main
18: __libc_start_call_main
at ./csu/../sysdeps/nptl/libc_start_call_main.h:58:16
19: __libc_start_main_impl
at ./csu/../csu/libc-start.c:360:3
20: _start
Во втором элементе цепочки бэктрэйса видно, что конкретная ошибка была перепакована в anyhow::Error в строке ./src/main.rs:10:13.
context
Иногда текстовое описание оригинальной ошибки является малоинформативным. anyhow позволяет добавить к ошибке дополнительное текстовое описание — контекст (context). Потом этот контекст может будет получить просто вызовом to_string() на объекте ошибки anyhow::Error.
Чтобы добавить к ошибке контекст, надо использовать метод .context() на результате (объекте Result).
fn my_func() -> anyhow::Result<Тип> {
let result = func_that_can_fail()
.context("информативное описание")?;
Ok(result)
}Рассмотрим пример: напишем программу, которая пытается считать несуществующий файл, и используем контекст для указания информации о том, какой файл не удалось считать.
use anyhow::Context;
fn read_non_existing_file() -> anyhow::Result<String> {
let text = std::fs::read_to_string("non_existing_file.txt")
.context("Cannot read non_existing_file.txt")?;
Ok(text)
}
fn main() {
match read_non_existing_file() {
Ok(text) => println!("File content: {text}"),
Err(e) => {
eprintln!("Failed with error: {}", e.root_cause());
eprintln!("Error context: {}", e.to_string());
}
}
}Запускаем:
$ cargo run
Failed with error: No such file or directory (os error 2)
Error context: Cannot read non_existing_file.txt
Как видите, если бы мы не использовали контекст, то получили бы малоинформативное описание ошибки “No such file or directory (os error 2)”. Однако при помощи контекста мы смогли указать, какой именно файл отсутствует.
Общие рекомендации по работе с ошибками
- Когда вы пишете библиотеку, то рекомендуется использовать конкретные и детальные типы ошибок. Для облегчения создания типов ошибок рекомендуется использовать thiserror.
- При написании конечного приложения в участках, где нет возможности должным образом обработать каждый тип ошибки отдельно, используйте anyhow, так как он сильно упрощает работу с ошибками.
Сериализация
serde
В языке Rust нет никаких стандартных механизмов для сериализации и десериализации данных, однако уже давно стандартом де-факто для сериализации стала библиотека serde.
serde не содержит функциональности для сериализации в какие-либо форматы, например JSON или XML, но предоставляет трэйты и процедурные макросы, которые позволяют автоматически сгенерировать для пользовательских типов набор специальных методов. Эти методы выдают метаинформацию о типе, а также позволяют читать поля и записывать в них значения. Уже на основе этих методов другие библиотеки, работающие с конкретными форматами (JSON, XML, YAML), производят сериализацию и десериализацию.
Крэйт serde предоставляет два основных трэйта: Serialize и Deserialize. Первый необходим для сериализации, второй — для десериализации.

(крэйт serde_json использует описание типа, предоставляемое реализацией трэйта Serialize, чтобы сериализовать объект типа МойТип в JSON)
Допустим, у нас есть некий тип Employee, который мы хотели бы иметь возможность сериализовать в различные форматы.
struct Employee {
id: u64,
name: String,
}Для начала добавим в Cargo.toml зависимость serde.
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
serde = { version = "1", features = ["derive"] }
Далее мы должны аннотировать нашу структуру трэйтами Serialize и Deserialize.
use serde::{Serialize, Deserialize};
#[derive(Serialize, Deserialize)]
struct Employee {
id: u64,
name: String,
}Теперь для структуры Employee будут сгенерированы реализации Serialize и Deserialize, которые позволят использовать её библиотекам сериализации в конкретные форматы.
Tip
Что конкретно генерирует serde?
Чтобы увидеть код реализаций
DeserializeиSerializeдля нашей структурыEmployee, создадим простую программу, состоящую из одного лишь объявления структуры.use serde::{Deserialize, Serialize}; #[derive(Serialize, Deserialize)] struct Employee { id: u64, name: String, } fn main() {}Далее выполним команду
cargo expand, которая напечатает на консоль содержимоеmain.rsпосле того как все макросы обработаны.(если утилита expand не установлена, сначала выполните
cargo install expand)#![feature(prelude_import)] #[macro_use] extern crate std; #[prelude_import] use std::prelude::rust_2024::*; use serde::{Deserialize, Serialize}; struct Employee { id: u64, name: String, } #[doc(hidden)] #[allow( non_upper_case_globals, unused_attributes, unused_qualifications, clippy::absolute_paths, )] const _: () = { #[allow(unused_extern_crates, clippy::useless_attribute)] extern crate serde as _serde; #[automatically_derived] impl _serde::Serialize for Employee { fn serialize<__S>( &self, __serializer: __S, ) -> _serde::__private228::Result<__S::Ok, __S::Error> where __S: _serde::Serializer, { let mut __serde_state = _serde::Serializer::serialize_struct( __serializer, "Employee", false as usize + 1 + 1, )?; _serde::ser::SerializeStruct::serialize_field( &mut __serde_state, "id", &self.id, )?; _serde::ser::SerializeStruct::serialize_field( &mut __serde_state, "name", &self.name, )?; _serde::ser::SerializeStruct::end(__serde_state) } } }; #[doc(hidden)] #[allow( non_upper_case_globals, unused_attributes, unused_qualifications, clippy::absolute_paths, )] const _: () = { #[allow(unused_extern_crates, clippy::useless_attribute)] extern crate serde as _serde; #[automatically_derived] impl<'de> _serde::Deserialize<'de> for Employee { fn deserialize<__D>( __deserializer: __D, ) -> _serde::__private228::Result<Self, __D::Error> where __D: _serde::Deserializer<'de>, { #[allow(non_camel_case_types)] #[doc(hidden)] enum __Field { __field0, __field1, __ignore, } #[doc(hidden)] struct __FieldVisitor; #[automatically_derived] impl<'de> _serde::de::Visitor<'de> for __FieldVisitor { type Value = __Field; fn expecting( &self, __formatter: &mut _serde::__private228::Formatter, ) -> _serde::__private228::fmt::Result { _serde::__private228::Formatter::write_str( __formatter, "field identifier", ) } fn visit_u64<__E>( self, __value: u64, ) -> _serde::__private228::Result<Self::Value, __E> where __E: _serde::de::Error, { match __value { 0u64 => _serde::__private228::Ok(__Field::__field0), 1u64 => _serde::__private228::Ok(__Field::__field1), _ => _serde::__private228::Ok(__Field::__ignore), } } fn visit_str<__E>( self, __value: &str, ) -> _serde::__private228::Result<Self::Value, __E> where __E: _serde::de::Error, { match __value { "id" => _serde::__private228::Ok(__Field::__field0), "name" => _serde::__private228::Ok(__Field::__field1), _ => _serde::__private228::Ok(__Field::__ignore), } } fn visit_bytes<__E>( self, __value: &[u8], ) -> _serde::__private228::Result<Self::Value, __E> where __E: _serde::de::Error, { match __value { b"id" => _serde::__private228::Ok(__Field::__field0), b"name" => _serde::__private228::Ok(__Field::__field1), _ => _serde::__private228::Ok(__Field::__ignore), } } } #[automatically_derived] impl<'de> _serde::Deserialize<'de> for __Field { #[inline] fn deserialize<__D>( __deserializer: __D, ) -> _serde::__private228::Result<Self, __D::Error> where __D: _serde::Deserializer<'de>, { _serde::Deserializer::deserialize_identifier( __deserializer, __FieldVisitor, ) } } #[doc(hidden)] struct __Visitor<'de> { marker: _serde::__private228::PhantomData<Employee>, lifetime: _serde::__private228::PhantomData<&'de ()>, } #[automatically_derived] impl<'de> _serde::de::Visitor<'de> for __Visitor<'de> { type Value = Employee; fn expecting( &self, __formatter: &mut _serde::__private228::Formatter, ) -> _serde::__private228::fmt::Result { _serde::__private228::Formatter::write_str( __formatter, "struct Employee", ) } #[inline] fn visit_seq<__A>( self, mut __seq: __A, ) -> _serde::__private228::Result<Self::Value, __A::Error> where __A: _serde::de::SeqAccess<'de>, { let __field0 = match _serde::de::SeqAccess::next_element::< u64, >(&mut __seq)? { _serde::__private228::Some(__value) => __value, _serde::__private228::None => { return _serde::__private228::Err( _serde::de::Error::invalid_length( 0usize, &"struct Employee with 2 elements", ), ); } }; let __field1 = match _serde::de::SeqAccess::next_element::< String, >(&mut __seq)? { _serde::__private228::Some(__value) => __value, _serde::__private228::None => { return _serde::__private228::Err( _serde::de::Error::invalid_length( 1usize, &"struct Employee with 2 elements", ), ); } }; _serde::__private228::Ok(Employee { id: __field0, name: __field1, }) } #[inline] fn visit_map<__A>( self, mut __map: __A, ) -> _serde::__private228::Result<Self::Value, __A::Error> where __A: _serde::de::MapAccess<'de>, { let mut __field0: _serde::__private228::Option<u64> = _serde::__private228::None; let mut __field1: _serde::__private228::Option<String> = _serde::__private228::None; while let _serde::__private228::Some(__key) = _serde::de::MapAccess::next_key::< __Field, >(&mut __map)? { match __key { __Field::__field0 => { if _serde::__private228::Option::is_some(&__field0) { return _serde::__private228::Err( <__A::Error as _serde::de::Error>::duplicate_field("id"), ); } __field0 = _serde::__private228::Some( _serde::de::MapAccess::next_value::<u64>(&mut __map)?, ); } __Field::__field1 => { if _serde::__private228::Option::is_some(&__field1) { return _serde::__private228::Err( <__A::Error as _serde::de::Error>::duplicate_field("name"), ); } __field1 = _serde::__private228::Some( _serde::de::MapAccess::next_value::<String>(&mut __map)?, ); } _ => { let _ = _serde::de::MapAccess::next_value::< _serde::de::IgnoredAny, >(&mut __map)?; } } } let __field0 = match __field0 { _serde::__private228::Some(__field0) => __field0, _serde::__private228::None => { _serde::__private228::de::missing_field("id")? } }; let __field1 = match __field1 { _serde::__private228::Some(__field1) => __field1, _serde::__private228::None => { _serde::__private228::de::missing_field("name")? } }; _serde::__private228::Ok(Employee { id: __field0, name: __field1, }) } } #[doc(hidden)] const FIELDS: &'static [&'static str] = &["id", "name"]; _serde::Deserializer::deserialize_struct( __deserializer, "Employee", FIELDS, __Visitor { marker: _serde::__private228::PhantomData::<Employee>, lifetime: _serde::__private228::PhantomData, }, ) } } }; fn main() {}Как видите, реализация
Serializeочень простая. Она состоит из метода, который выдаёт метаинформацию о структуре: имя cтруктуры и перечень полей.Реализация
Deserializeкуда сложнее. В рамках неё генерируется визитор (шаблон Visitor), который используется для обхода полей структуры.
Сериализация в JSON
Теперь давайте разберёмся, как нам сериализовать нашу структуру Employee в JSON.
Для начала нам понадобится добавить зависимость на serde_json в Cargo.toml:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
serde = { version = "1", features = ["derive"] }
serde_json = "1"
Теперь мы можем использовать функции:
- serde_json::to_string — сериализует объект в JSON-строку
- serde_json::from_str — десериализует JSON-строку в объект
Пример:
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
struct Employee {
id: u64,
name: String,
}
fn main() {
// объект структуры
let emp1 = Employee {
id: 1,
name: "John Doe".to_string(),
};
// сериализация в JSON-строку
let json = serde_json::to_string(&emp1).unwrap(); // сериализуем в JSON
println!("{json}"); // {"id":1,"name":"John Doe"}
// десериализация из JSON строки
let emp2: Employee = serde_json::from_str( // десериализуем из JSON
r#"{ "id" : 2, "name" : "Ivan Ivanov" }"#
).unwrap();
println!("{emp2:?}"); // Employee { id: 2, name: "Ivan Ivanov" }
}serde_json::Value
Также в крэйте serde_json определено перечисление Value, которое по сути является отображением JSON типов на Rust перечисление.
pub enum Value {
Null,
Bool(bool),
Number(Number),
String(String),
Array(Vec<Value>),
Object(Map<String, Value>),
}Если мы хотим “вручную” разобрать JSON документ, то мы можем распарсить документ в объект Value, который потом можно разбирать удобным для нас способом.
Чтобы из текстового JSON документа получить объект Value, используется уже знакомая нам функция serde_json::from_str:
let v: Value = serde_json::from_str("{ \"a\": 1 }").expect("Invalid json");Далее при помощи паттерн-матчинга можно разбирать объект Value.
Продемонстрируем на примере:
use serde;
use serde_json;
use serde_json::Value;
fn main() {
// Парсим JSON документ, содержащий число
let v1: Value = serde_json::from_str("5").unwrap();
match v1 {
Value::Number(n) => println!("Number: {n}"),
_ => (),
}
// Парсим JSON документ, содержащий строку
let v2: Value = serde_json::from_str("\"text\"").unwrap();
match v2 {
Value::String(s) => println!("String: {s}"),
_ => (),
}
// Парсим JSON документ, содержащий массив чисел
let v3: Value = serde_json::from_str("[1,2,3]").unwrap();
match v3 {
Value::Array(arr) => {
print!("Array:");
for e in arr {
match e {
Value::Number(n) => print!(" {n}"),
_ => (),
}
}
println!("");
}
_ => (),
}
// Парсим JSON документ, содержащий объект
let v4: Value = serde_json::from_str(
r#"
{"id" : 1, "name" : "John Doe"}
"#,
)
.unwrap();
match v4 {
Value::Object(fields) => {
println!("Object:");
match fields.get("id") {
Some(Value::Number(n)) => println!(" id = {n}"),
_ => (),
};
match fields.get("name") {
Some(Value::String(s)) => println!(" name = {s}"),
_ => (),
};
}
_ => (),
}
}Вывод программы:
Number: 5
String: text
Array: 1 2 3
Object:
id = 1
name = John Doe
XML сериализация
Сериализация в XML работает по тому же принципу, что и сериализация в JSON. Непосредственная работа с XML осуществляется при помощи крэйта serde-xml-rs, который полагается на реализации Serialize и Deserialize, сгенерированные serde.
Для начала нам нужно добавить serde-xml-rs зависимость в Cargo.toml:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
serde = { version = "1", features = ["derive"] }
serde-xml-rs = "0.8.2"
Теперь мы можем адаптировать наш пример по сериализации в JSON под работу с XML:
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
struct Employee {
id: u64,
name: String,
}
fn main() {
let emp1 = Employee {
id: 1,
name: "John Doe".to_string(),
};
let xml = serde_xml_rs::to_string(&emp1).unwrap(); // сериализуем в XML
println!("{xml}");
let emp2: Employee = serde_xml_rs::from_str( // десериализуем из XML
r#"<Employee><id>1</id><name>John Doe</name></Employee>"#
).unwrap();
println!("{emp2:?}");
}Вывод программы:
$ cargo run
<?xml version="1.0" encoding="UTF-8"?><Employee><id>1</id><name>John Doe</name></Employee>
Employee { id: 1, name: "John Doe" }
Как видите, благодаря serde, работа с XML очень похожа на работу с JSON.
Сериализация перечислений
Многие форматы данных (например JSON) не поддерживают тип перечисления, что создаёт небольшую проблему для сериализации Rust-объектов.
serde поддерживает несколько стратегий сериализации перечислений, которые мы рассмотрим на примерах с форматом JSON.
Стратегия сериализации перечислений, используемая по умолчанию (Externally tagged), подразумевает, что объект перечисления сериализуется в структуру вида:
"имя_варианта_перечисления": { значение }
То есть объект перечисления становится значением для поля, чьё имя содержит вариант из перечисления.
Например:
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
enum Employee {
Programmer { name: String, language: String },
Manager { name: String },
OfficeCat(String),
}
fn main() {
let programmer = Employee::Programmer {
name: "John Doe".to_string(),
language: "Rust".to_string(),
};
println!("{}", serde_json::to_string(&programmer).unwrap());
// {"Programmer":{"name":"John Doe","language":"Rust"}}
let manager = Employee::Manager {
name: "Ivan Ivanov".to_string(),
};
println!("{}", serde_json::to_string(&manager).unwrap());
// {"Manager":{"name":"Ivan Ivanov"}
let cat = Employee::OfficeCat("Shadow".to_string());
println!("{}", serde_json::to_string(&cat).unwrap());
// {"OfficeCat":"Shadow"}
}Другим вариантом сериализации перечислений является добавление в тело JSON объекта дополнительного поля-тега, которое будет хранить имя варианта перечисления. Имя этого поля-тега задаётся при помощи аннотации #[serde(tag="имя")].
Перепишем предыдущий пример с использованием тега:
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
#[serde(tag = "type")]
enum Employee {
Programmer { name: String, language: String },
Manager { name: String },
}
fn main() {
let programmer = Employee::Programmer {
name: "John Doe".to_string(),
language: "Rust".to_string(),
};
println!("{}", serde_json::to_string(&programmer).unwrap());
// {"type":"Programmer","name":"John Doe","language":"Rust"}
let manager = Employee::Manager {
name: "Ivan Ivanov".to_string(),
};
println!("{}", serde_json::to_string(&manager).unwrap());
// {"type":"Manager","name":"Ivan Ivanov"}
}Important
Имейте в виду, что эта стратегия работает только если все варианты перечисления — обычные структуры. Кортежные структуры не поддерживаются.
Если мы хотим, чтобы поля объекта перечисления хранились не на одном уровне с тегом, а во вложенном объекте, то мы можем указать имя поля для вложенного объекта: #[serde(tag="имя", content="поле")].
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
#[serde(tag = "type", content = "obj")]
enum Employee {
Programmer { name: String, language: String },
Manager { name: String },
OfficeCat(String),
}
fn main() {
let programmer = Employee::Programmer {
name: "John Doe".to_string(),
language: "Rust".to_string(),
};
println!("{}", serde_json::to_string(&programmer).unwrap());
// {"type":"Programmer","obj":{"name":"John Doe","language":"Rust"}}
let manager = Employee::Manager {
name: "Ivan Ivanov".to_string(),
};
println!("{}", serde_json::to_string(&manager).unwrap());
// {"type":"Manager","obj":{"name":"Ivan Ivanov"}}
let cat = Employee::OfficeCat("Shadow".to_string());
println!("{}", serde_json::to_string(&cat).unwrap());
// {"type":"OfficeCat","obj":"Shadow"}
}Можно также указать аннотацию #[serde(untagged)], которая приведёт к тому, что объект перечисления будет сериализоваться без каких-либо дополнительных полей или тегов, содержащих вариант структуры. Однако очевидно, что этот вариант следует использовать только в самых крайних случаях, так как он может легко привести к ситуации, когда корректная десериализация невозможна.
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
#[serde(untagged)]
enum Employee {
Programmer { name: String, language: String },
Manager { name: String },
}
fn main() {
let programmer = Employee::Programmer {
name: "John Doe".to_string(),
language: "Rust".to_string(),
};
println!("{}", serde_json::to_string(&programmer).unwrap());
// {"name":"John Doe","language":"Rust"}
let manager = Employee::Manager {
name: "Ivan Ivanov".to_string(),
};
println!("{}", serde_json::to_string(&manager).unwrap());
// {"name":"Ivan Ivanov"}
}Переименование полей
Если мы хотим, чтобы имя поля в сериализованном виде отличалось от имени поля в структуре, то нам поможет аннотация #[serde(rename = "сериализованное_имя")].
Например, мы хотим, чтобы поле с именем first_name было сериализовано в поле с именем name.
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
struct Employee {
#[serde(rename = "name")]
first_name: String,
}
fn main() {
// десериализуем
let emp1: Employee = serde_json::from_str(r#"{"name":"John"}"#).unwrap();
println!("{emp1:?}"); // Employee { first_name: "John" }
// сериализуем
let emp2 = Employee { first_name: "John Doe".to_string() };
println!("{}", serde_json::to_string(&emp2).unwrap()); // {"name":"John Doe"}
}Нотации именования
Имена полей в Rust следуют змеиной нотации (snake_case): имена начинаются со строчной буквы, и если имя поля состоит из нескольких слов, то слова разделяются символом подчёркивания.
Если необходимо, чтобы в сериализованном виде имена полей следовали другой нотации, то это можно указать при помощи аннотации #[serde(rename_all = "ИМЯ НОТАЦИИ")].
Доступные нотации именования:
lowercase— такоеимяполяUPPERCASE— ТАКОЕИМЯПОЛЯPascalCase— ТакоеИмяПоляcamelCase— такоеИмяПоляsnake_case— такое_имя_поляSCREAMING_SNAKE_CASE— ТАКОЕ_ИМЯ_ПОЛЯkebab-case— такое-имя-поляSCREAMING-KEBAB-CASE— ТАКОЕ-ИМЯ-ПОЛЯ
Пример: укажем, что при сериализации и десериализации должна использоваться верблюжья нотация (camelCase).
use serde;
use serde_json;
use serde::{Deserialize, Serialize};
#[derive(Debug, Serialize, Deserialize)]
#[serde(rename_all = "camelCase")]
struct Employee {
first_name: String,
}
fn main() {
let emp: Employee = serde_json::from_str(r#"{"fistName":"John"}"#).unwrap();
println!("{emp:?}");
}DeserializeOwned
Давайте внимательно посмотрим на трэйт Deserialize:
pub trait Deserialize<'de>: Sized {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where D: Deserializer<'de>;
}Как видите, у него имеется лайфтайм-параметр 'de, который привязан к объекту из которого производится десериализация.
В большинстве ситуаций мы даже не замечаем этот лайфтайм-параметр, но есть сценарии, где он может стать проблемой.
Например, мы хотим написать генерик структуру, которая хранит значение десериализуемого типа. Мы можем попытаться написать, что-то подобное:
struct Holder<'de, T> where T: Deserialize<'de> {
v: T,
}Однако компилятор не позволит скомпилировать такой код, выдав ошибку:
error[E0392]: lifetime parameter `'de` is never used
| struct Holder<'de, T>
| ^^^ unused lifetime parameter
Как видите, проблема в том, что лайфтайм-параметр используется только в трэйте Deserialize, но при этом не используется нигде в теле структуры.
Специально для решения этой проблемы, библиотека serde предоставляет трэйт-обёртку DeserializeOwned:
pub trait DeserializeOwned: for<'de> Deserialize<'de> { }Объявление DeserializeOwned использует HRTB (higher-ranked trait bounds — трэйт-границу высшего порядка), чтобы перенести лайфтайм ограничение с самого трэйта, тем самым убрав обязательный трэйт-параметр на наследуемый трэйт. При написании бэкенд-приложений, такая конструкция встречается довольно редко, поэтому мы не будем подробно её разбирать.
Используя DeserializeOwned, мы без проблем можем сделать генерик структуру, которая хранит в себе генерик тип, реализующий Deserialize.
use serde;
use serde_json;
use serde::de::DeserializeOwned;
#[derive(Debug)]
struct Holder<T> where T: DeserializeOwned {
v: T,
}
fn deserialize_into_holder<T: DeserializeOwned>(json: &str) -> Holder<T> {
let v: T = serde_json::from_str(json).unwrap();
Holder { v }
}
fn main() {
let json = String::from("5");
let h: Holder<i32> = deserialize_into_holder(&json);
println!("{h:?}");
}Tip
Подробную документацию по serde можно найти на официальном сайте https://serde.rs/
Дата и время
Таймеры
В стандартной библиотеке Rust отсутствует функциональность для работы с датами и астрономическим временем, но имеются следующие три типа:
- std::time::Duration — представляет собой временной отрезок.
Например: 5 секунд, 3 минуты, 1 час. - std::time::SystemTime — API для работы с системными часами.
- std::time::Instant — API для работы с монотонным таймером.
Duration
Тип Duration устроен очень просто:
#![allow(unused)]
fn main() {
#[derive(Clone, Copy, PartialEq, Eq, PartialOrd, Ord, Hash, Default)]
pub struct Duration {
secs: u64,
nanos: Nanoseconds,
}
}Он позволяет представлять временные промежутки большой длины (до 584 миллиардов лет) с точностью до наносекунды.
use std::time::Duration;
fn main() {
let d1 = Duration::from_secs(5); // 5 seconds
let d2 = Duration::from_mins(1); // 1 minute
let d3 = d2.saturating_sub(d1); // 55 seconds
println!("{}", d3.as_secs()); // 55
}Сам по себе тип Duration умеет немного, однако он используется как входной аргумент в различной функциональности. Например, стандартная функция sleep, которая останавливает выполнение потока на указанное время, принимает аргумент типа Duration.
SystemTime
Системный таймер хранит астрономическое время. Как правило, системное время реализовано при помощи чипа с кварцевым генератором, находящимся на системной плате и питаемым от батарейки, даже когда компьютер выключен.
Если мы хотим получить, например, текущее Unix время (количество секунд, прошедшее с 1 января 1970 года), то мы должны использовать как раз системный таймер.
use std::time::{Duration, SystemTime};
fn main() {
// Получаем текущее значение системного времени
let sys_time_now: SystemTime = SystemTime::now();
// Конвертируем системное время в Duration, начальной
// точкой которого является начало эпохи Unix
let unix_time_duration: Duration =
sys_time_now.duration_since(SystemTime::UNIX_EPOCH).unwrap();
// Конвертируем Duration в количество секунд
let unix_time_now: u64 = unix_time_duration.as_secs();
println!("Now (Unix-time): {unix_time_now}");
}Однако у системного таймера есть проблема: если вызвать SystemTime::now() и сразу после этого вызвать SystemTime::now() еще раз (особенно из другого потока), то есть вероятность, что время, полученное в результате второго вызова, будет раньше, чем время, полученное в результате первого вызова. Почему так происходит — отдельная история, но главное, что нам нужно знать: не следует использовать системный таймер для того, чтобы замерять время выполнения участков кода.
Instant
Монотонный таймер хранит не астрономическое время, а время, прошедшее с момента старта операционной системы. В зависимости от архитектуры компьютера и операционной системы, монотонный таймер может быть реализован по-разному. Например, на x86-64 процессорах монотонный таймер реализован в виде регистра TSC (Time Stamp Counter). Самое важное для нас то, что монотонный таймер гарантирует, что каждый последующий запрос текущего времени будет выдавать значение не меньшее, чем выдал предыдущий запрос. Поэтому монотонный таймер безопасно использовать для замера времени выполнения участков кода.
use std::time::{Duration, Instant};
fn main() {
let start = Instant::now();
//... какая-то функциональность
let took: Duration = start.elapsed();
}chrono
Стандартом де-факто для работы с датой и временем считается библиотека chrono.
Для представления даты и времени chrono предлагает следующие типы:
- NaiveDate — ISO 8601 дата без учёта часового пояса
- NaiveTime — ISO 8601 время без учёта часового пояса
- NaiveDateTime — ISO 8601 дата и время без учёта часового пояса
- DateTime<TimeZone> — ISO 8601 дата и время с учётом часового пояса
Давайте подключим chrono в качестве зависимости в Cargo.toml:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
chrono = { version = "0.4", features = ["serde"]}
Note
Обратите внимание, что типы данных из библиотеки chrono поддерживают сериализацию посредством serde, однако эту функциональность надо отдельно включить при помощи фичи “serde”.
NaiveDate
Рассмотрим тип NaiveDate, который позволяет:
- создавать объект даты
- конвертировать дату в строковое представление
- парсить дату из строки
- добавлять и вычитать годы, месяцы и дни
- итерироваться по дням, месяцам, годам
Рассмотрим эти возможности на примере:
use chrono;
use chrono::{Days, Months, NaiveDate};
fn main() {
let date: NaiveDate = NaiveDate::from_ymd_opt(2025, 12, 15).unwrap();
println!("{:?}", date); // 2025-12-15
println!("{}", date.format("%Y-%m-%d")); // 2025-12-15
println!("{}", date.format("%Y/%d/%m")); // 2025/15/12
let date = NaiveDate::parse_from_str("2025-01-01", "%Y-%m-%d").unwrap();
let three_days = date.iter_days()
.skip(1)
.take(3)
.map(|d|d.to_string())
.collect::<Vec<_>>()
.join(",");
println!("Three days since {date}: {three_days}");
// Three days since 2025-01-01: 2025-01-02,2025-01-03,2025-01-04
let new_date = date.checked_add_months(Months::new(2)).unwrap()
.checked_add_days(Days::new(5)).unwrap();
println!("{}", new_date); // 2025-03-06
}NaiveTime
Тип NaiveTime предоставляет похожую функциональность, но для времени:
use chrono;
use chrono::NaiveTime;
fn main() {
let time1: NaiveTime = NaiveTime::from_hms_opt(13, 51, 10).unwrap();
println!("{:?}", time1); // 13:51:10
println!("{}", time1.format("%H-%M-%S")); // 13-51-10
let time2 = NaiveTime::parse_from_str("12:01:00", "%H:%M:%S").unwrap();
let time_diff = time1.signed_duration_since(time2);
println!("{} seconds", time_diff.num_seconds()); // 6610 seconds
}NaiveDateTime
NaiveDateTime — это комбинация NaiveDate и NaiveTime.
use chrono;
use chrono::{NaiveDate, NaiveDateTime, NaiveTime};
fn main() {
let dt: NaiveDateTime = NaiveDateTime::new(
NaiveDate::from_ymd_opt(2025, 11, 15).unwrap(),
NaiveTime::from_hms_nano_opt(13, 51, 10,123456789).unwrap()
);
println!("{}", dt); // 2025-11-15 13:51:10.123456789
println!("{}", dt.format("%Y-%m-%dT%H:%M:%S.%3f")); // 2025-11-15T13:51:10.123
let dt = NaiveDateTime::parse_from_str(
"2025-11-15T13:51:10.123", "%Y-%m-%dT%H:%M:%S.%3f"
).unwrap();
let date = dt.date();
let time = dt.time();
}DateTime
DateTime<Tz> хранит дату и время с учетом часового пояса, причём часовой пояс задаётся генерик тип-аргументом, реализующим трэйт TimeZone.
Библиотека chrono содержит три стандартных реализации для трэйта TimeZone:
- Utc — UTC часовой пояс (нулевой меридиан)
- Local — текущий часовой пояс
- FixedOffset — хранит фиксированный сдвиг в секундах относительно UTC
Эти реализации проще понять на примере:
use chrono;
use chrono::{DateTime, FixedOffset, Local, Utc};
fn main() {
// Получаем текущие дату и время в UTC и локальной тайм зоне
let utc: DateTime<Utc> = Utc::now();
let local: DateTime<Local> = Local::now();
// Конвертируем в форму с фиксированным сдвигом
let utc_fixed: DateTime<FixedOffset> = utc.fixed_offset();
let local_fixed: DateTime<FixedOffset> = local.fixed_offset();
println!("UTC: {utc}");
println!("Local: {local}");
println!("UTC fixed: {}", utc_fixed);
println!("Local fixed: {}", local_fixed);
// Конвертируем дату и время из формы с таймзоной в форму без таймзоны
println!("UTC -> naive UTC: {}", utc.naive_utc());
println!("UTC -> naive Local: {}", utc.naive_local());
println!("Local -> naive Local: {}", local.naive_local());
println!("Local -> naive UTC: {}", local.naive_utc());
}Вывод программы (компьютер, запускавший пример, находился в часовом поясе +2):
UTC: 2025-12-15 14:42:07.078561733 UTC
Local: 2025-12-15 16:42:07.078569548 +02:00
UTC fixed: 2025-12-15 14:42:07.078561733 +00:00
Local fixed: 2025-12-15 16:42:07.078569548 +02:00
UTC -> naive UTC: 2025-12-15 14:42:07.078561733
UTC -> naive Local: 2025-12-15 14:42:07.078561733
Local -> naive Local: 2025-12-15 16:42:07.078569548
Local -> naive UTC: 2025-12-15 14:42:07.078569548
Объект DateTime также может быть создан:
- из компонентов времени и даты
- из объекта
NaiveDateTimeпутём указания тайм зоны - распарсив строку
use chrono;
use chrono::{DateTime, NaiveDate, TimeZone, Utc};
fn main() {
let utc1: DateTime<Utc> = Utc.with_ymd_and_hms(2025, 12, 15, 13, 51, 10).unwrap();
println!("{utc1}"); // 2025-12-15 13:51:10 UTC
let utc2: DateTime<Utc> =
NaiveDate::from_ymd_opt(2025, 12, 15).unwrap() // Создаём NavieDate
.and_hms_opt(13, 51, 10).unwrap() // Превращаем в NaiveDateTime
.and_utc(); // Добавляем тайм зону
println!("{utc2}"); // 2025-12-15 13:51:10 UTC
let dt = DateTime::parse_from_str(
"2025-12-15 13:51:10 +0000",
"%Y-%m-%d %H:%M:%S %z"
).unwrap();
println!("{dt}"); // 2025-12-15 13:51:10 +00:00
let utc3 = dt.to_utc();
println!("{utc3}"); // 2025-12-15 13:51:10 UTC
}Чтобы получить строковое представление объекта DateTime, так же как и для Naive* собратьев, используется метод format. Плюс имеются отдельные методы для форматирования в RFC2822 и RFC3339.
use chrono;
use chrono::{TimeZone, Utc};
fn main() {
let utc = Utc.with_ymd_and_hms(2025, 12, 15, 13, 51, 10).unwrap();
println!("RFC3339: {}", utc.to_rfc3339());
// RFC3339: 2025-12-15T13:51:10+00:00
println!("RFC2822: {}", utc.to_rfc2822());
// RFC2822: Mon, 15 Dec 2025 13:51:10 +0000
println!("{}", utc.format("%Y-%m-%d %H:%M:%S.%3f %z"));
// 2025-12-15 13:51:10.000 +0000
}Последнее, с чем нам осталось разобраться — DateTime<FixedOffset>. Тип FixedOffset позволяет задавать любую тайм зону путём указания смещения в секундах относительно UTC. Для примера давайте создадим тайм зону UTC+2:30, т.е. смещение на восток от Гринвича на 2 часа 30 минут.
use chrono;
use chrono::{DateTime, FixedOffset, TimeZone, Utc};
fn main() {
// Количество секунд в 2 часах и 30 минутах
let hours_02_minutes_30 = 2 * 3600 + 30 * 60;
// Таймзона со сдвигом +02:30
let tz_02_30: FixedOffset = FixedOffset::east_opt(hours_02_minutes_30).unwrap();
// Создание объекта DateTime из временных компонентов
let dt: DateTime<FixedOffset> =
tz_02_30.with_ymd_and_hms(2025, 12,15, 13, 51, 10).unwrap();
println!("{dt}"); // 2025-12-15 13:51:10 +02:30
// Конвертирование UTC времени в UTC+2:30
let now_utc: DateTime<Utc> = Utc::now();
let now_02_30: DateTime<FixedOffset> = now_utc.with_timezone(&tz_02_30);
println!("UTC: {now_utc}"); // UTC: 2025-12-15 16:42:19.043035374 UTC
println!("+02:30: {now_02_30}"); // +02:30: 2025-12-15 19:12:19.043036305 +02:30
}Логирование
В рамках изучения логирования, мы будем рассматривать библиотеку tracing. Эта библиотека представляет из себя целую экосистему для логирования, но основных крэйта в ней два:
- tracing — предоставляет API для логирования (является фасадом)
- tracing-subscriber — реализация логгера для tracing
В экосистеме Rust также присутствует другая популярная библиотека логирования — log (фасад) и её реализации: env_logger и log4rs. Но мы сосредоточимся только на tracing по двум причинам:
- tracing изначально создана с прицелом на асинхронность, что важно для бекенд приложений
- tracing также умеет работать с библиотеками, которые используют log для логирования
Первый взгляд на tracing
Для начала нам нужно подключить в Cargo.toml соответствующие зависимости:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
tracing = "0.1"
tracing-subscriber = { version = "0.3", features = ["env-filter", "time", "json"] }
Теперь мы готовы воспользоваться логгером:
fn main() {
tracing_subscriber::fmt().init(); // Включаем tracing логирование
tracing::info!("Hello"); // Пишем в лог информационное сообщение
}Если мы запустим программу, то увидим в консоли такое лог-сообщение.
$ cargo run
2025-12-15T23:04:17.046455Z INFO test_rust: Hello
Оно состоит из следующих компонентов:
2025-12-15T23:04:17.046455Z— время создания лог-сообщенияINFO— уровень лог-сообщенияtest_rust— имя программыHello— текст лог-сообщения
Внутреннее устройство
Давайте еще раз взглянем на наш пример:
fn main() {
tracing_subscriber::fmt().init();
tracing::info!("Hello");
}Запись tracing_subscriber::fmt().init() является сокращённой и делает сразу несколько вещей. Для ясности давайте распишем этот пример подробнее:
use tracing_subscriber::FmtSubscriber;
use tracing_subscriber::fmt::SubscriberBuilder;
use tracing_subscriber::util::SubscriberInitExt;
fn main() {
let builder: SubscriberBuilder = tracing_subscriber::fmt();
let subscriber: FmtSubscriber = builder.finish();
subscriber.init(); // регистрация сабскрайбера в глобальном диспатчере
tracing::info!("Hello");
}Здесь мы делаем следующее:
tracing_subscriber::fmt()— создаём билдер SubscriberBuilder, который позволяет провести настройку сабскрайбера.builder.finish()— создаём объект сабскрайбера (Subscriber), который является непосредственным обработчиком лог-сообщений. (В примере тип сабскрайбера —FmtSubscriber, но это просто псевдоним для генерик структурыSubscriber).subscriber.init()— регистрируем объект сабскрайбера в глобальном диспетчере (dispatcher).tracing::info!("Hello")— отправляем лог-событие глобальному диспетчеру, который перенаправит его для обработки в сабскрайбер.
Упрощённо, работа механизма логирования выглядит так:

Для нас, как для пользователей библиотеки tracing, наиболее важным элементом является сам Subscriber.
pub struct Subscriber<
N = format::DefaultFields, // перечень полей лог-сообщения
E = format::Format<format::Full>, // формат лог-сообщения
F = LevelFilter, // уровни логирования: TRACE, DEBUG, INFO, WARN, ERROR
W = fn() -> io::Stdout, // то куда производится запись, по умолчанию - STDOUT
> {
inner: layer::Layered<F, Formatter<N, E, W>>,
}На данный момент эта структура должна быть совершенно непонятной, но к концу главы мы разберёмся со всеми её составляющими. А пока давайте приступим к практике логирования.
Note
Если решите покопаться во внутренностях библиотеки, имейте в виду, что есть трэйт Subscriber, объявленный в крэйте tracing, а есть одноимённая структура Subscriber из крэйта tracing-subscriber. В этой главе, мы в основном имеем дело со структурой
Subscriber, но если вам понадобится реализовать какой-то очень специфический логгер, например, который пишет логи напрямую в базу данных, то вам, скорее всего, придётся реализовать именно трэйтSubscriber.
Формат лог-записей
Билдер SubscriberBuilder, с которым мы уже познакомились, позволяет настроить формат логирования для сабскрайбера. Билдер предоставляет следующие методы для настройки формата лог-записей:
with_ansi(bool)— указывает, будет ли логгер использовать управляющие ANSI коды для того, чтобы выделять разные части лог-записи разными цветами. При перенаправлении логов с консоли в файл этот флаг следует устанавливать вfalse. По умолчанию:true.with_file(bool)— добавлять ли в лог-запись имя файла, из которого было произведено логирование. По умолчанию:false.with_line_number(bool)— добавлять ли в лог-запись номер строки, из которой было произведено логирование. По умолчанию:false.with_target(bool)— добавлять ли в лог-запись имя программы. По умолчанию:true.with_thread_ids(bool)— добавлять ли в лог-запись ID потока, из которого было произведено логирование. По умолчанию:false.with_thread_names(bool)— добавлять ли в лог-запись имя потока, из которого было произведено логирование. По умолчанию:false.with_timer(Format)— определяет формат даты и времени в лог-записи. По умолчанию: UtcTime.without_time()— выключает отображение даты и времени в лог-записи.json()— лог-запись будет представлена в виде JSON объекта. Доступно только при включенной “json” фиче.
Для примера, настроим формат лог-сообщений так, чтобы убрать из них имя приложения, но добавить имя файла и номер строки. Плюс вместо астрономического времени будет отображаться, сколько времени прошло с момента запуска программы.
use tracing_subscriber::fmt::time::Uptime;
fn main() {
tracing_subscriber::fmt()
.with_target(false)
.with_file(true)
.with_line_number(true)
.with_timer(Uptime::default())
.init();
tracing::info!("Hello");
}Вывод программы:
$ cargo run
0.000186881s INFO src/main.rs:11: Hello
Отдельно стоит отметить форматирование в виде JSON объекта:
fn main() {
tracing_subscriber::fmt().json().init();
tracing::info!("Hello");
}Программа выведет:
$ cargo run
{"timestamp":"2025-12-17T14:28:29.197314Z","level":"INFO","fields":{"message":"Hello"},"target":"test_rust"}
Уровни логирования
tracing предлагает пять уровней логирования: TRACE, DEBUG, INFO, WARN, ERROR. По умолчанию логируются все лог-сообщения с уровнем INFO и выше.
То есть такая программа:
fn main() {
tracing_subscriber::fmt().init();
tracing::trace!("Hello");
tracing::debug!("Hello");
tracing::info!("Hello");
tracing::warn!("Hello");
tracing::error!("Hello");
}выведет:
$ cargo run
2025-12-16T14:57:02.786497Z INFO test_rust: Hello
2025-12-16T14:57:02.786556Z WARN test_rust: Hello
2025-12-16T14:57:02.786567Z ERROR test_rust: Hello
Чтобы установить отображаемый уровень логирования, используется метод with_max_level из билдера SubscriberBuilder. Например, если мы хотим, чтобы выводились уровни DEBUG, INFO, WARN и ERROR, то надо настроить сабскрайбер так:
tracing_subscriber::fmt()
.with_max_level(LevelFilter::DEBUG)
.init();Фильтрация сообщений
Если вы включите DEBUG или TRACE уровень логирования в приложении, в котором имеются зависимости (другие Rust библиотеки), то велика вероятность, что, кроме логов непосредственно из вашего кода, вы увидите целый шквал сообщений из кода зависимостей.
К счастью, tracing-subscriber позволяет фильтровать лог-сообщения по таким критериям как:
- target — он же крэйт
- модуль
- уровень лога
Фильтр задаётся на билдере SubscriberBuilder при помощи метода with_env_filter, который принимает аргумент типа impl Into<EnvFilter>.
Объект EnvFilter можно сконструировать “руками”, но гораздо проще задать его строкой. Эта строка должна содержать разделённые запятой секции вида таргет::модуль=уровень, где:
- таргет (опционален) — имя крэйта, из которого происходит логирование
- модуль (опционален) — имя модуля в этом крэйте, из которого происходит логирование
- уровень — уровень логирования
Например, строка "myapp::mod1=debug,myapp::mod2=trace,info" указывает, что для всего приложения должен использоваться уровень INFO, но для модуля mod1 из крэйта myapp должен использоваться уровень DEBUG, а для модуля mod1 из крэйта myapp — TRACE.
Важно заметить, что порядок секций в строке не важен: если мы поменяем строку на "info,myapp::mod1=debug,myapp::mod2=trace", то ничего не изменится.
В качестве примера рассмотрим программу с двумя модулями: для одного модуля будет установлен DEBUG уровень, для другого — WARN, а для всего приложения — INFO.
fn main() {
tracing_subscriber::fmt()
.with_env_filter("test_rust::mod_a=debug,test_rust::mod_b=warn,info")
.init();
mod_a::func();
mod_b::func();
tracing::info!("from root: test");
}
mod mod_a {
pub fn func() {
// выведется, так как для этого модуля уровень логирования - DEBUG
tracing::debug!("from mod_a: test");
}
}
mod mod_b {
pub fn func() {
// не выведется, так как для этого модуля уровень логирования - WARN
tracing::info!("from mod_b: test");
}
}Запустим программу:
$ cargo run
2025-12-16T20:09:58.958779Z DEBUG test_rust::mod_a: from mod_a: test
2025-12-16T20:09:58.958855Z INFO test_rust: from root: test
Альтернативно, вместо указания правил фильтрации в виде одной строки, мы можем создать объект EnvFilter вручную:
let filter = tracing_subscriber::EnvFilter::from_default_env()
.add_directive("test_rust::mod_a=debug".parse().unwrap())
.add_directive("test_rust::mod_b=warn".parse().unwrap())
.add_directive("info".parse().unwrap());
tracing_subscriber::fmt()
.with_env_filter(filter)
.init();но на практике так обычно не делают, потому что для программ на Rust принято задавать опции фильтрации логов при помощи переменной окружения RUST_LOG.
Для этого достаточно просто сконфигурировать фильтр логов так:
tracing_subscriber::fmt()
.with_env_filter(tracing_subscriber::EnvFilter::from_default_env())
.init();и после этого можно задавать опции фильтрации через переменную окружения:
$ export RUST_LOG="test_rust::mod_a=debug,test_rust::mod_b=warn,info"
$ cargo run
2025-12-16T20:09:58.958779Z DEBUG test_rust::mod_a: from mod_a: test
2025-12-16T20:09:58.958855Z INFO test_rust: from root: test
Note
На Windows:
set RUST_LOG="test_rust::mod_a=debug,test_rust::mod_b=warn,info" cargo run 2025-12-16T20:09:58.958779Z DEBUG test_rust::mod_a: from mod_a: test 2025-12-16T20:09:58.958855Z INFO test_rust: from root: test
Запись логов в файл
По умолчанию логи пишутся на стандартный вывод, но это можно изменить путём задания альтернативного приёмника при помощи метода with_writer у билдера SubscriberBuilder.
Этот метод принимает объект любого типа, реализующего трэйт MakeWriter, что включает любые типы, реализующие трэйт std::io::Write. А так как тип std::fs::File реализует std::io::Write, то примитивное логирование в файл можно реализовать так:
fn main() {
let file = std::fs::File::create("app.log").unwrap();
tracing_subscriber::fmt()
.with_writer(file)
.with_ansi(false) // консольные управляющие символы в файле не нужны
.init();
tracing::info!("Hello");
}Запустив эту программу, вы увидите, что действительно был создан файл app.log.
Разумеется, в долгоживущем бекенд приложении нужна более гибкая запись логов в файл. Экосистема tracing предлагает библиотеку tracing-appender, которая умеет:
- производить запись логов в файл в неблокирующем режиме
- автоматически переключаться на новый лог файл каждый день/час/минуту/и т.д.
- автоматически удалять устаревшие файлы с логами
Для начала подключим tracing-appender в Cargo.toml.
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
tracing = "0.1"
tracing-subscriber = { version = "0.3", features = ["env-filter", "time"] }
tracing-appender = "0.2"
Теперь давайте настроим логирование так, чтобы запись логов производилась в каталог logs, а файлы с логами имели префикс app.log, и новый лог файл создавался каждый час.
fn main() {
let appender = tracing_appender::rolling::daily("logs", "app.log");
tracing_subscriber::fmt()
.with_writer(appender)
.with_ansi(false)
.init();
tracing::info!("Hello");
}После запуска программы в каталоге проекта должна появиться директория logs, в которой должен находиться файл с именем формата app.log.год-месяц-день.
Если нам потребуется более гибкая настройка, то мы должны воспользоваться билдером RollingFileAppender.
use tracing_appender::rolling::{RollingFileAppender, Rotation};
fn main() {
let appender = RollingFileAppender::builder()
.rotation(Rotation::DAILY) // ротация лог-файла каждый день
.max_log_files(10) // хранить только 10 последних лог-файлов
.filename_prefix("app") // префикс имени лог-файла до компонента даты
.filename_suffix("log") // суффикс имени лог-файла после компонента даты
.build("logs") // имя директории для лог-файлов
.unwrap();
tracing_subscriber::fmt()
.with_writer(appender)
.with_ansi(false)
.init();
tracing::info!("Hello");
}После запуска в каталоге logs должен появиться лог-файл с именем формата app.год-месяц-день.log. Например, app.2025-12-17.log.
Если мы хотим писать логи одновременно и в файл, и на консоль, то для простоты можем воспользоваться комбинатором and из утилитарного трэйта MakeWriterExt, который позволяет скомбинировать два приёмника логов в один.
use tracing_subscriber::fmt::writer::MakeWriterExt;
fn main() {
let file_appender = tracing_appender::rolling::daily("logs", "app.log")
.with_max_level(tracing::Level::INFO);
let stdout_appender = std::io::stdout
.with_max_level(tracing::Level::DEBUG);
tracing_subscriber::fmt()
.with_writer(stdout_appender.and(file_appender))
.with_ansi(false)
.init();
tracing::info!("Hello");
}В случае если для каждого из приёмников логов требуется более тонкая настройка, придётся воспользоваться слоями, о которых мы поговорим дальше в этой главе.
Неблокирующее логирование
Как мы уже сказали в предыдущей секции, библиотека tracing-appender предоставляет не только функциональность для гибкой записи логов в файл, но также и функциональность для неблокирующей записи.
Для того чтобы сделать из синхронного писателя неблокирующий, нужно воспользоваться функцией non_blocking:
fn main() {
let (non_blocking, _guard) = tracing_appender::non_blocking(std::io::stdout());
tracing_subscriber::fmt()
.with_writer(non_blocking)
.init();
tracing::info!("Hello");
}Функция non_blocking запускает отдельный поток, который по каналу принимает лог-сообщения и производит запись. Функция non_blocking возвращает кортеж из двух объектов:
- Объект типа NonBlocking, который по сути является обёрткой над отправителем (Sender) лог-сообщений в канал.
- Охранный объект типа WorkerGuard, чей деструктор сначала убедится, что все лог-сообщения из канала записаны, а после завершит поток и уничтожит канал. Нужен для корректного завершения приложения.
Warning
Важно! Если новые лог-сообщения будут поступать быстрее, чем поток будет успевать их записывать, то канал переполнится и новые лог-сообщения будут просто отбрасываться. Размер канала по умолчанию рассчитан на 128000 лог-сообщений.
Слои
Layer (слой) — трэйт, задающий интерфейс для фильтрации, форматирования и записи логов. Совсем как сабскрайбер. Однако, в отличие от сабскрайберов, несколько слоёв можно объединить в один и использовать этот объёдинённый слой как сабскайбер. При этом каждый из слоёв может быть сконфигурирован так же гибко, как сабскрайбер.
Например, мы можем создать один слой для записи логов в стандартный вывод, другой слой — для записи в файла. Комбинация этих слоёв будет производить запись и в стандартный вывод, и в файл.
Для создания логгера из слоёв, мы должны использовать объект Registry, который создаётся функцией tracing_subscriber::registry(). Это легче понять на примере:
use tracing_subscriber::{fmt::layer, layer::SubscriberExt, util::SubscriberInitExt};
fn main() {
// Слой для записи в файл
let file_layer = layer()
.with_writer(tracing_appender::rolling::daily("logs", "app.log"))
.with_ansi(false);
// Слой для записи на консоль
let stdout_layer = layer()
.with_writer(std::io::stdout);
tracing_subscriber::registry() // registry() вместо fmt()
.with(stdout_layer)
.with(file_layer)
.init();
tracing::info!("Hello");
}Запустив программу, мы увидим, что она записала лог-сообщение и на консоль, и в файл.
И на этом моменте мы готовы еще раз взглянуть на определение структуры Subscriber, которое мы видели в самом начале главы:
pub struct Subscriber<
N = format::DefaultFields, // перечень полей лог-сообщения
E = format::Format<format::Full>, // формат лог-сообщения
F = LevelFilter, // уровни логирования: TRACE, DEBUG, INFO, WARN, ERROR
W = fn() -> io::Stdout, // то куда производится запись, по умолчанию - STDOUT
> {
inner: layer::Layered<F, Formatter<N, E, W>>, // слои
}Как видите, эта структура содержит поле inner, которое имеет тип Layered — хранилище слоёв. На самом деле, все наши сабскрайберы из предыдущих примеров, всегда состояли из слоёв. Просто у них был только один слой.
Теперь мы можем детализировать раньше приведённую диаграмму, указав внутреннее устройство стандартного сабскрайбера (структуры из библиотеки tracing-subscriber).

Т.е. когда мы конфигурируем логгер просто как:
tracing_subscriber::fmt().init()то создаётся сабскрайбер с одним слоем, который печатает логи в STDOUT.
Span
Последнее, с чем нам осталось познакомиться — span (диапазон, охват). Это понятие сложно перевести на русский, поэтому мы будем называть его просто span.
Span представляет некий участок кода, к которому можно привязать контекст логирования с дополнительными атрибутами.
И это гораздо проще понять на примере:
use tracing::{Span, span::Entered};
fn main() {
tracing_subscriber::fmt().init();
// Для INFO логов создаём span с атрибутом attr1 и значение 5
let my_span: Span = tracing::span!(tracing::Level::INFO, "span1", attr1 = 5);
let _enter: Entered<'_> = my_span.enter();
tracing::info!("Hello");
}Такая программа напечатает:
2025-12-17T23:07:23.633043Z INFO span1{attr1=5}: test_rust: Hello
Как видите, в строке лога добавилось span1{attr1=5}.
Как это работает?
- Сначала мы создаём объект типа Span, при помощи которого говорим, что хотим, чтобы для логов с уровнем INFO добавлялся атрибут с именем “attr1” и значением
5. - Далее мы мы “активируем” span в текущей области путём вызова метода enter. Этот метод возвращает объект типа Entered, который представляет из себя активированный span.
- В той области кода, в которой жив объект
Entered, к логам будут добавляться атрибуты из span объекта.
Рассмотрим следующий пример, который наглядно демонстрирует, что атрибуты из span добавляются в лог-сообщение, только в той области, где существует объект Entered.
fn main() {
tracing_subscriber::fmt().init();
let my_span = tracing::span!(tracing::Level::INFO, "span1", attr1 = 5);
{
let mut _enter = my_span.enter();
tracing::info!("Hello 1");
}
tracing::info!("Hello 2");
}Вывод программы.
2025-12-17T23:35:55.528112Z INFO span1{attr1=5}: test_rust: Hello 1
2025-12-17T23:35:55.528148Z INFO test_rust: Hello 2
В большинстве ситуаций мы хотим “активировать” span сразу после его создания, но мы не можем написать так:
let my_span: Entered<'_> = tracing::span!(Level::INFO, "span1", attr1 = 5).enter();Дело в том, что объект Entered хранит ссылку на объект span, от которого он был создан. А так как в коде выше, объект span создаётся и сразу же уничтожается, то ссылку становится хранить не на что.
Для решения этой проблемы тип Span предлагает другой метод — entered, который возвращает объект типа EnteredSpan. Он ведёт себя подобно Entered, но вместо того, чтобы держать ссылку на объект Span, он забирает объект Span себе во владение.
use tracing::{Level, span::EnteredSpan};
fn main() {
tracing_subscriber::fmt().init();
let my_span: EnteredSpan = tracing::span!(Level::INFO, "span1", attr1 = 5)
.entered();
tracing::info!("Hello 1");
my_span.exit();
tracing::info!("Hello 2");
}Программа выводит:
2025-12-18T00:34:31.045841Z INFO span1{attr1=5}: test_rust: Hello 1
2025-12-18T00:34:31.045887Z INFO test_rust: Hello 2
В работе, подход с методом entered используется чаще, потому что он короче. Но в этой главе мы продолжим использовать метод enter, так как он более наглядный.
Пересечение span
Когда мы создаём объект span в области, где уже активирован другой span, то уже активированный span становится родителем свежесозданного. Это означает, что в лог-сообщение попадут атрибуты и из родительского, и из дочернего span-ов.
Рассмотрим это на примере:
fn main() {
tracing_subscriber::fmt().init();
let span1 = tracing::span!(tracing::Level::INFO, "span1", attr1 = 5);
let _enter1 = span1.enter();
let span2 = tracing::span!(tracing::Level::INFO, "span2", attr2 = 7);
let _enter2 = span2.enter();
tracing::info!("Hello");
}Вывод программы:
2025-12-17T23:08:54.836930Z INFO span1{attr1=5}:span2{attr2=7}: test_rust: Hello
Теперь давайте перепишем этот пример так, чтобы второй объект span создавался до активации первого span. В такой ситуации отношение родитель-потомок установлено не будет, и последний активированный span просто перекроет собой всё, что было активировано до него.
fn main() {
tracing_subscriber::fmt().init();
let span1 = tracing::span!(tracing::Level::INFO, "span1", attr1 = 5);
let span2 = tracing::span!(tracing::Level::INFO, "span2", attr2 = 7);
let _enter1 = span1.enter();
let _enter2 = span2.enter(); // перекроет собой span1
tracing::info!("Hello");
}Вывод программы:
2025-12-17T23:09:36.704697Z INFO span2{attr2=7}: test_rust: Hello
Также, надо заметить, что макрос span! позволяет при помощи параметра parent явно указать родительский span.
fn main() {
tracing_subscriber::fmt().init();
let span1 = tracing::span!(tracing::Level::INFO, "span1", attr1 = 5);
let span2 = tracing::span!(parent: &span1, tracing::Level::INFO, "span2", attr2 = 7);
let _enter1 = span1.enter();
let _enter2 = span2.enter();
tracing::info!("Hello");
}Эта программа уже выводит атрибуты от обоих span:
2025-12-18T00:55:30.040449Z INFO span1{attr1=5}:span2{attr2=7}: test_rust: Hello
instrument
Библиотека tracing предоставляет макрос instrument, который позволяет “инструментировать” определение функции, путём оборачивания её тела в span.
Рассмотрим пример:
fn main() {
tracing_subscriber::fmt().init();
let _ = func(1, "PARAM2");
}
#[tracing::instrument]
fn func(param1: i32, param2: &str) -> String {
tracing::info!("Hello");
String::from("RESULT")
}Вывод программы
2025-12-18T15:27:16.330514Z INFO func{param1=1 param2="PARAM2"}: test_rust: Hello
Как видите, инструментирование создаёт span с таким же именем, как у функции, и с атрибутами, совпадающими с аргументами функции.
Макрос instrument предлагает ряд параметров для настройки:
fn main() {
tracing_subscriber::fmt()
.without_time()
.init();
let _ = func(1, "PARAM2");
}
#[tracing::instrument(
name = "span_func", // имя span
level = "info", // уровень логирования
fields(attr1 = %param1, attr2="xxx"), // дополнительные атрибуты
skip(param1), // не включать аргумент param1 в атрибуты
ret // включить автоматическое логирование результата функции
)]
fn func(param1: i32, param2: &str) -> String {
tracing::info!("Hello");
String::from("RESULT")
}Вывод программы:
INFO span_func{param2="PARAM2" attr1=1 attr2="xxx"}: test_rust: Hello
INFO span_func{param2="PARAM2" attr1=1 attr2="xxx"}: test_rust: return="RESULT"
Внутреннее устройство span
При активации объекта span, его данные помещаются в thread local, что позволяет сохранять доступ к объекту span даже во вложенных функциях.
Например:
fn main() {
tracing_subscriber::fmt().init();
let span = tracing::span!(tracing::Level::INFO, "span1", attr1 = 5);
let _entered = span.enter();
func();
}
fn func() {
tracing::info!("Hello");
}Вывод программы:
2025-12-18T00:58:56.030620Z INFO span1{attr1=5}: test_rust: Hello
Как видите, атрибуты из span попали в лог вывод из функции.
Warning
При написании async кода, span может работать некорректно, если в области действия активного span объекта, вставить вызов
await. Но об этом мы поговорим позже.
Конфигурация приложения
В этой главе мы рассмотрим, как при помощи библиотеки config считывать конфигурации приложения из текстовых файлов.
Note
В интернете вы можете встретить множество примеров конфигурации при помощи библиотеки dotenv, которая когда-то была популярна, но уже давно заброшена. У этой библиотеки был немного более свежий форк dotenvy, однако он также заброшен.
Чтение конфиг файла
Для начала добавим крэйт config в Cargo.toml:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
config = "0.15"
serde = { version = "1", features = ["derive"] }
Предположим, мы создаём бэкенд приложение, которое работает с реляционной базой данных. В конфигурационный файл мы вынесем:
- настройки подключения к БД
- порт, который будет слушать наше бэкенд приложение
В качестве формата для конфигурационного файла мы возьмём TOML, который является наиболее популярным в мире Rust. Однако библиотека config также поддерживает JSON, Yaml, INI, RON и Corn.
Итак, создадим файл config/application.toml, в который поместим конфигурации:
[db]
host = "localhost"
port = 5432
login = "postgres"
password = "1111"
[server]
listen_port = 3000
Теперь напишем программу, которая считывает этот конфигурационный файл в виде объекта структуры.
use config::{Config, File};
use serde::Deserialize;
// Корневой тип для конфигурации
#[derive(Debug, Deserialize, Clone)]
struct AppConfig {
db: DbConfig,
server: ServerConfig,
}
// Тип для полей из секции [db]
#[derive(Debug, Deserialize, Clone)]
struct DbConfig {
host: String,
port: u32,
login: String,
password: String,
}
// Тип для полей из секции [server]
#[derive(Debug, Deserialize, Clone)]
struct ServerConfig {
listen_port: u32,
}
fn main() {
// Считываем конфиг файл
let cfg = Config::builder()
.add_source(File::with_name("config/application.toml"))
.build()
.unwrap();
// Конвертируем конфигурацию в объект структуры
let app_config: AppConfig = cfg.try_deserialize().unwrap();
println!("{app_config:?}");
}Вывод программы:
AppConfig {
db: DbConfig { host: "localhost", port: 5432, login: "postgres", password: "1111" },
server: ServerConfig { listen_port: 3000 }
}
Как видите, для создания объекта структуры из конфигурации библиотека config опирается на крэйт serde, поэтому все возможности serde также доступны и для десериализации конфига.
Многослойный конфиг
Если вы разрабатываете бэкенд приложение, то, скорее всего, у вас будет несколько конфигураций для запуска на разных окружениях (environment), таких как:
- локальный компьютер разработчика
- продакшен
- пре-продакшен
- и т.д.
При этом какая-то часть конфигурации у вас будет одинаковая для всех окружений, а какая-то часть будет специфична для каждого окружения. Например, слушать порт 8080 сервер будет на всех окружениях, а настройки подключения к БД везде будут разными.
Для таких ситуаций удобно разбивать конфигурацию на минимум два слоя:
- Первый слой представлен одним файлом (назовём его
default.toml) и содержит значения параметров по умолчанию. - Второй — специфичен для окружения (
prod.toml,stg.tomlи т.д.) и хранит только значения, которые отличаются от тех, что заданы вdefault.toml.
Расширим наш предыдущий пример. Вместо одного файла application.toml у нас будет
- файл с конфигурациями по умолчанию —
default.toml - конфигурация для окружения разработчика —
dev.toml - конфигурация для продакшена —
prod.toml.
Файл config/default.toml:
[db]
host = "localhost"
port = 5432
login = "postgres"
password = "1111"
[server]
listen_port = 3000
Файл config/dev.toml:
[db]
host = "dev-db.my.com"
port = 5432
login = "postgres"
password = "1111"
Файл config/prod.toml:
[db]
host = "prod-db.my.com"
port = 5432
login = "prod_user"
password = "prod_passwd"
[server]
listen_port = 8080
Теперь main.rs. В нашем примере мы рассчитываем, что название окружения будет передаваться через переменную окружения PROFILE.
use config::{Config, File};
use serde::Deserialize;
#[derive(Debug, Deserialize, Clone)]
struct AppConfig { db: DbConfig, server: ServerConfig }
#[derive(Debug, Deserialize, Clone)]
struct DbConfig { host: String, port: u32, login: String, password: String }
#[derive(Debug, Deserialize, Clone)]
struct ServerConfig { listen_port: u32 }
fn main() {
// Получаем имя окружения
let profile = std::env::var("PROFILE").unwrap_or_else(|_| "dev".into());
// Загружаем сначала значения из default.toml, а потом из файла соответствующего
// окружению. При этом значения с совпадающими именами будут перезатираться.
let cfg = Config::builder()
.add_source(File::with_name("config/default.toml"))
.add_source(File::with_name(&format!("config/{profile}.toml")))
.build()
.unwrap();
let app_config: AppConfig = cfg.try_deserialize().unwrap();
println!("{app_config:?}");
}Вывод программы:
$ export PROFILE=dev
$ cargo run
AppConfig {
db: DbConfig { host: "dev-db.my.com", port: 5432, login: "postgres", password: "1111" },
server: ServerConfig { listen_port: 3000 }
}
Перезапись переменными окружения
Иногда удобно иметь возможность перезаписать значение какого-то параметра без изменения конфигурационного файла, а при помощи переменной окружения.
В примере ниже мы добавляем возможность перезаписывать значения параметров конфигурации при помощи переменных окружения с префиксом “APP__”.
fn main() {
let profile = std::env::var("PROFILE").unwrap_or_else(|_| "dev".into());
let cfg = Config::builder()
.add_source(File::with_name("config/default.toml"))
.add_source(File::with_name(&format!("config/{profile}.toml")))
.add_source( // перезапись
config::Environment::with_prefix("app").separator("__")
)
.build()
.unwrap();
let app_config: AppConfig = cfg.try_deserialize().unwrap();
println!("{app_config:?}");
}Например, если мы хотим перезаписать значение параметра host из секции [db], то мы сможем сделать это при помощи переменной окружения с именем APP__db__host.
Запуск программы:
$ export APP__db__host=XXX
$ cargo run
AppConfig {
db: DbConfig { host: "XXX", port: 5432, login: "postgres", password: "1111" },
server: ServerConfig { listen_port: 3000 }
}
Потоки и ввод/вывод
Конкурентность и параллелизм
Перед тем как погружаться в тему асинхронности в Rust, нам надо немного остановиться на терминологии. В английском языке есть два понятия: parallelism и concurrency.
Parallelism однозначно переводится на русский язык как “параллелизм”, и в контексте программирования означает одновременное выполнение кода на разных процессорах или разных ядрах одного процессора.
С concurrency дела обстоят сложнее. Наиболее близкий аналог этого понятия в русском языке — “конкурентность”. Когда говорят, что код — конкурентный, то имеют в виду, что код написан таким образом, что он рассчитан на параллельное исполнение.
Например, если мы запустим многопоточную программу на процессоре, у которого есть только одно ядро, то все потоки будут выполняться по очереди и реального параллелизма не будет. Однако при этом всё равно возможны все те проблемы, которые могут случиться при настоящем параллельном исполнении. Например, гонка за данные (data race) возможна даже при исполнении на одноядерном процессоре.
Можно сказать, что когда мы говорим о конкурентности, то речь идёт о логическом уровне параллельного исполнения, а когда мы говорим о параллелизме, подразумеваем физический уровень.
Асинхронные рантаймы, о которых пойдёт речь в этой главе, исполняют код конкурентно, но не обязательно параллельно. При этом, как мы уже сказали, требования к коду выдвигаются такие, словно он исполняется параллельно на физическом уровне.
Проблемы потоков
Как мы знаем, бекенд приложения обслуживают множество запросов. Чтобы приложение работало отзывчиво, необходимо, чтобы поступающие запросы обрабатывались параллельно, а не ожидали обработки друг друга. Самый простой способ достичь этого — обрабатывать каждый запрос в отдельном потоке. Однако большое количество запущенных потоков в совокупности с большим количеством операций ввода/вывода (а в бекенд приложениях, как правило, много ввода/вывода) могут стать серьезной проблемой для производительности приложения.
Дело в том, что ОС потоки являются дорогостоящим ресурсом:
- создание нового потока осуществляется системным вызовом, а это долго
- переключение между ОС потоками — длительная и дорогостоящая операция
Почему системный вызов — это долго?
Системные вызовы (system call) — механизм, при помощи которого программа, работающая в пользовательском пространстве (user space), может вызывать функциональность из ядра операционной системы.
Системные вызовы работают немного по-разному в зависимости от операционной системы и архитектуры процессора, но общий принцип везде одинаковый.
Например, для операционной системы Linux и архитектуры x86-64, системный вызов, который создаёт новый поток, состоит из следующих шагов:
- Программа записывает номер желаемого системного вызова в регистр RAX
(все доступные системные вызовы вместе с их номерами и описанием аргументов можно найти в документации Linux)- Аргументы системного вызова передаются в соответствии с их порядком через регистры RDI, RSI, RDX, R10, R8 и R9.
- Адрес возврата из системного вызова помещается в регистр RCX.
- Далее программа вызывает инструкцию
syscall, которая стартует системный вызов. В 32-разрядном поколении Linux для старта системного вызова использовалось прерывание с номером 60. Оно работает и сейчас, однако использование инструкцииsyscallпредпочтительнее.- После вызова
syscallпоток “засыпает” и происходит переключение в режим ядра. В режиме ядра процессор имеет доступ к памяти ядра и может обращаться к оборудованию. Для запуска нового потока в ядре в таблице потоков будет создана новая запись, а также будет выделено место для стека нового потока.- После того как работа в режиме ядра закончена, процессор (ядро процессора) переключается в пользовательский режим и продолжает исполнение ранее уснувшего потока.
Все эти операции переключения контекста между пользовательским пространством и ядром весьма затратны по времени и могут негативно сказаться на производительности программы.
Почему переключение между потоками — это долго?
Исполнением потоков на ядрах процессора заведует планировщик — подпрограмма в ядре операционной системы. Планировщик решает, в какой последовательности и как долго потоки будут исполняться на ядрах процессора.
После того как поток исчерпал свой квант времени (отпущенное для исполнения время), он прерывается, а его состояние (значение регистров) записывается в стек потока. В таблице потоков в ядре обновляется запись о состоянии остановленного потока. Далее для следующего в очереди на исполнение потока восстанавливается его состояние из стека, и этот поток начинает исполняться.
Вся эта последовательность происходит далеко не мгновенно, а занимает немало процессорного времени: примерно одна микросекунда на современном процессоре и операционной системе Linux.
Таким образом, если у нас 10 потоков и каждый из них в течение одной секунды должен хотя бы раз получить свой квант времени, то процессор потратит 10 микросекунд на переключения контекстов между потоками и 999990 микросекунд на исполнение потоков. То есть 0.001% всего процессорного времени будет потрачено на переключения.
Однако если у нас будет 10000 потоков, то процессор уже потратит 10000 микросекунд только на переключения и 990000 микросекунд на исполнение. А это значит, что уже 1% всего процессорного времени было потрачено только на одни лишь переключения.
Ситуация омрачается тем, что процессор старается, чтобы каждый поток получал квант времени чаще, чем один раз в секунду, а это значит, что переключений может быть (и будет) гораздо больше.
Таким образом, если у нас в программе мало потоков, которые занимаются в основном вычислениями, то нам вполне подойдут ОС потоки. Однако если у нас очень много потоков и много операций ввода/вывода, то существенная доля всего времени работы процессора будет уходить просто на переключение между этими потоками. Очевидно, что удар по производительности будет существенный.
Блокирующий и неблокирующий ввод/вывод
Бекенд приложения, как правило, являются приложениями с большим количеством операций ввода/вывода: работа с HTTP соединениями, работа с файловой системой, работа с БД, внешними очередями, распределёнными кешами и т.д. С точки зрения работы с потоками, существует два типа операций ввода/вывода: блокирующие и неблокирующие.
Блокирующие операции ввода/вывода работают следующим образом:
- Поток делает системный вызов, запрашивающий блокирующую операцию ввода/вывода (например, чтение байт из открытого сетевого соединения).
- После этого поток “засыпает” и отмечается в таблице потоков как ожидающий пробуждения после выполнения операции ввода/вывода.
- В какой-то момент ядро осуществляет непосредственное чтение данных из устройства и помещает их в буфер для чтения программой.
- В таблице потоков обновляется запись для потока, ожидавшего эту операцию чтения. Теперь поток готов к продолжению своей работы.
- Планировщик выдаёт квант времени потоку, когда наступит его очередь.
- Поток пробуждается и читает данные, уже находящиеся в буфере.
Блокирующие операции ввода/вывода удобны в использовании, однако при написании бекенд приложений, обслуживающих большое количество одновременных запросов, использование блокирующих операций ввода/вывода приводит к множественным переключениям между потоками, что сильно бьёт по производительности.
Работа с неблокирующим вводом/выводом осуществляется немного по-другому. Для начала надо заметить, что неблокирующий API практически бесполезен для работы с одним устройством ввода/вывода, например, только одним сетевым сокетом.
(Имеется ввиду не обязательно физическое устройство: например, на одной сетевой карте, сетевых сокетов может быть открыто несколько десятков тысяч).
Итак, рассмотрим в общих чертах, как происходит работа с неблокирующим вводом/выводом на примере epoll. epoll — это API для работы с неблокирующим вводом/выводом в операционной системе Linux. В зависимости от того, с какой операционной системой мы работаем, неблокирующее API будет разным: для Linux это может быть select, poll, epoll, io_uring, для Windows — IOCP, для BSD/MacOS — kqueue и т.д.
Допустим, мы делаем эхо-сервер, который принимает сетевое соединение, считывает из него байты и отправляет эти же байты обратно.
- Мы получаем несколько соединений от клиентов, и каждое из соединений представлено сетевым сокетом. Вместо того чтобы для каждого сокета сразу читать входные данные, мы просто берём дескрипторы этих сокетов и складываем их в массив.
- Все дескрипторы одним массивом передаём в соответствующий системный вызов (epoll_wait) с указанием того, какие события мы ожидаем для этих сокетов. В нашем случае это будет событие, означающее, что данные из сокета готовы к прочтению.
- Системный вызов epoll_wait блокирует вызвавший его поток, а по пробуждении возвращает список дескрипторов, для которых данные готовы к чтению.
- Мы итерируемся по списку готовых дескрипторов (полученных от epoll_wait) и для каждого из них сначала считываем все имеющиеся байты, а потом сразу пишем их в сокет обратно. После — закрываем сокет.
- Далее мы снова вызываем системный вызов epoll_wait для оставшихся дескрипторов. И так, пока не будут обработаны все из них.

Пример epoll
Для тех, кто никогда не видел работу с неблокирующим API, приведём пример на C: TCP эхо-сервер с использованием механизма epoll под ОС Linux. Вся обработка ошибок опущена для краткости кода.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/epoll.h>
#define MAX_EVENTS 10
int main(void) {
int listen_fd = socket(AF_INET, SOCK_STREAM, 0); // Создаём серверный сокет
int options = 1; // Разрешаем переиспользование адреса
setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &options, sizeof(options));
// Привязывает сокет к 8081 порту и начинаем слушать
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = INADDR_ANY;
addr.sin_port = htons(8081);
bind(listen_fd, (struct sockaddr *)&addr, sizeof(addr));
listen(listen_fd, SOMAXCONN);
// Создаём мультиплексор неблокируюшего ввода/вывода epoll
int epoll_fd = epoll_create1(0);
// Добавляем серверный сокет в epoll
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, listen_fd, &ev);
// В цикле ждём пояления дискриптора готового к работе
while (1) {
struct epoll_event events[MAX_EVENTS];
// Ожидаем появления готовых дескрипторов ввода/вывода
int ready_num = epoll_wait(epoll_fd, events, MAX_EVENTS, -1);
// Итерируемся по всем готовым к обработке дескрипторам
for (int i = 0; i < ready_num; i++) {
if (events[i].data.fd == listen_fd) {
// Если готовый дескриптор - наш серверный сокет,
// значит поступило новое сетевое соединение.
// Принимаем его и добавляем новое соединение в epoll
struct sockaddr_in client_addr;
socklen_t client_len = sizeof(client_addr);
int conn_fd = accept(listen_fd, (struct sockaddr *)&client_addr, &client_len);
printf("New: %s:%d\n", inet_ntoa(client_addr.sin_addr), ntohs(client_addr.sin_port));
ev.events = EPOLLIN;
ev.data.fd = conn_fd;
epoll_ctl(epoll_fd, EPOLL_CTL_ADD, conn_fd, &ev);
} else {
// Иначе, это ввод/вывод от клиента
int client_fd = events[i].data.fd;
char buf[1024];
ssize_t read_bytes = read(client_fd, buf, sizeof(buf));
if (read_bytes <= 0) {
// Если от клиента считано всё, то закрываем
// соединение и удаляем его дескриптор из epoll
close(client_fd);
epoll_ctl(epoll_fd, EPOLL_CTL_DEL, client_fd, NULL);
} else {
// Иначе сразу пишем считанные байты обратно клиенту
write(client_fd, buf, read_bytes);
}
}
}
}
close(listen_fd);
close(epoll_fd);
return 0;
}
Как видите, вся работа выстроена вокруг бесконечного цикла ожидания готовых дескрипторов при помощи вызова epoll_wait, что не позволяет писать простой линейный код.
Сделаем акцент:
- С блокирующим API каждый сокет обрабатывается отдельным потоком, и этот поток засыпает на каждом блокирующем вызове чтения или записи
- С неблокирующим API мы одним потоком итеративно работаем сразу с пачкой сокетов, и этот один поток засыпает, пока хотя бы один сокет из всей пачки не будет готов к дальнейшей работе.
Однако на лицо существенный минус: если блокирующий API позволяет писать код в простом и понятном линейном стиле, то с неблокирующим API необходим некий подход для связывания воедино линейной бизнес логики программы, и централизованной работы с вводом/выводом.
Таких подходов несколько.
Работа с неблокирующим API
Существует несколько стандартных архитектурных подходов по отделению цикла опроса событий ввода/вывода от логики программы.
- Цикл событий и функции обратного вызова (Event loop and callbacks)
- Модель акторов
- Файберы
Рассмотрим каждый из них подробнее.
Цикл событий и функции обратного вызова
Если вам приходилось писать на JavaScript до того, как в нём появился Promise, то вы хорошо помните, что результаты всех операций ввода/вывода обрабатывались при помощи функций обратного вызова (callback).
Note
При этом HTTP запрос осуществлялся следующим образом:
// создаём объект HTTP запроса const xhttp = new XMLHttpRequest(); // В поле onreadystatechange присваиваем xhttp.onreadystatechange = function() { // функция обратного вызова if (this.readyState == 4 && this.status == 200) { console.log(this.responseText); } }; xhttp.open("GET", "http://somehost/some_resource"); xhttp.send();
Идея следующая:
Мы запускаем бесконечный цикл, который принимает “заявки” на операции ввода/вывода. Обычно для доставки заявок в цикл используется очередь. Каждая такая “заявка” содержит информацию о самой операции ввода/вывода, которую необходимо выполнить, а также функцию обратного вызова, которую следует вызвать по окончании операции ввода/вывода.
Таким образом, поток, выполняющий логику программы, просто отправляет заявку, например, на выполнение HTTP запроса и прикрепляет к ней колбэк, содержащий код, которым следует обработать результат HTTP запроса. При этом после отправки заявки поток не блокируется, а продолжает заниматься другими задачами.
Далее заявка будет извлечена из очереди циклом обработки ввода/вывода, который:
- откроет сетевое соединение
- добавит дескриптор сетевого соединения в список дескрипторов, для которых ожидается сигнал о готовности к непосредственной записи
- дождётся готовности сетевого соединения к записи
- выполнит запись HTTP запроса
- дождётся готовности сетевого соединения к чтению ответа
- прочитает ответ
- закроет сетевое соединение
- вызовет функцию обратного вызова, передав в неё ответ на HTTP запрос

Плюс такого подхода — простота реализации. Никакие специальные языковые конструкции не требуются: во всех мейнстримных языках есть как очереди, так и возможность передавать функции как аргументы.
Очевидный недостаток: если логика программы подразумевает серию последовательных операций ввода/вывода, то код превратится в “лесенку” из колбеков.
#![allow(unused)]
fn main() {
http_call("http://xxx/service_1", |response| {
// do something with response
http_call("http://xxx/service_2", |response| {
// do something with response
http_call("http://xxx/service_3", |response| {
// do something with response
});
});
});
}Note
Следует сказать об одной разновидности подхода, основанного на цикле событий — реактивном программировании.
Фрэймворки для реактивного программирования также строятся вокруг цикла событий, однако предоставляют API, который позволяет писать “функции обратного вызова” таким образом, что визуально код выглядит относительно линейно. Это позволяет решить проблему “ада из колбэков”, которая возникает при использовании “классического” цикла событий с функциями обратного вызова.
Реактивное программирование обрело популярность в языке Java, где проблема конкурентности стала так же остро, как и в других языках, но при этом в Java не стали добавлять в язык async-await механизм, что вынудило разработчиков искать альтернативные подходы. Однако, начиная с Java 21, в язык были добавлены виртуальные потоки, благодаря которым надобность в реактивном подходе заметно снизилась.
Модель акторов
Другим распространенным способом интеграции событийного цикла (event loop) с бизнес-логикой приложения является модель акторов.
Строго говоря, модель акторов не создавалась для решения проблемы неблокирующего ввода/вывода. Модель акторов предлагает альтернативный подход к написанию многопоточных систем, а также предоставляет механизм, который облегчает создание приложений, работающих на сетевом кластере. Однако принцип взаимодействия компонентов в программах, построенных на модели акторов, позволяет относительно просто вынести цикл работы с неблокирующим вводом/выводом в отдельный компонент, с которым легко взаимодействовать.
Идея модели акторов заключается в том, что программа представляется в виде набора акторов, обслуживаемых системой акторов. Каждый актор состоит из:
- “Почтового ящика” (mailbox) — очереди, в которую поступают сообщения, адресованные актору. Акторы не вызывают друг друга как функции, а отправляют друг другу сообщения.
- Функции-актора, которая используется для обработки очередного сообщения из почтового ящика
- Акторы могут иметь внутреннее состояние (поля), которое может меняться в процессе работы актора.
Система акторов — фреймворк, который отвечает за доставку сообщений в почтовые ящики, а также за периодическое исполнение функции актора на одном из ОС потоков.
При такой архитектуре можно инкапсулировать всю логику работы с неблокирующим вводом/выводом в отдельный I/O актор. И тогда:
- Акторы, желающие выполнить операцию ввода/вывода, будут отправлять соответствующие сообщения I/O актору
- I/O актор будет извлекать запросы на операции ввода/вывода из почтового ящика и обрабатывать их при помощи epoll или другого неблокирующего API. Результаты операций ввода/вывода будут отправляться сообщениями обратно тем акторам, которые прислали запрос на операцию ввода/вывода.
Проиллюстрируем на диаграмме, как может выглядеть простое бэкенд приложение, построенное на системе акторов. Два основных актора, которые нас интересуют:
- I/O актор, занимающийся обслуживанием операций ввода/вывода
- Некий актор, который получает запросы от пользователей и, чтобы ответить на них, вызывает другой бэкенд сервис по HTTP. Работа с HTTP осуществляется посредством I/O актора.

Модель акторов очень хороша для приложений, чья логика укладывается в рамки асинхронного обмена сообщениями. Например, Erlang/OTP зарекомендовал себя как платформа с отличной масштабируемостью и отказоустойчивостью (например, бекенд популярного мессенджера WhatsApp сделан на нём). Однако для написания программ с линейной логикой модель акторов, скорее всего, окажется неудобной.
Файберы
Данная модель является наиболее гибкой и современной, и может встречаться под разными названиями: корутины (coroutines), зелёные потоки (green threads), волокна (fibers), потоки пользовательского пространства (user space threads).
Идея следующая: если создавать ОС потоки — дорого, а переключаться между ними — долго, то мы создадим в нашей программе свой планировщик и свои легковесные потоки пользовательского пространства. Далее мы будем называть легковесные потоки файберами. Разумеется, запускать наши файберы мы будем поверх ОС потоков, но поскольку создаваться и переключаться файберы будут нашим же планировщиком в пользовательском пространстве, мы сможем избежать долгих и дорогостоящих переключений контекста ОС потоков.
Файбер может быть реализован разными способами, но он должен позволять приостанавливать его работу в определённых местах, а также продолжать работу с приостановленного места.
Tip
Как можно построить простейший файбер?
Если вы никогда не имели дело с потоками пользовательского пространства, то, возможно, вам тяжело представить себе, как можно сделать свой поток и, к тому же, иметь возможность его останавливать.
Самый простой файбер можно реализовать как массив/вектор из замыканий так, чтобы результат одного замыкания становился входным аргументом для последующего за ним замыкания:
[()->A, A->B, B->C].Рассмотрим пример простейшего файбера, построенного из объектов
Fn(T)->R.use std::{any::Any, collections::VecDeque, marker::PhantomData}; // Абстракция для элемента файбера. Нужен чтобы абстрагироваться от // конкретных типов в замыкании Fn(T)->R. // Это позволит хранить в векторе замыкания разных типов. // Например: [Fn(String)->i32, Fn(i32)->bool] trait Stage { fn exec(&self, arg: Box<dyn Any>) -> Box<dyn Any>; } // Обёртка над замыканием Fn(T)->R struct Func<T: 'static, R: 'static>(Box<dyn Fn(T) -> R>); // Файбер, сделанный как цепочка из замыканий, абстрагированных через Stage. // Сама цепочка ведёт себя как замыкание Fn(())->R, где () - тип аргумента // первого замыкания в цепочке, а R - тип результата последнего. // Т.е [()->String, String->i32, i32->bool] сводится к ()->bool struct Fiber<R> { // цепочка замыканий, из которых состоит файбер stages: VecDeque<Box<dyn Stage>>, // результирующий тип всего файбера result_type: PhantomData<R>, } impl<R: 'static> Fiber<R> { // Создаёт файбер из замыкания pub fn from(f: impl Fn(()) -> R + 'static) -> Fiber<R> { let func = Func(Box::new(f)); let stage: Box<dyn Stage> = Box::new(func); let mut stages = VecDeque::new(); stages.push_back(stage); Fiber { stages, result_type: PhantomData::<R>, } } // Добавляет в конец файбера еще одно замыкание pub fn compose<R2: 'static>(self, f: impl Fn(R) -> R2 + 'static) -> Fiber<R2> { let func = Func(Box::new(f)); let mut stages = self.stages; stages.push_back(Box::new(func)); Fiber { stages, result_type: PhantomData::<R2>, } } // Выполняет весь файбер pub fn run(mut self) -> R { let mut arg: Box<dyn Any> = Box::new(()); while let Some(stage) = self.stages.pop_front() { arg = stage.exec(arg); } *arg.downcast().unwrap() } } impl<T: 'static, R: 'static> Stage for Func<T, R> { // Выполняет замыкание, представляющее из себя звено файбера fn exec(&self, arg: Box<dyn Any>) -> Box<dyn Any> { let t: T = *arg.downcast().unwrap(); let r = self.0.as_ref()(t); Box::new(r) } } fn main() { let fiber = Fiber::from(|()| 1) .compose(|a| a + 1) .compose(|a| a * 2) .compose(|a| format!("result: {a}")); println!("{}", fiber.run()) // result: 4 }Наибольший интерес здесь для нас представляет метод
Fiber::run. В нём замыкания, из которых состоит файбер, выполняются одно за другим. Именно в промежутках между вызовами этих замыканий мы и можем “приостанавливать” работу файбера.Например:
// Выполнение файбера будет возвращать результат своей работы, // завёрнутым в это перечисление enum RunResult<T: 'static> { struct Suspended { // файбер приостановлен arg: Any, fiber: Fiber<T> }, Finish(T), // файбер закончил свою работу } ... pub fn run(mut self) -> RunResult<R> { let mut arg: Box<dyn Any> = Box::new(()); while let Some(stage) = self.stages.pop_front() { arg = stage.exec(arg); if условие остановки выполнения файбера { return RunResult::Suspended { arg, fiber: self}; } } RunResult::Finish(*arg.downcast().unwrap()) }Таким образом, при исполнении файбера мы можем проверять некое условие, и если надо, останавливать работу файбера, возвращая оставшуюся часть цепочки замыканий, которая не была исполнена. Имея эту оставшуюся часть цепочки и промежуточное значение, на котором было остановлено исполнение файбера, всегда можно продолжить выполнять файбер дальше.
Типичный планировщик файберов, как правило, имеет в своём распоряжении два пула потоков операционной системы:
- потоки для выполнения самих файберов
- поток для выполнения операций ввода/вывода (I/O поток), инициированных файберами
Имея такой планировщик специально для наших файберов, мы можем реализовать свой API операций ввода/вывода, который будет работать так:
- В файбере X вызывается операция ввода/вывода.
- Планировщик снимает этот файбер с выполнения на ОС потоке и отправляет в очередь ожидания. После этого достаёт из очереди ожидания другой, готовый к исполнению, файбер и возобновляет его исполнение на ОС потоке.
- Запрос на операцию ввода/вывода отправляется специально выделенному для I/O потоку, который в цикле занимается обслуживанием запросов ввода/вывода при помощи epoll или другого API.
- Когда выделенный I/O поток завершает операцию ввода/вывода, поступившую от файбера X, он сохраняет её результат для этого файбера и помечает сам файбер как готовый к продолжению работы.
- В какой-то момент планировщик файберов возобновляет работу файбера X на ОС потоке. К этому моменту файберу уже будет доступен результат операции ввода/вывода.

Именно о файберах / корутинах речь пойдёт дальше в этом разделе.
Асинхронность в Rust
Когда дело касается реализации потоков пользовательского пространства, необходимо решить две задачи:
- Как реализовать файберы так, чтобы с ними было удобно работать?
- Как спроектировать экзекьютор/планировщик для файберов так, чтобы он был и гибким, и производительным?
Rust предлагает довольно элегантное решение: язык и стандартная библиотека задают максимально гибкий интерфейс для асинхронных функций (которые по сути являются файберами), а реализация экзекьюторов для их исполнения отдаётся на откуп сторонним разработчикам. Таким образом получается, что мы имеем единый интерфейс для написания файберов, при этом можем выбирать тот или другой рантайм в зависимости от специфики нашего приложения.
Note
В документации по потокам пользовательского пространства часто встречаются названия: “экзекьютор” (executor) и “асинхронный рантайм” (async runtime).
Иногда они означают одно и то же, но асинхронный рантайм — более широкое понятие, которое включает в себя экзекьютор только как один из элементов (пусть и самый главный).
Асинхронные функции
Объявляя функцию с ключевым словом async, мы указываем, что эта функция является асинхронной и должна быть исполнена конкурентно на неком рантайме.
async fn имя_функции(аргументы) -> ТипРезультата {
...
}Например:
async fn get_1() -> i32 {
1
}Вызов асинхронной функции возвращает не её значение, а объект файбера. Например, вызов вышеобъявленной async функции get_1() создаёт объект файбера, который при вычислении возвращает 1.
fn main() {
let my_fiber = get_1();
}Далее, чтобы получить результат этого файбера, нам надо исполнить файбер на неком рантайме/экзекьюторе.
Note
Читая документацию по async-функциям или асинхронным рантайм, вы вряд ли встретите слово “файбер” (fiber). Скорее всего, вы будете встречать названия “async function” или “future”. Первое используется по понятной причине: из-за ключевого слова
async. Второе же используется из-за трэйта, который лежит в основе асинхронного исполнения в Rust, но об этом позже.
В любом случае, и “async function”, и “future” в данном контексте являются синонимами файберов.
Исполнение async-функции
Стандартная библиотека Rust предоставляет функциональность для создания файберов, однако не содержит никакой реализации экзекьютора для их исполнения.
Экосистема Rust предлагает несколько высокопроизводительных асинхронных экзекьюторов, но на данный момент мы воспользуемся самым примитивным экзекьютором из библиотеки futures.
Для начала добавим futures в Cargo.toml:
[package]
name = "test_rust_async"
version = "0.1.0"
edition = "2024"
[dependencies]
futures = "0.3"
Теперь src/main.rs:
use futures::executor::block_on;
async fn get_1() -> i32 {
1
}
fn main() {
let my_fiber = get_1();
let result = block_on(my_fiber);
println!("{}", result);
}Функция block_on принимает файбер в качестве аргумента и исполняет его на экзекьюторе. Этот экзекьютор просто использует текущий поток для того, чтобы исполнить файбер: он не имеет умного планировщика и сложной системы пулов потоков. При этом этот простой экзекьютор является отличной демонстрацией того, что экзекьюторы могут быть устроены очень по-разному.
Мы рассмотрим более сложные экзекьюторы далее.
Композиция асинхронных функций
Мы уже знаем, что вызов асинхронной функции порождает файбер. Но что делать, если файбер должен состоять из последовательности вызовов async-функций?
Например, у нас есть две async-функции:
async fn load_number() -> i32 {
1
}
async fn transform_number(a: i32) -> i32 {
a + 1
}и мы хотим получить файбер, который сначала получает число вызовом load_number, а потом преобразует его при помощи transform_number.
Для композиции вызовов асинхронных функций в Rust используется подход async/await, с которым вы уже могли встречаться в таких языках, как Javascript, C#, Python, Swift.
async fn my_flow() -> i32 {
let number = load_number().await;
let transformed = transform_number(number).await;
transformed
}Здесь мы создаём третью async-функцию, которая объединяет в себе вызовы других async-функций. Теперь вызов функции my_flow вернёт экземпляр файбера, который в качестве своих составляющих содержит под-файберы, порождённые вызовами load_number и transform_number.
Важно отметить, что вызов await можно совершать только в теле async-функции.
Tip
Если вы встречали оператор
awaitв других языках программирования, то могли заметить, что тамawaitставится перед вызовом функции, в то время как в Rust — после. Так было сделано для того, чтобы было удобнее увязывать вызовы async-функций в цепочки:get_value().await .call_method_1().await .call_method_2().await
А теперь самое главное: помните, мы говорили, что файбер содержит в себе места, в которых экзекьютор может приостановить выполнение файбера? Вызовы .await как раз являются теми самыми местами. Именно на них экзекьютор может отправлять файбер в очередь ожидания, перекидывать на другой ОС поток и т.д.
То, как работает await внутри, станет понятнее, когда мы разберёмся с внутренним устройством файбера, а пока что давайте взглянем на еще один пример, который приближен к реалиям написания бэкендов.
Допустим, у нас есть два отдельных сервиса: один отвечает за хранение пользователей, а другой — за хранение адресов. Мы хотим написать фукциональность, которая возвращает информацию о пользователе и его адресе.
// Информация о пользователей
struct User { user_id: u64, name: String, addr_id: u64 }
// Информация об адресе
struct Address { addr_id: u64, location: String }
// Информация о пользователе и адресе.
struct UserInfo { user: User, addr: Address }
// Сервис, который возвращает пользователя по его ID
async fn get_user_by_id(user_id: u64) -> User {
// делает запрос к некому user сервису
}
// Сервис, который возвращает адрес по ID записи адреса
async fn get_address_by_id(addr_id: u64) -> Address {
// делает запрос к некому address сервису
}
async fn get_user_with_address(user_id: u64) -> UserInfo {
let user: User = get_user_by_id(user_id).await;
let addr: Address = get_address_by_id(user.addr_id).await;
UserInfo { user, addr }
}Tip
Java программистам на заметку
Чтобы понять, насколько красива композиция через async/await, давайте рассмотрим, как выглядела бы подобная композиция функций, если бы она была основана на CompletableFuture:
CompletableFuture<User> fetchUserById(Long userId) { ... } CompletableFuture<Address> fetchAddressById(Long addrId) { … } CompletableFuture<UserInfo> getUserInfo(Long userId) { return fetchUserById(userId) .thenCompose(user -> fetchAddressById(user.getAddrId()) .thenApply(addr -> new UserInfo(user, addr) ) ); }Согласитесь, что читать код с async-await заметно проще.
async-замыкания
Фьючер можно создавать не только вызовом async-функции, но и при помощи async-замыкания.
let closure = async || { тело };
let fiber = closure();Например:
fn main() {
let closure = async|| { 1 };
let my_fiber = closure();
let result = futures::executor::block_on(my_fiber);
println!("{}", result); // 1
}Также существуют async-блоки. Они подобны обычному скоупу (блок кода в фигурных скобках), только возвращают не значение, а фьючер.
let fiber = async { тело };Например:
fn main() {
let my_fiber = async { 1 };
let result = futures::executor::block_on(my_fiber);
println!("{}", result); // 1
}Анатомия файберов — Future
Давайте теперь разберёмся, как файберы устроены внутри.
Если в вашем редакторе кода имеется поддержка Rust LSP, благодаря чему отображаются выведенные типы, то скорее всего пример из секции Исполнение async-функции у вас в редакторе выглядит так:
use futures::executor::block_on;
async fn get_1() -> i32 {
1
}
fn main() {
let my_fiber: impl Future<Output = i32> = get_1();
// ^^^^^^^^^^^^^^^^^^^^^^^^
let result: i32 = block_on(my_fiber);
println!("{}", result);
}Как видите, тип файбера — это нечто, реализующее трэйт Future. А трэйт Future, в свою очередь, является основным интерфейсом для файберов.
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}Да, все файберы в Rust должны реализовать именно этот генерик трэйт, который содержит всего один метод. Давайте разбираться с ним.
С ассоциированным типом Output всё просто: это тип результата работы всего фьючера (файбера).
Метод poll используется экзекьютором для того, чтобы получить значение файбера. Этот метод возвращает обёртку-перечисление Poll:
pub enum Poll<T> {
Ready(T),
Pending,
}Ready(результат фьючера) символизирует, что фьючер закончил свою работу, а Pending указывает на то, что фьючер еще не готов предоставить результат своей работы.
Аргумент типа Context метода poll используется для того, чтобы передать во фьючер ссылку на объект типа Waker. А Waker, в свою очередь, используется фьючером, чтобы сигнализировать своему экзекьютору о том, что он (фьючер) завершил работу.
Вот как это работает:
Когда экзекьютор вызовом poll запрашивает значение фьючера, он передаёт (через аргумент Context) ссылку на Waker. Если значение фьючера уже готово (или может быть быстро посчитано прямо в рамках вызова poll), то значение сразу возвращается завёрнутым в Poll::Ready. Если же значение не может быть вычислено сразу (т.е. poll вернёт Poll::Pending), то фьючер сохраняет себе ссылку на Waker. Позже, когда фьючер завершит свою работу, он использует вызов Waker::wake(), чтобы сигнализировать экзекьютору о том, что можно повторно вызвать poll и получить результат.
Предполагается, что на свежепоступившем объекте фьючера экзекьютор сам вызывает poll только один раз. И если фьючер вернул Poll::Pending, то экзекьютор помещает фьючер в очередь для “еще исполняющихся” и не трогает его, пока не поступит соответствующее оповещение от этого фьючера через Waker.
Визуализируем примерную схему взаимодействия экзекьютора и фьючеров. Здесь:
- Future 1 соответствует простой async-функции, которая не зависит от других async-функций, и не выполняет операции ввода/вывода.
- Future 2 инициирует операцию неблокирующего ввода/вывода посредством отдельного потока, который в цикле выполняет ввод/вывод с помощью epoll.

Такая реализация ввода/вывода не является каким-то требованием или стандартной функциональностью. Мы просто продемонстрировали один из возможных вариантов реализации.
Tip
Как вы могли заметить, в методе
poll, тип аргументаself—Pin<&mut Self>. Если не вдаваться в детали, то Pin — это обёртка, которая “прикалывает” (как булавка) память объекта фьючера к одному месту, и не позволяет её перемещать.
Pinпрактически не используется нигде, кроме фьючеров, и вряд ли вы столкнётесь с ним напрямую в рамках бэкенд-приложений, поэтому мы не будем заострять на нём внимание.
Пишем свой экзекютор
К этому моменту у вас уже должно было сложиться примерное представление, как в Rust работают фьючеры и по каким принципам построены экзекьюторы файберов.
Однако если вам не хватает ощущения, как это всё работает внутри, то ниже мы рассмотрим пример максимально примитивного экзекьютора, код которого, тем не менее, совсем не прост. Поэтому если вы просто перейдёте к следующей главе, то ничего важного вы не пропустите.
Итак, наш пример экзекьютора будет состоять из двух файлов:
src/my_executor.rs— модуль с реализацией экзекьютораsrc/main.rs— тестирование экзекьютора
Файл src/my_executor.rs:
use std::{
collections::HashSet, future::Future, pin::Pin,
sync::{Arc, Mutex, atomic::{AtomicBool, AtomicU64, Ordering}, mpsc},
task::{Context, Poll, Wake},
thread::{self, sleep},
time::Duration
};
// Псевдоним для "приколотого" бокса, содержащего фьючер.
// Нам придётся хранить фьючеры как объекты Pin<Box<dyn Future>>
// чтобы иметь возможность вызывать poll, который требует Pin<&mut Self>
type BoxFuture = Pin<Box<dyn Future<Output = ()> + Send + 'static>>;
// Обёртка для фьючера, сгенерированного компилятором из async-функции
struct SpawnedTask {
id: u64,
future: Mutex<Option<BoxFuture>>,
}
// Реализация фьючера, которая делает паузу (как функция thread::sleep)
// В функции main мы будем создавать такой фьючер.
pub struct Sleep {
interval: Duration,
is_ready: Arc<AtomicBool>,
}
impl Sleep {
pub fn new(interval: Duration) -> Sleep {
Sleep {
interval, is_ready: Arc::new(AtomicBool::new(false))
}
}
}
impl Future for Sleep {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
if self.is_ready.load(Ordering::SeqCst) {
return Poll::Ready(());
} else {
let waker = cx.waker().clone();
let ready_flag = self.is_ready.clone();
let interval_to_sleep = self.interval.clone();
// самая примитивная реализация - стартовать новый поток для ожидания
thread::spawn(move || {
sleep(interval_to_sleep);
ready_flag.store(true, Ordering::SeqCst);
// извещаем экзекьютор об окончании работы фьючера
waker.wake();
});
Poll::Pending
}
}
}
// Интерфейс для работы с экзекьютором
pub struct Executor {
runtime: ExecutorRuntime,
last_task_id: AtomicU64,
}
impl Executor {
pub fn new() -> Executor {
Executor {
runtime: ExecutorRuntime::new(),
last_task_id: AtomicU64::new(1),
}
}
// Используется для добавления async-функции в очередь экзекьютора
pub fn spawn<F>(&self, fut: F) where F: Future<Output = ()> + Send + 'static {
let task = Arc::new(SpawnedTask {
id: self.last_task_id.fetch_add(1, Ordering::SeqCst),
future: Mutex::new(Some(Box::pin(fut))),
});
let _ = self.runtime.task_producer.send(task);
}
// Запускает вычисление фьючеров (файберов) из очереди экзекьютора
pub fn exec_blocking(&mut self) {
self.runtime.run();
}
}
// Инкапсулирует код для непосредственного вычисление фьючеров
pub struct ExecutorRuntime {
// Sender, который выдаётся другим компонентам (Executor и Tasks),
// чтобы они могли добавлять async-функции в очередь
task_producer: mpsc::Sender<Arc<SpawnedTask>>,
// Receiver используемый рантаймом для извлечения следующей async-функции
task_queue: mpsc::Receiver<Arc<SpawnedTask>>,
// Хранилище для фьючеров, которые при первом вызове poll вернули
// Poll::Pending. Нужно, чтобы не завершить работу до того как выполнены
// все фьючеры.
task_pending: HashSet<u64>,
}
impl ExecutorRuntime {
pub fn new() -> ExecutorRuntime {
let (sender, receiver) = mpsc::channel::<Arc<SpawnedTask>>();
ExecutorRuntime {
task_producer: sender,
task_queue: receiver,
task_pending: HashSet::new(),
}
}
// Запуск исполнения фьючеров
pub fn run(&mut self) {
loop {
match self.task_queue.recv_timeout(Duration::from_secs(1)) {
Ok(task) => self.process_task(task),
Err(_) =>
// Если очередь фьючеров пуста, и нет фьючеров, которые
// в процессе исполнения, тогда обработка завершается
if self.task_pending.is_empty() {
break;
},
}
}
}
fn process_task(&mut self, task: Arc<SpawnedTask>) {
let mut future_guard = task.future.lock().unwrap();
// Извлекаем объект Pin<Box<dyn Future>> из таска, потому что для
// вызова poll нужен именно объект (по значению), а не ссылка
let Some(mut fut) = future_guard.take() else {
return; // already finished
};
// Создаём Waker на случай, если фьючер не сможет выполниться сразу
// и вернёт Poll::Pending.
let spawned_task_waker = SpawnedTaskWaker {
task: task.clone(),
sender: self.task_producer.clone(),
};
let waker = Arc::new(spawned_task_waker).into();
let mut cx = Context::from_waker(&waker);
// Выполняем фьючер
let poll_result = fut.as_mut().poll(&mut cx);
match poll_result {
Poll::Pending => {
// Засовываем фьючер обратно в таск, так как этот таск придётся
// обрабатывать снова после того, как фьючер вызовет waker
*future_guard = Some(fut);
// Запоминаем, что таск с таким ID выполняется на фоне
self.task_pending.insert(task.id);
}
Poll::Ready(()) => {
// Удаляем (если надо) ID таска из списка тасков,
// выполняющихся на фоне
self.task_pending.remove(&task.id);
}
}
}
}
// Простейший Waker, который просто еще раз добавляет таск в очередь рантайма
struct SpawnedTaskWaker {
sender: mpsc::Sender<Arc<SpawnedTask>>,
task: Arc<SpawnedTask>,
}
impl Wake for SpawnedTaskWaker {
fn wake(self: Arc<Self>) {
let _ = self.sender.send(self.task.clone());
}
}Пример использования экзекьютора main.rs:
mod my_executor;
use std::time::Duration;
use crate::my_executor::{Executor, Sleep};
async fn func_with_sleep() {
println!("Async function: before sleep");
Sleep::new(Duration::from_secs(1)).await;
println!("Async function: after sleep");
}
async fn calc_5() -> i32 {
5
}
fn main() {
let mut ex = Executor::new();
// Получаем фьючер (файбер)
let fut = func_with_sleep();
// Закидываем фьючер в очередь экзекьютора
ex.spawn(fut);
// Вместо async функции используем async замыкание
ex.spawn(async {
println!("Async closure: start");
async fn inner() {
println!("Async closure: inner function");
}
inner().await;
let a = calc_5().await;
println!("Async closure: async func call result {a}");
println!("Async closure: end");
});
ex.exec_blocking();
println!("All done");
}Эта программа напечатает:
Async function: before sleep
Async closure: start
Async closure: inner function
Async closure: async func call result 5
Async closure: end
Async function: after sleep
All done
Если вам интересно увидеть более универсальный, но относительно простой экзекьютор, то можете изучить исходный код экзекьютора из библиотеки futures:
https://github.com/rust-lang/futures-rs/tree/master/futures-executor
Tokio
Теперь, когда мы познакомились с фьючерами и экзекьюторами, мы можем порассуждать о том, как должен быть устроен эффективный экзекьютор для бекенд-приложений. Бекенд-приложения являются приложениями с интенсивным вводом/выводом (особенно по сетевой части), поэтому эффективный экзекьютор должен делать упор на работу с неблокирующим вводом/выводом.
Экзекьютор должен:
- … иметь пул потоков для выполнения файберов, которые занимаются только вычислениями. Этот пул не должен быть больше, чем количество ядер процессора.
- … предоставлять свой неблокирующий API, как минимум, для операций работы с сетью
- … иметь пул с одним потоком с наивысшим приоритетом, который будет обрабатывать неблокирующие операции ввода/вывода посредством epoll, io_uring, IOCP, kqueue.
- … для операций ввода/вывода, которые не имеют неблокирующего варианта (например, DNS вызовы), иметь пул потоков неограниченного размера.
Итак, получилось, что мы примерно описали экзекьютор из библиотеки Tokio.
Tokio — это высокопроизводительный асинхронный рантайм для приложений с интенсивным вводом/выводом. Он содержит как экзекьютор с несколькими пулами потоков (в том числе и для неблокирующих операций ввода/вывода), так и большую библиотеку функций для асинхронной работы с сетью, файловой системой, таймерами и т.д.
Tip
У библиотеки Tokio есть очень детальная документация, которая настоятельно рекомендуется к прочтению: https://tokio.rs/tokio/tutorial
Tokio API для ввода/вывода
Первое, что хочется заметить при изучении Tokio: авторы сделали API для асинхронной работы с сетью и файловой системой очень похожим на аналогичный синхронный API из стандартной библиотеки.
Возьмём для примера простую программу, которая считывает содержимое текстового файла в строку.
Для начала подключим Tokio в Cargo.toml:
[package]
name = "test_rust"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = {version = "1", features = ["full"]}
Сперва напишем реализацию с использованием синхронного API из стандартной библиотеки.
use std::fs::File;
use std::io::Read;
fn main() {
let mut file = File::open("/etc/fstab")
.unwrap();
let mut contents = String::new();
file.read_to_string(&mut contents)
.unwrap();
println!("{}", contents);
}А теперь то же самое, только с использованием асинхронного API из Tokio.
use tokio::fs::File;
use tokio::io::AsyncReadExt;
#[tokio::main]
async fn main() {
let mut file = File::open("/etc/fstab")
.await
.unwrap();
let mut contents = String::new();
file.read_to_string(&mut contents)
.await
.unwrap();
println!("{}", contents);
}Как видите, код работы с файлом абсолютно идентичен, за исключением вызовов .await и другой сигнатуры функции main.
Такой API — одна из причин, по которой Tokio настолько прост в освоении.
tokio::main
Теперь, когда мы увидели, как выглядит программа с использованием Tokio, давайте разбираться подробнее.
Первое, на чём следует остановиться — функция main. Как вы могли заметить, она стала async, и над ней появилась аннотация #[tokio::main]. Здесь нет никакой магии: главная функция в любой программе на Rust — это та функция main, с которой мы уже давно знакомы, и она является неасинхронной.
Просто в библиотеке Tokio определён процедурный макрос #[tokio::main], который превращает такой код:
#[tokio::main]
async fn main() {
// Код асинхронной программы
}в такой:
fn main() {
let mut rt = tokio::runtime::Runtime::new().unwrap();
rt.block_on(async {
// Код асинхронной программы
})
}Если вернуться к прошлой главе и посмотреть, как мы исполняли асинхронную функцию на экзекьюторе, то мы увидим, что там тоже присутствовал вызов block_on, который имел тот же смысл.
То есть экзекьютор Tokio работает точно так же, как и любой другой: компилятор превращает async функцию во фьючер, а этот фьючер далее передаётся экзекьютору для исполнения.
Task
Подобно тому, как с традиционной многопоточностью можно создавать ОС-потоки, Tokio позволяет вручную создавать файберы, которые в терминологии Tokio называются тасками (task - задача).
Создание таска осуществляется при помощи функции tokio::spawn, которая очень похожа на функцию thread::spawn, используемую для создания ОС-потока.
Сигнатура функции tokio::spawn:
pub fn spawn<F>(future: F) -> JoinHandle<F::Output> where
F: Future + Send + 'static,
F::Output: Send + 'static,Как видите, эта функция в качестве аргумента принимает фьючер (async блок или результат вызова async функции).
Например:
use tokio::task::{JoinError, JoinHandle};
async fn get_1() -> i32 {
1
}
#[tokio::main]
async fn main() {
// Создание таска из вызова async функции
let t1: JoinHandle<i32> = tokio::spawn(get_1());
let result1: Result<i32, JoinError> = t1.await;
println!("{result1:?}"); // Ok(1)
// Создание таска из async блока
let t2: JoinHandle<i32> = tokio::spawn(async { 5 });
let result2: Result<i32, JoinError> = t2.await;
println!("{result2:?}"); // Ok(5)
}Как видите, с точки зрения API, работа с тасками очень напоминает работу с ОС-потоками. Разница лишь в том, что ОС-потоки обслуживаются операционной системой, а таски — рантаймом Tokio.
Когда мы вызываем tokio::spawn, создаётся новый таск (являющийся обёрткой для фьючера, сгенерированного компилятором из async функции или async блока). Этот таск сразу же помещается в очередь Tokio экзекьютора на выполнение. В какой-то момент планировщик Tokio поместит этот таск на один из ОС-потоков и попытается его исполнить путём вызова метода poll у фьючера.
Вызов tokio::spawn возвращает объект tokio::task::JoinHandle, который очень похож на std::thread::JoinHandle, возвращаемый вызовом thread::spawn. Он также позволяет дождаться выполнения таска и получить его результат.
task vs thread
Мы много говорили о том, что потоки пользовательского пространства и неблокирующий API работают эффективнее, чем ОС-потоки и блокирующий API. Теперь, когда мы наконец добрались до Tokio, давайте проведём небольшое сравнение.
Напишем программу, которая создаёт миллион тасков, каждый из которых просто засыпает на 1 секунду, а потом завершает свою работу.
use std::time::Duration;
#[tokio::main]
async fn main() {
let mut handles = Vec::new();
for _ in 1..1000000 {
let t = tokio::spawn(async {
tokio::time::sleep(Duration::from_secs(1)).await;
});
handles.push(t);
}
for handle in handles {
let _ = handle.await;
}
}Давайте измерим, сколько времени выполняется эта программа и какую нагрузку на CPU она создаёт. Например, в Linux для этого можно запустить программу через утилиту time (не путать со встроенной shell командой). На Windows можно воспользоваться PowerShell командой Measure-Command.
$ cargo build
$ /bin/time cargo run
10.28user 4.07system 0:02.83elapsed 506%CPU (0avgtext+0avgdata 386308maxresident)k
0inputs+256outputs (0major+103536minor)pagefaults 0swaps
На ноутбуке автора (с 8-ядерным процессором Ryzen 7840HS и 32 гигабайтами оперативной памяти) программа выполнилась за 2.83 секунды, и использовала 386 мегабайт оперативной памяти в пике.
Теперь напишем такую же программу, только вместо Tokio тасков мы будем использовать обычные ОС-потоки.
use std::time::Duration;
use std::thread;
fn main() {
let mut handles = Vec::new();
for _ in 1..1000000 {
let t = thread::spawn(|| {
thread::sleep(Duration::from_secs(1));
});
handles.push(t);
}
for handle in handles {
let _ = handle.join().unwrap();
}
}Запустим и сравним результаты:
$ cargo build
$ /bin/time cargo run
thread '<unnamed>' (583640) panicked at library/std/src/sys/pal/unix/stack_overflow.rs:222:13:
failed to set up alternative stack guard page: Cannot allocate memory (os error 12)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' (91293) panicked at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/thread/mod.rs:729:29:
failed to spawn thread: Os { code: 11, kind: WouldBlock, message: "Resource temporarily unavailable" }
fatal runtime error: failed to initiate panic, error 5, aborting
Command terminated by signal 6
4.25user 71.05system 1:16.74elapsed 98%CPU (0avgtext+0avgdata 4219816maxresident)k
0inputs+0outputs (0major+1062256minor)pagefaults 0swaps
Этот вариант отработал за 1 минуту 16 секунд и в пике использовал 4.2 гигабайта оперативной памяти. Как видите, разница существенная.
Также в логе можно заметить, что несколько попыток создать поток потерпели неудачу.
Note
Есть вероятность, что при запуске на Linux вместо того, чтобы работать долго, программа сразу завершится с подобной ошибкой:
$ cargo run thread 'main' (52703) panicked at /home/stas/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/> thread/mod.rs:729:29: failed to spawn thread: Os { code: 11, kind: WouldBlock, message: "Resource temporarily unavailable" } note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace Command exited with non-zero status 101Эта ошибка указывает, что программа попыталась превысить максимальный лимит количества потоков и была аварийно завершена.
Если вы используете Gnome Terminal с настройками по умолчанию, то, скорее всего, вы столкнётесь с этой ошибкой. Для удачного запуска автор использовал эмулятор терминала Alacritty — кросплатформенный терминал, написанный на Rust.
Сравнив результаты работы этих примеров, можно с уверенностью сказать, что для некоторых задач Tokio гораздо эффективнее, чем ОС-потоки.
Синхронизация тасков
Tokio пытается копировать из стандартной библиотеки не только API для работы с файловой системой и сетью, но и API для механизмов синхронизации. Именно поэтому для синхронизации работы с данными из разных тасков Tokio предлагает типы Mutex, RwLock и Barrier, которые очень похожи на своих собратьев, работающих с ОС-потоками.
Например, давайте посмотрим на Tokio мьютекс:
use std::sync::Arc;
use tokio::sync::Mutex;
#[tokio::main]
async fn main() {
let m: Arc<Mutex<i32>> = Arc::new(Mutex::new(1));
let t = tokio::spawn({
let m = m.clone();
async move {
let mut guard = m.lock().await;
*guard = 2;
}
});
let _ = t.await;
println!("{m:?}");
}Как видите, этот пример очень похож на пример мьютекса из главы про многопоточность, с той разницей, что вызов lock() возвращает фьючер, на котором нужно вызвать .await.
Warning
Будьте осторожны: если в Tokio таске вы случайно используете мьютекс, предназначенный для работы с ОС-потоками, то получите серьёзное падение производительности.
Каналы
Tokio предоставляет не только свои варианты механизмов синхронизации, но и свои каналы.
mpsc
mpsc — Tokio аналог для multiple producers single consumer канала из стандартной библиотеки.
Рассмотрим пример:
use std::time::Duration;
use tokio::sync::mpsc;
use tokio::time::sleep;
#[tokio::main]
async fn main() {
// Создаём канал
let (snd, mut rcv) = mpsc::unbounded_channel::<i32>();
// Из нового таска отправляем число в канал
tokio::spawn({
let snd = snd.clone();
async move {
let _ = snd.send(1);
}
});
// Из еще одного нового таска отправляем число в канал
tokio::spawn({
let snd = snd.clone();
async move {
let _ = snd.send(2);
}
});
// В цикле считываем из канала числа и печатаем их на консоль.
// Если в течение секунды не пришло новых сообщений, то завершаем цикл.
while let Some(msg) = tokio::select! {
msg = rcv.recv() => msg,
_ = sleep(Duration::from_secs(1)) => None,
} {
println!("Received: {msg}");
}
}Здесь мы сначала создаём канал без ограничения на размер — mpsc::unbounded_channel.
Далее мы стартуем два таска, которые отправляют в канал по одному сообщению.
В конце у нас идёт интересный блок, аналогов которому в стандартной библиотеке нет. Мы используем макрос tokio::select, который принимает в себя несколько фьючеров (в нашем случае два) и возвращает результат того, который завершится первым.
Синтаксис использования этого макроса в какой-то степени похож на оператор match:
let переменная = tokio::select! {
шаблон_1 = фьючер_1 => выражение_1,
шаблон_2 = фьючер_2 => выражение_2,
};select! принимает несколько фьючеров и ожидает завершения одного из них. Когда какой-то из фьючеров завершился, тогда результат этого фьючера присваивается соответствующему ему шаблону, а затем выполняется соответствующее выражение. Результат этого выражения становится результатом всего select! блока. При этом результаты остальных фьючеров просто отбрасываются.
Так как функция tokio::time:sleep возвращает фьючер, её часто используют в связке с макросом select! в качестве таймаута для какой-то другой операции. Таким образом, в примере выше в блоке select! мы читаем сообщения из канала с таймаутом в 1 секунду.
oneshot
oneshot — канал, в который можно послать только одно сообщение.
Реализация очень элегантная:
use tokio::sync::oneshot;
#[tokio::main]
async fn main() {
let (snd, rcv) = oneshot::channel::<i32>(); // создаём канал
// Метод send забирает владение над self, тем самым уничтожая его.
// Поэтому send можно вызвать только однажды.
let _ = snd.send(1);
// Ресивер для oneshot не реализует Clone, поэтому его можно
// передать только лишь в одно место.
// Так как oneshot рассчитан на приём только одного сообщения,
// вместо метода receive() используется просто .await
let r = rcv.await;
println!("{r:?}"); // Ok(1)
}broadcast
broadcast — multi-producer, multi-consumer канал, в котором каждое сообщение от любого из отправителей отправляется всем потребителям.
use std::{thread::sleep, time::Duration};
use tokio::sync::broadcast::{self, Receiver};
// Создаёт ресивер, "живущий" в отдельном таске.
// Ресивер получает одно сообщение, печатает его и завершается.
fn spawn_receiver(name: &'static str, rcv: &Receiver<i32>) {
let mut rcv = rcv.resubscribe();
tokio::spawn({
async move {
println!("{name} > msg: {:?}", rcv.recv().await);
}
});
}
#[tokio::main]
async fn main() {
let (snd, rcv) = broadcast::channel::<i32>(100);
spawn_receiver("rcv-1", &rcv);
spawn_receiver("rcv-2", &rcv);
spawn_receiver("rcv-3", &rcv);
let _ = snd.send(5);
sleep(Duration::from_secs(1));
}Программа напечатает:
rcv-2 > msg: Ok(5)
rcv-1 > msg: Ok(5)
rcv-3 > msg: Ok(5)
Как видите, каждый из слушателей получил свою копию сообщения.
watch
Канал watch позволяет отправлять сообщения из разных тасков, а также из разных тасков сообщения читать. При этом для каждого читателя канал содержит только одно последнее записанное значение.
Этот тип канала обычно используется для информирования слушателей о смене некоего состояния на текущее.
use tokio::sync::watch;
#[tokio::main]
async fn main() {
let (snd, rcv) = watch::channel::<i32>(0);
// has_changed() показывает, приходили ли сообщения, не просмотренные ЭТИМ ресивером
println!("Has new messages: {}", rcv.has_changed().unwrap());
let _ = snd.send(1);
let _ = snd.send(2);
let _ = snd.send(3);
{
let mut rcv1 = rcv.clone();
println!("Receiver 1 changed: {}", rcv1.has_changed().unwrap());
{
// borrow_and_update() возвращает ссылку на последнее полученное значение
// и помечает это значение, как просмотренное на этом ресивере
let guard = rcv1.borrow_and_update();
println!("Receiver 1 value: {:?}", *guard);
}
println!("Receiver 1 changed: {}", rcv1.has_changed().unwrap());
}
{
let mut rcv2 = rcv.clone();
println!("Receiver 2 changed: {}", rcv2.has_changed().unwrap());
{
let guard = rcv2.borrow_and_update();
println!("Receiver 2 value: {:?}", *guard);
}
println!("Receiver 2 changed: {}", rcv2.has_changed().unwrap());
}
}Программа напечатает:
Has new messages: false
Receiver 1 changed: true
Receiver 1 value: 3
Receiver 1 changed: false
Receiver 2 changed: true
Receiver 2 value: 3
Receiver 2 changed: false
async_channel
Иногда в бекенд-приложениях нужно создать функциональность, где обработчики запросов генерируют заявки на какую-то ресурсоёмкую работу (например, обработку изображения), а далее эти заявки обрабатываются пулом обработчиков.

Казалось бы: это отличный сценарий использования для каналов. Однако проблема в том, что в Tokio нет типа канала, который позволяет множеству тасков отправлять сообщения и множеству тасков вынимать сообщения. То есть некоего аналога MPMC в Tokio нет.
К счастью, существует сторонняя библиотека async-channel, которая работает вместе с Tokio и предоставляет такой вид канала.
use async_channel::{Receiver, Sender};
use std::time::Duration;
use tokio::{task::JoinHandle, time::sleep};
// Создаёт таск, из которого отсылает заданное значение в канал
fn make_producer(snd: &Sender<i32>, value: i32) {
let snd = snd.clone();
tokio::spawn(async move {
let _ = snd.send(value).await;
});
}
// Создаёт таск - worker, который в цикле считывает сообщения из канала и печатает их.
// Если в течение секунды не поступает новых сообщений, то worker завершается.
fn make_worker(rcv: &Receiver<i32>, name: &'static str) -> JoinHandle<()> {
let rcv = rcv.clone();
tokio::spawn(async move {
loop {
tokio::select! {
msg = rcv.recv() => {
println!("{name} > received: {:?}", msg.unwrap());
sleep(Duration::from_millis(100)).await;
}
_ = sleep(Duration::from_secs(1)) => break,
}
}
})
}
#[tokio::main]
async fn main() {
let (snd, rcv) = async_channel::unbounded::<i32>();
make_producer(&snd, 1);
make_producer(&snd, 2);
make_producer(&snd, 3);
make_producer(&snd, 4);
let t1 = make_worker(&rcv, "worker-1");
let t2 = make_worker(&rcv, "worker-2");
let _ = t1.await;
let _ = t2.await;
}Программа напечатает:
worker-2 > received: 1
worker-1 > received: 2
worker-1 > received: 4
worker-2 > received: 3
LocalSet
Экзекьютор Tokio работает таким образом, что один и тот же таск может быть частично выполнен на одном ОС-потоке, потом остановлен и помещён в очередь ожидания ответа от операции ввода/вывода, а после возобновлён уже на другом ОС-потоке.
Именно поэтому данные, захватываемые таском, должны реализовать Send: ведь таск всегда может быть переброшен на другой поток для выполнения.
Однако в Tokio есть механизм, который позволяет указать, что таск должен выполняться на одном и том же ОС-потоке и не перебрасываться на другие. Этот механизм называется LocalSet.
let local_set = LocalSet::new();
// Этот таск будет выполнен на том же ОС потоке,
// который выполняет файбер, запустивший таск
// посредством LocalSet
local_set.spawn(async { тело таска });Рассмотрим пример, в котором мы инкрементируем счётчик из нескольких тасков.
При работе с обычными тасками мы должны были бы завернуть счётчик в Mutex (реализующий Sync, но не Send), а мьютекс, в свою очередь, завернуть в Arc, который реализует Send. Однако LocalSet позволяет использовать типы, не реализующие Send, а значит, вместо Arc можем использовать просто Rc.
use std::{rc::Rc, time::Duration};
use tokio::{sync::Mutex, task::LocalSet, time::sleep};
#[tokio::main]
async fn main() {
let counter = Rc::new(Mutex::new(0)); // Rc не реализует Send
let local_set = LocalSet::new();
for _ in 0..100 {
let counter = counter.clone();
local_set.spawn_local(async move { // порождаем таск на текущем ОС потоке
// Спит 1 секунду
sleep(Duration::from_secs(1)).await;
*counter.lock().await += 1;
});
}
local_set.await;
println!("{}", *counter.lock().await);
}Чтобы убедиться, что таски работают параллельно, запустим программу с помощью утилиты time:
$ /bin/time cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.04s
Running `target/debug/test_rust`
100
0.09user 0.05system 0:01.14elapsed 13%CPU (0avgtext+0avgdata 30524maxresident)k
0inputs+0outputs (0major+8035minor)pagefaults 0swaps
Как мы видим, при том, что в программе 100 тасков уснули на 1 секунду, общее время выполнения программы составило 1.14 секунды. Следовательно, таски действительно спали параллельно.
Task local
Имея дело с ОС-потоками, мы можем использовать хранилище, привязанное к потоку — Thread local. Для Tokio тасков существует аналогичный механизм — Task Local. Он позволяет создать “глобальную” переменную, которая для каждого таска будет своя.
Task local переменные объявляются при помощи макроса task_local.
tokio::task_local! {
pub static ПЕРЕМЕННАЯ: Тип;
}Имея подобное объявление, далее в коде мы можем создать task local скоуп с переменной.
ПЕРЕМЕННАЯ.scope(значение, async {
// Код в этом скоупе, а также все функции, которые вызваны из скоупа,
// имеют доступ к task local переменной так, словно это глобальная переменная
// типа LocalKey<Тип>
my_func()
});
fn my_func() {
let v = ПЕРЕМЕННАЯ.get();
// ...
}Все функции, вызванные внутри этого скоупа, будут иметь доступ к этой переменной так, словно она является глобальной. Тип этой глобальной переменной — LocalKey<T>, где T — тип, с которым мы объявляли переменную в макросе task_local!.
Если мы объявили нашу task local переменную с типом, который реализует Copy (например, i32), то на объекте LocalKey мы можем использовать метод get(), который просто извлекает копию значения.
Например:
tokio::task_local! {
pub static NUM: i32;
}
fn print_num() {
println!("NUM = {}", NUM.get());
}
#[tokio::main]
async fn main() {
NUM.scope(1, async { print_num() }).await;
NUM.scope(2, async { print_num() }).await;
}Программа напечатает:
NUM = 1
NUM = 2
Если же нам надо получить ссылку на значение, хранимое в task local переменной, то нам поможет метод with:
pub fn with<F, R>(&'static self, f: F) -> R where F: FnOnce(&T) -> RЭтот метод принимает и исполняет замыкание, которое ожидает ссылку на task local переменную в качестве аргумента.
tokio::task_local! {
pub static NAME: String;
}
fn print_name() {
NAME.with(|name| println!("NAME = {name}"))
}
#[tokio::main]
async fn main() {
NAME.scope("A".to_string(), async { print_name() }).await;
NAME.scope("B".to_string(), async { print_name() }).await;
}Какое же применение может быть у task local переменных?
Говоря о бекенд-приложениях, часто используют такое понятие, как “сквозная проблема” (cross-cutting concern). Это такой вид функциональности, который насквозь пронизывает логику программы и поэтому не может быть изолирован в отдельный модуль. Классическими примерами сквозной проблемы служат аутентификация/авторизация и логирование.
Например, в приложении может быть много различной функциональности, которая должна выполняться только в том случае, если её выполнение было инициировано запросом от пользователя, который авторизован для выполнения этой функциональности. Вопрос: как нам передавать информацию о пользователе и его правах?
Первый способ: во всех функциях, которые участвуют в обработке запроса, ввести аргумент, который будет хранить информацию о пользователе. Такой аргумент придётся добавить во все функции: как в те, которые проверяют информацию о пользователе непосредственно, так и в те, которые просто вызывают другие функции, которым эта информация может потребоваться. Согласитесь, не самое изящное решение.
Второй способ: в самом начале обработки запроса положить в task local информацию о пользователе, а дальше во всех местах, где она потребуется, считывать её из task local.
Для примера давайте представим, что мы пишем HTTP сервер. Этот сервер предоставляет эндпоинт /orders/submit, который позволяет пользователям, авторизованным с ролью CUSTOMER, отправлять заявки для выполнения.
Ожидается, что пользователь делает HTTP запрос c URL путём /orders/submit и передаёт в теле запроса текст заявки. Аутентификация пользователя осуществляется путём передачи ID его сессии через HTTP заголовок.
Мы напишем простенький роутер, который проверяет URL путь и, если путь равен /orders/submit, то роутер вызовет обработчик эндпоинта, отвечающий за заявки. Однако этот обработчик будет обёрнут в специальную обёртку, которая извлекает ID сессии пользователя из заголовков запроса, далее ищет роль пользователя по его ID и потом помещает всю эту информацию в task local. Следом начинается выполнение обработчика запроса, который достаёт роль пользователя из task local, чтобы определить, имеет ли пользователь право отправлять заявки.

Если потом у нас появятся дополнительные эндпоинты, то мы сможем переиспользовать для них нашу обёртку, наполняющую task local информацией о пользователе.
Для простоты мы не будем писать никакой сетевой код, а вручную создадим объект запроса и передадим его в роутер.
use std::{cell::RefCell, collections::HashMap};
tokio::task_local! {
pub static USER: RefCell<UserInfo>;
}
#[derive(PartialEq, Eq)]
enum Role {
CUSTOMER, GUEST,
}
struct UserInfo {
id: String, // ID пользователя (берётся из запроса)
role: Role, // Роль (определяется по ID на сервере)
}
// Представляет HTTP запрос от пользователя
struct Request {
path: String, // URL путь из запрос
headers: HashMap<String, String>, // HTTP заголовки
payload: String, // тело запроса
}
// Прослойка, которая выполняется перед запросом, и служит для
// вталкивания информации о пользователе и его правах в Task Local.
// * request - объект запроса
// * request_handler - обработчик запроса, который будет выполнен
// после подготовки данных о пользователе
async fn auth_middleware<F, Fut>(
request: Request,
request_handler: F
) -> Result<String, String>
where
F : Fn(Request) -> Fut,
Fut: Future<Output = Result<String, String>>
{
// Из заголовка "USER-ID" извлекаем ID сессии пользователя.
// Если заголовок отсутствует, то сразу прекращаем обработку запроса.
let Some(user_id) = request.headers.get("USER-ID") else {
return Err("No USER-ID header".to_string());
};
// Извлекаем из некоего хранилища роль, связанную с ID сессии пользователя.
let Some(role) = find_user_role(user_id.as_str()) else {
return Err(format!("No role for user with ID={user_id}"));
};
// Помещаем информацию о пользователе в Task Local
// и вызываем обработчик запроса
USER.scope(
RefCell::new(UserInfo { id: user_id.to_string(), role }),
async move { request_handler(request).await },
).await
}
fn find_user_role(id: &str) -> Option<Role> {
// Симулируем получение данных из БД
match id {
"ID_1111" => Some(Role::CUSTOMER),
"ID_2222" => Some(Role::GUEST),
_ => None,
}
}
// Обработчик для запроса с URL путём /orders/submit
async fn handle_submit_order(request: Request) -> Result<String, String> {
// Этот запрос просто вызывает функцию с бизнес логикой
submit_user_order(request.payload).await
}
// Бизнес логика обработки запроса пользователя
async fn submit_user_order(order: String) -> Result<String, String> {
// Эта функциональность доступна только для пользователей с ролью CUSTOMER
USER.with(|u| {
if u.borrow().role != Role::CUSTOMER {
Err(format!("User {} is not authorized", u.borrow().id))
} else {
Ok(format!("Order submitted: {order}"))
}
})
}
// Функция, которая по URL пути определяет, какой обработчик должен
// обрабатывать запрос.
async fn serve_request(request: Request) -> Result<String, String> {
// Для простоты примера, мы ожидаем запрос только по одному URL пути
match request.path.as_str() {
"/orders/submit" => auth_middleware(request, handle_submit_order).await,
_ => Err("Unexpected path".to_string())
}
}
#[tokio::main]
async fn main() {
// Запрос без указания ID сессии
{
let request = Request {
path: "/orders/submit".to_string(),
headers: HashMap::new(),
payload: "Test payload 1".to_string()
};
let response = serve_request(request).await;
println!("Response: {response:?}");
}
// Запрос с ID сессии пользователя с ролью CUSTOMER
{
let headers = HashMap::from([
("USER-ID".to_string(), "ID_1111".to_string())
]);
let request = Request {
path: "/orders/submit".to_string(),
headers,
payload: "Test payload 2".to_string()
};
let response = serve_request(request).await;
println!("Response: {response:?}");
}
// Запрос с ID сессии пользователя с ролью CUSTOMER
{
let headers = HashMap::from([
("USER-ID".to_string(), "ID_2222".to_string())
]);
let request = Request {
path: "/orders/submit".to_string(),
headers,
payload: "Test payload 3".to_string()
};
let response = serve_request(request).await;
println!("Response: {response:?}");
}
}Программа выводит:
Response: Err("No USER-ID header")
Response: Ok("Order submitted: Test payload 2")
Response: Err("User ID_2222 is not authorized")
async_trait
В этой главе мы рассмотрим решение одной проблемы, которая возникает при использовании async методов в трэйтах.
Допустим, мы разрабатываем бекенд для работы с некими товарами. Мы решили организовать код в виде двух компонентов: компонент, который отвечает за работу с базой данных, и компонент, который отвечает за бизнес логику.
fn main() {
let product_storage = ProductDbStorage {};
let product_service = ProductService { product_storage };
println!("All products: {:?}", product_service.get_all_products())
}
#[derive(Debug)]
struct Product { } // Некий тип товара
// Бизнес логика работы с продуктами
struct ProductService {
product_storage: ProductDbStorage,
}
impl ProductService {
fn get_all_products(&self) -> Vec<Product> {
self.product_storage.list_products()
}
}
// Работа с БД, в которой хранятся продукты
struct ProductDbStorage {
// инкапсулирует соединение к БД
}
impl ProductDbStorage {
fn list_products(&self) -> Vec<Product> {
// представим, что здесь происходит обращение к реальной базе данных
Vec::new()
}
}Однако такая жёсткая связанность компонентов не очень удобна. Например, если мы захотим написать юнит-тест для ProductService, то мы не сможем проинициализировать поле storage ничем, кроме ProductDbStorage, который работает с реальной базой данных. А ведь юнит-тест не подразумевает работу с реальными системами, и все обращения к ним должны быть заменены заглушками.
Чтобы ослабить связанность между компонентами, мы:
- абстрагируем тип
ProductDbStorageчерез трэйтProductStorage - в структуре
ProductServiceв полеstorageвместо непосредственно объектаProductDbStorageбудем хранитьBox<dyn ProductStorage>.
С такой структурой, мы уже можем написать юнит-тест.
fn main() {
let product_storage = ProductDbStorage {};
let product_service = ProductService {
product_storage: Box::new(product_storage)
};
println!("All products: {:?}", product_service.get_all_products())
}
#[derive(Debug)]
struct Product { }
struct ProductService {
product_storage: Box<dyn ProductStorage>,
}
impl ProductService {
fn get_all_products(&self) -> Vec<Product> {
self.product_storage.list_products()
}
}
trait ProductStorage {
fn list_products(&self) -> Vec<Product>;
}
struct ProductDbStorage { }
impl ProductStorage for ProductDbStorage {
fn list_products(&self) -> Vec<Product> { Vec::new() }
}
#[test]
fn test_product_service() {
// Заглушка для ProductStorage
struct ProductStorageMock;
impl ProductStorage for ProductStorageMock {
fn list_products(&self) -> Vec<Product> {
vec![Product {}]
}
}
let sut = ProductService {
product_storage: Box::new(ProductStorageMock) // заглушка
};
assert_eq!(sut.get_all_products().len(), 1);
}И вот теперь давайте попытаемся переписать ProductService и ProductStorage так, чтобы их методы были асинхронными.
#![allow(unused)]
fn main() {
struct ProductService {
product_storage: Box<dyn ProductStorage>,
} // ^^^^^^^^^^^^^^^^^^^^^^^
// Error: the trait `ProductStorage` is not dyn compatible
impl ProductService {
async fn get_all_products(&self) -> Vec<Product> {
self.product_storage.list_products().await
}
}
trait ProductStorage {
async fn list_products(&self) -> Vec<Product>;
}
struct ProductDbStorage { }
impl ProductStorage for ProductDbStorage {
async fn list_products(&self) -> Vec<Product> { Vec::new() }
}
}Увы, но мы увидим ошибку компиляции:
the trait ProductStorage is not dyn compatible
Эта ошибка гласит о том, что компилятор не может создать трэйт-объект для трэйта с async методами. Чтобы понять, почему так происходит, мы должны вспомнить, что функция вида
async fn myfunc() -> MyType {}превращается компилятором в
fn myfunc() -> impl Future<Output = MyType> {}В этом и кроется проблема. Чтобы создать трэйт-объект, компилятор должен построить таблицу виртуальных вызовов vtable. Однако одно из условий для этого состоит в том, что компилятор должен знать размер типов для значений, возвращаемых методами (чтобы иметь возможность аллоцировать место на стеке), но это невозможно, так как impl Future имеет неизвестный размер.
Стандартное решение этой проблемы с формированием vtable: завернуть возвращаемый тип в Box, чей размер на стеке известен. А так как мы имеем дело с асинхронным кодом (а Box не безопасен для многопоточности), то вместо Box следует использовать Pin<Box>.
Вооружившись этим знанием, давайте перепишем наш пример:
use std::pin::Pin;
#[tokio::main]
async fn main() {
let product_storage = ProductDbStorage {};
let product_service = ProductService {
product_storage: Box::new(product_storage)
};
println!("All products: {:?}", product_service.get_all_products().await)
}
#[derive(Debug)]
struct Product { }
struct ProductService {
product_storage: Box<dyn ProductStorage + Send + Sync>,
}
impl ProductService {
async fn get_all_products(&self) -> Vec<Product> {
self.product_storage.list_products().await
}
}
trait ProductStorage {
fn list_products<'a, 't>(
&'a self
) -> Pin<Box<dyn Future<Output = Vec<Product>> + Send + 't>>
where 'a: 't, Self: 't;
}
struct ProductDbStorage { }
impl ProductStorage for ProductDbStorage {
fn list_products<'a, 't>(
&'a self,
) -> Pin<Box<dyn Future<Output = Vec<Product>> + Send + 't>>
where 'a: 't, Self: 't {
Box::pin(async move { Vec::new() })
}
}Этот код успешно компилируется и запускается. Но согласитесь: выглядит он не слишком элегантно.
Note
Обратите внимание, что вместо
Box<dyn ProductStorage>мы используемBox<dyn ProductStorage + Send + Sync>
К счастью, существует библиотека async-trait, которая поможет исправить ситуацию. Просто пометьте и трэйт, и его реализацию аннотацией #[async_trait], и пишите код с использованием обычных async методов без всех этих Pin<Box>. Во время компиляции, обработчик аннотации сам заменит async методы на методы возвращающие Pin<Box>.
#[tokio::main]
async fn main() {
let product_storage = ProductDbStorage {};
let product_service = ProductService {
product_storage: Box::new(product_storage)
};
println!("All products: {:?}", product_service.get_all_products().await)
}
#[derive(Debug)]
struct Product { }
struct ProductService {
product_storage: Box<dyn ProductStorage + Send + Sync>,
}
impl ProductService {
async fn get_all_products(&self) -> Vec<Product> {
self.product_storage.list_products().await
}
}
#[async_trait::async_trait]
trait ProductStorage {
async fn list_products(&self) -> Vec<Product>;
}
struct ProductDbStorage { }
#[async_trait::async_trait]
impl ProductStorage for ProductDbStorage {
async fn list_products(&self) -> Vec<Product> { Vec::new() }
}Обзор экосистемы
Этот заключительный раздел посвящён написанию бэкенд-приложений на Rust.
Мы познакомимся с со следующими библиотеками:
- Axum — быстрая, легковесная и простая в использовании библиотека для создания HTTP-серверов от создателей Tokio.
- SQLx — библиотека для работы с реляционными СУБД
- Tower — библиотека компонентов для создания серверных и клиентских приложений (сам Axum построен поверх Tower)
- Utoipa — библиотека для генерации OpenAPI документации и интеграции со SwaggerUI
- Metrics — библиотека для сбора и выдачи метрик (мы рассмотрим Prometheus формат)
Axum — основы
Итак, когда речь заходит о бекенд приложениях, первое, что приходит на ум — HTTP сервер. В этой и нескольких последующих главах мы подробно разберёмся с созданием HTTP сервера при помощи библиотеки Axum.
Axum — легковесный фрэймворк от создателей Tokio, предназначенный для создания HTTP серверов. Axum всецело опирается на асинхронные возможности Tokio, что делает его высокопроизводительным и, при этом, простым в использовании.
Создание сервера
Начнём наше знакомство с Axum с простого примера: создадим HTTP сервер с одним эндпоинтом, который возвращает строку “Hello!”.
Создадим новый Cargo проект:
cargo new test_axum
Далее добавим в Cargo.toml нужные зависимости:
#![allow(unused)]
fn main() {
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"] }
axum = "0.8"
serde = { version = "1", features = ["derive"] }
serde_json = "1"
}Крэйт axum содержит в себе основные компоненты для создания HTTP сервера. С крэйтами tokio и serde мы уже знакомы.
Далее src/main.rs: мы напишем сервер, который слушает порт 8080 и предоставляет эндпоинт, который доступен по URL пути /hello и HTTP методу GET.
use axum::{Router, body::Body, http::StatusCode, response::Response, routing::get};
#[tokio::main]
async fn main() {
// Создаём роутер, которые задаёт соответствие метод+путь -> обработчик запроса
let app = Router::new()
// Указываем, что для пути /hello и метода GET вызывается обработчик hello
.route("/hello", get(hello));
// Создаём слушатель порта 8080 по протоколу TCP
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
// запускаем HTTP сервер
axum::serve(listener, app).await.unwrap();
}
// Обработчик запроса, который отвечает телом с текстом "Hello!"
// и заголовком: content-type: text/plain; charset=utf-8
async fn hello() -> Response {
Response::builder()
.status(StatusCode::OK)
.header("content-type", "text/plain; charset=utf-8")
.body(Body::new("Hello!".to_string()))
.unwrap()
}Теперь мы можем запустить наш сервер, как и любое другое Cargo приложение:
cargo run
После того как сервер запустится, мы можем в браузере перейти по адресу http://localhost:8080/hello. Открывшаяся страница должна отобразить следующее:
Вот так просто, при помощи Axum, мы смогли создать полноценный HTTP сервер.
Тип результата запроса
Для начала давайте разберём функцию-обработчик запроса из примера выше:
async fn hello() -> Response {
Response::builder()
.status(StatusCode::OK)
.header("content-type", "text/plain; charset=utf-8")
.body(Body::new("Hello!".to_string()))
.unwrap()
}Тип Response, представляющий HTTP ответ, должен быть интуитивно понятен: по аналогии с форматом HTTP ответа, он включает в себя код статуса ответа, заголовки и само тело ответа.
Не трудно заметить, что код для формирования объекта Response довольно громоздкий. Более того, указывать код статуса в большинстве случаев излишне, так как в подавляющем большинстве случаев он будет равен 200. К тому же, значение заголовка “content-type” можно было бы автоматически вывести на основании содержимого ответа.
Именно поэтому функция-обработчик запроса может возвращать не только объект типа Response, но значения любых типов, которые реализуют трэйт IntoResponse.
Например, функцию-обработчик запроса hello можно переписать так:
async fn hello() -> &'static str {
"Hello!"
}Согласитесь, такая форма гораздо легче читается.
Мы смогли вернуть из функции-обработчика запроса значение типа &'static str потому, что существует реализация IntoResponse для &'static str.
Для справки: она находится в крэйте axum-core в файле src/response/into_reponse.rs.
Также трэйт IntoResponse реализован еще для целого ряда типов, основные из которых:
()— ответ с кодом 200 и пустым телом- HeaderMap — ответ с кодом 200, пустым телом и дополнительными заголовками
String— ответ с кодом 200 и телом содержащим указанную строку- StatusCode — ответ с указанными HTTP кодом и пустым телом
(StatusCode, impl IntoResponse)— ответ с указанными HTTP кодом и телом, чей формат зависит от конкретного типа, реализующего трэйтIntoResponseResult<T, E> where T: IntoResponse, E: IntoResponse— и для Ok, и для Err ответ будет полностью зависеть от находящихся в них типов.
Например, дляResult<String, String>при значении:Ok("good".to_string())будет сформирован ответ с кодом 200 и телом, содержащим строку “good”Err("bad".to_string())— будет сформирован ответ с кодом 200 (да, тоже 200) и телом, содержащим строку “bad”.
- Body — ответ с кодом 200 и телом, хранимым в объекте
Body. Vec<u8>иBox<[u8]>— ответ с кодом 200, заголовкомcontent-typeравнымapplication/octet-streamи телом, содержащим указанные байты.- Json<T> — ответ с кодом 200, заголовком
content-type: application/jsonи телом, содержащим текст с JSON представлением переданного значения.
Рассмотрим несколько примеров функций-обработчиков запроса:
async fn handler_1() -> StatusCode {
StatusCode::OK
}
async fn handler_2() -> (StatusCode, &'static str) {
(StatusCode::OK, "Hello!")
}
async fn handler_3() -> Result<String, (StatusCode, String)> {
Err((StatusCode::INTERNAL_SERVER_ERROR, "Some problem".to_string()))
}
async fn handler_4() -> Vec<u8> {
vec![1,2,3]
}
use serde_json::{Value, json};
async fn handler_5() -> Json<Value> {
Json(json!({"name": "John Doe"}))
}
use serde::{Deserialize, Serialize};
#[derive(Serialize, Deserialize)]
struct Person {
name: String,
}
async fn handler_6() -> Json<Person> {
Json(Person { name: "John Doe".to_string() })
}Замыкание как обработчик запроса
В качестве обработчика запроса можно использовать не только функции, но и замыкания.
use axum::{Router, routing::get};
#[tokio::main]
async fn main() {
// Значение, захватываемое замыканием
let greeting = "Hello!".to_string();
let app = Router::new()
.route("/hello", get(async move || format!("{}", greeting)));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}Эндпоинт можно создать как из асинхронного замыкания:
.route("/hello", get(async move || format!("{}", greeting)))так и из замыкания, возвращающего фьючер:
.route("/hello", get(|| async move { format!("{}", greeting) }))Note
К сожалению, ввиду реализации макросов в Axum в роутере можно использовать только замыкание, созданное непосредственно в той же функции, в которой и сам роутер.
То есть не получится написать такую функцию:
fn make_hello_handler(greeting: String) -> impl AsyncFn() -> String { async move || { format!("{}", greeting) } }а потом использовать её в роутере так:
let greeting = "Hello!".to_string(); let closure = make_hello_handler(greeting); let app = Router::new() .route("/hello", get( closure));В главе про Tower мы узнаем как обойти это ограничение.
Аргументы запроса
Существует два способа передачи аргументов через строку URL: параметры пути (path parameters) и параметры запроса (query parameters).
Path parameters
Для того чтобы передать аргумент через URL путь, надо:
-
в роутере, в желаемой части пути указать переменную
.route("/часть/пути/{переменная}", get(функция-обработчик запроса)) -
В функции-обработчике запроса заинжектить аргумент посредством обёртки Path.
async обработчик(переменная: Path<String>) -> Response { ... }
Для примера модифицируем наш hello эндпоинт так, чтобы он принимал имя того, кого надо поприветствовать.
use axum::{Router, extract::Path, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello/{name}", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(path_args: Path<String>) -> String {
format!("Hello {}", path_args.0)
}Теперь, если мы перейдём по адресу http://localhost:8080/hello/Stas, то увидим приветствие “Hello Stas”.
Если нужно передать несколько параметров через путь, то вместо одного значения в Path будет инжектиться кортеж со значениями.
use axum::{Router, extract::Path, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello/{greeting}/{name}", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(path_args: Path<(String, String)>) -> String {
format!("{} {}", path_args.0.0, path_args.0.1)
}Если мы перейдём по адресу http://localhost:8080/hello/Aloha/Stas, то должно отобразиться “Aloha Stas”.
Для повышения читабельности кода для аргументов типа Path часто используют деструктурирование аргумента:
async fn hello(Path((greeting, name)): Path<(String, String)>) -> String {
format!("{greeting} {name}")
}В процессе инжекции аргументы также могут быть преобразованы в числовой тип. Например, создадим эндпоинт, который принимает два числа и возвращает их сумму:
use axum::{Router, extract::Path, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route("/math/add/{arg1}/{arg2}", get(add));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn add(Path((arg1, arg2)): Path<(i32, i32)>) -> String {
format!("{arg1} + {arg2} = {}", arg1 + arg2)
}Теперь, если перезапустить сервер и перейти по URL http://localhost:8080/math/add/1/2, то отобразится “1 + 2 = 3”.
Если же в URL пути указать нечисловое значение, например http://localhost:8080/math/add/1/ABC, то полученный ответ будет иметь код 400, и содержать текстовое описание ошибки: “Invalid URL: Cannot parse value at index 1 with value ABC to a i32”
Query parameters
Квери параметры обрабатываются немного проще: в функцию-обработчик запроса инжектится дополнительный аргумент — хеш-таблица, обёрнутая в тип Query. Эта хеш-таблица и содержит в себе все квери параметры.
async обработчик(Query(params): Query<HashMap<String, String>>) -> Response { ... }Например, перепишем наш hello эндпоинт так, чтобы через квери параметры он принимал опциональный аргумент — имя того, кого надо поприветствовать. Если никакое имя передано не было, то будет отображаться просто “Hello!”.
use std::collections::HashMap;
use axum::{ Router, extract::Query, routing::get };
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(Query(params): Query<HashMap<String, String>>) -> String {
match params.get("name") {
Some(name) => format!("Hello, {}!", name),
None => "Hello!".to_owned(),
}
}Теперь, если запустить сервер (cargo run) и открыть в браузере URL http://localhost:8080/hello?name=Stas, то мы должны увидеть “Hello, Stas!”. А если убрать квери параметр, т.е. перейти на http://localhost:8080/hello, то должно отобразиться просто “Hello!”.
Альтернативно, квери параметры можно инжектить не в хеш-таблицу, а в структуру, где имена полей совпадают с именами ожидаемых квери параметров.
use axum::{ Router, extract::Query, routing::get };
#[derive(serde::Deserialize)]
struct HelloParams {
name: Option<String>,
}
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(Query(params): Query<HelloParams>) -> String {
match params.name {
Some(name) => format!("Hello, {}!", name),
None => "Hello!".to_owned(),
}
}Методы запроса
До этого момента мы использовали только GET метод запроса.
let app = Router::new().route("/hello", get(hello));Здесь get(hello) указывает, что функция hello должна быть использована в качестве обработчика запроса только в случае, если полученный HTTP запрос имел метод GET.
Если мы хотим, чтобы этот обработчик вызывался не для метода GET, а для POST, то мы должны написать:
let app = Router::new().route("/hello", post(hello));Если для одного и того же URL пути надо иметь несколько обработчиков для разных HTTP методов, например для GET вызывать функцию обработчик list_users, а для POST — create_user, то это можно задать так:
let app = Router::new().route("/api/users", get(list_users).post(create_user));Для каждого из HTTP методов имеется соответствующая функция в модуле axum::routing: get, post, put, delete, patch, head, option и trace.
Также существует функция axum::routing::any, которая позволяет вызывать обработчик для любого HTTP метода:
let app = Router::new().route("/hello", any(hello));Чтение тела запроса
Как мы знаем, HTTP протокол позволяет передавать в запросе некие данные — тело запроса. Обычно тело содержится только в запросах с методами POST, PUT, PATCH.
Тело запроса может содержать данные в различных форматах (простой текст, JSON, XML, URL encoded данные, и т.д.), при этом тип формата принято передавать в HTTP заголовке content-type.
Чтобы получить содержимое тела запроса, нужно заинжектить его как аргумент в функцию-обработчик запроса. Например, если мы ожидаем, что запрос содержит в своём теле JSON документ, то мы можем заинжектить его как:
async fn обработчик(Json(аргумент): Json<ТипСущности>) -> Response { ... }Рассмотрим пример простого сервера, чей единственный эндпоинт принимает POST запрос с телом, представленным JSON документом, который содержит имя нового пользователя.
use axum::{Json, Router, response::IntoResponse, routing::post};
use serde::Deserialize;
#[tokio::main]
async fn main() {
let app = Router::new().route("/user", post(create_user));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
#[derive(Debug, Deserialize)]
struct CreateUserRequest {
name: String,
}
async fn create_user(Json(input): Json<CreateUserRequest>) -> impl IntoResponse {
format!("Created user: {input:?}")
}Используя команду cargo run, запустим сервер и при помощи утилиты CURL протестируем наш эндпоинт:
$ curl -X POST -i -H 'content-type: application/json' \
--data '{"name":"Stas"}' \
http://localhost:8080/user
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
content-length: 48
date: Sat, 29 Nov 2025 15:08:18 GMT
Created user: CreateUserRequest { name: "Stas" }
Как видите, функция обработчик корректно считывает JSON документ в объект структуры CreateUserRequest.
Если же мы попытаемся передать тело запроса в другом формате, например, URL encoded, то получим ответ с ошибкой:
$ curl -X POST -i -H 'content-type: application/x-www-form-urlencoded' \
--data 'name=Stas' \
http://localhost:8080/user
HTTP/1.1 415 Unsupported Media Type
content-type: text/plain; charset=utf-8
content-length: 54
date: Sat, 29 Nov 2025 15:05:19 GMT
Expected request with `Content-Type: application/json`
Чтобы считывать тело запроса в формате URL encoded нам придётся переписать наш обработчик так:
async fn create_user(Form(input): Form<FormData>) -> impl IntoResponse {
format!("Created user: {input:?}")
}Как правило, поддержка нескольких форматов данных одним и тем же эндпоинтом не требуется. Однако в следующих главах мы рассмотрим, как её можно реализовать при необходимости.
Разные типы результата
Иногда нам может понадобиться, в зависимости от значения каких-либо параметров, возвращать из обработчика значения разных типов. Например, либо JSON, либо простую строку, либо пустой ответ.
Так как тип результата функции может быть только один, мы не сможем возвращать из функции-обработчика одновременно объекты типов JSON, String и (). Поэтому нам придётся возвращать универсальный тип ответа — Response.
Модифицируем наш пример сервера с эндпоинтом, создающим нового пользователя:
- Если переданное имя пользователя пустое, то эндпоинт вернёт текстовое сообщение с ошибкой.
- Если переданное имя пользователя уже присутствует среди имеющихся пользователей, то эндпоинт вернёт ответ с пустым телом.
- Иначе эндпоинт вернёт JSON объект, содержащий имя созданного пользователя.
use std::{collections::HashSet, sync::LazyLock};
use axum::{Json,Router,body::Body,http::StatusCode,response::Response,routing::post};
use serde::{Deserialize, Serialize};
use tokio::sync::Mutex;
static USERS: LazyLock<Mutex<HashSet<String>>> =
LazyLock::new(|| Mutex::new(HashSet::new()));
#[tokio::main]
async fn main() {
let app = Router::new().route("/user", post(create_user));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
#[derive(Deserialize)]
struct CreateUserRequest { name: String }
#[derive(Serialize)]
struct CreateUserResponse { name: String }
async fn create_user(Json(input): Json<CreateUserRequest>) -> Response {
if input.name.is_empty() {
return Response::builder()
.status(StatusCode::BAD_REQUEST)
.header("content-type", "text/plain; charset=utf-8")
.body(Body::new("Empty name".to_string()))
.unwrap();
}
let mut guard = USERS.lock().await;
if guard.contains(&input.name) {
Response::builder()
.status(StatusCode::OK)
.body(Body::empty())
.unwrap()
} else {
guard.insert(input.name.clone());
Response::builder()
.status(StatusCode::CREATED)
.header("content-type", "application/json; charset=utf-8")
.body(Body::new(serde_json::to_string(
&CreateUserResponse { name: input.name }
).unwrap()))
.unwrap()
}
}Эндпоинт работает так, как и от него ожидалось:
$ curl -X POST -i -H 'content-type: application/json' --data '{"name":"Stas"}' \
http://localhost:8080/user
HTTP/1.1 201 Created
content-type: application/json; charset=utf-8
content-length: 15
{"name":"Stas"}
$ curl -X POST -i -H 'content-type: application/json' --data '{"name":"Stas"}' \
http://localhost:8080/user
HTTP/1.1 200 OK
content-length: 0
$ curl -X POST -i -H 'content-type: application/json' --data '{"name":""}' \
http://localhost:8080/user
HTTP/1.1 400 Bad Request
content-type: text/plain; charset=utf-8
content-length: 10
Empty name
Однако, нетрудно заметить, что большую часть кода функции-обработчика занимает громоздкое формирование объектов Response. Здесь на помощь опять приходит трэйт IntoResponse. Чтобы получить объект Response, мы будем вручную вызывать определённый в нём метод into_reponse().
async fn create_user(Json(input): Json<CreateUserRequest>) -> Response {
if input.name.is_empty() {
return (StatusCode::BAD_REQUEST, "Empty name").into_response();
}
let mut guard = USERS.lock().await;
if guard.contains(&input.name) {
().into_response()
} else {
guard.insert(input.name.clone());
let created_user = CreateUserResponse { name: input.name };
(StatusCode::CREATED, Json(created_user)).into_response()
}
}Таким образом, мы смогли сделать код обработчика вдвое короче.
HTTP заголовки запроса
В функцию-обработчик запроса можно заинжектить не только аргументы пути и квери параметры, но и HTTP заголовки запроса. Делается это при помощи типа обёртки HeaderMap.
Например, так мы можем считать все HTTP заголовки, полученные в запросе:
use axum::{Router, http::HeaderMap, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(headers: HeaderMap) -> String {
let headers_string = headers
.iter()
.map(|(h, v)|
format!("{}={}", h.as_str(), String::from_utf8_lossy(v.as_bytes()))
)
.collect::<Vec<_>>()
.join(",");
format!("Headers: {headers_string}")
}
Если перейти по адресу http://localhost:8080/hello, то мы должны увидеть что-то наподобие:
Headers: host=localhost:8080,user-agent=Mozilla/5.0 (X11; Linux x86_64; rv:145.0) Gecko/20100101 Firefox/145.0,accept=text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8,accept-language=en-US,en;q=0.5,accept-encoding=gzip, deflate, br, zstd,connection=keep-alive,cookie=sessionid=1b040076-cdf8-4ee8-bb52-0dfb786c1fd2,upgrade-insecure-requests=1,sec-fetch-dest=document,sec-fetch-mode=navigate,sec-fetch-site=none,sec-fetch-user=?1,priority=u=0, i
Также можно заинжектить целиком весь объект, представляющий заголовочную часть HTTP запроса. Делается это при помощи типа Parts, который выглядит так:
pub struct Parts {
pub method: Method,
pub uri: Uri,
pub version: Version,
pub headers: HeaderMap<HeaderValue>,
pub extensions: Extensions,
}Заинжектив объект Parts, мы сможем получить доступ не только к HTTP заголовкам запроса, но и к методу запроса и к URL пути.
use axum::{Router, http::request::Parts, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(parts: Parts) -> String {
let headers_string = parts.headers
.iter()
.map(|(h, v)| format!("{}={}", h.as_str(), String::from_utf8_lossy(v.as_bytes())))
.collect::<Vec<_>>()
.join(",");
format!(
"Method: {}\nURL: {}\nHeaders: {}",
parts.method, parts.uri, headers_string
)
}Ответ от эндпоинта http://localhost:8080/hello:
Method: GET
URL: /hello
Headers: host=localhost:8080,user-agent=Mozilla/5.0 (X11; Linux x86_64; rv:147.0) Gecko/20100101 Firefox/147.0,accept=text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8,accept-language=en-US,en;q=0.9,accept-encoding=gzip, deflate, br, zstd,connection=keep-alive,referer=http://localhost:3000/,cookie=sessionid=1b040076-cdf8-4ee8-bb52-0dfb786c1fd2,upgrade-insecure-requests=1,sec-fetch-dest=document,sec-fetch-mode=navigate,sec-fetch-site=same-site,sec-fetch-user=?1,priority=u=0, i
Состояние бекенда
В прошлой главе мы научились создавать эндпоинты, которые работают только со значениями, полученными из запроса. Однако обычно в реальных бекенд приложениях существует некое состояние самого приложения, которое может содержать конфигурацию, пул соединений с базой данных, HTTP и GRPC клиенты для общения с другими сервисами, данные метрик, кеш и т.д.
Для работы с таким состоянием бэкенда в Axum существует обёртка State. Принцип работы следующий:
1) Мы создаём объект произвольной структуры, и добавляем его в конфигурацию роутера при помощи метода with_state.
struct AppState {
// поля
}
#[tokio::main]
async fn main() {
let my_app_data = Arc::new(AppState { ... });
let app = Router::new()
.route("/чего-то", get(обработчик))
.with_state(my_app_data);
...
}2) Далее, при помощи обёртки State этот объект можно будет заинжектить в любую функцию-обработчик, зарегистрированную в этом роутере.
async fn обработчик(State(my_app_data): State<Arc<AppState>>) -> Response { ... } Для примера создадим простой бекенд с эндпоинтом счётчиком. Каждый раз, когда мы будем делать GET запрос на http://localhost:8080/count, значение счётчика будет инкрементироваться, и в ответ мы будем получать строку, содержащую новое значение счётчика.
use std::sync::{ Arc, atomic::{AtomicU64, Ordering} };
use axum::{Router, extract::State, routing::get};
// Эта структура будет определять состояние нашего бэкенда
struct AppState {
counter: AtomicU64,
}
#[tokio::main]
async fn main() {
let shared_state = Arc::new(AppState {
counter: AtomicU64::new(0),
});
let app = Router::new()
.route("/count", get(tick_counter))
.with_state(shared_state);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn tick_counter(State(state): State<Arc<AppState>>) -> String {
let prev_value = state.counter.fetch_add(1, Ordering::Relaxed);
format!("New value: {}", prev_value + 1)
}Первый переход на http://localhost:8080/count должен отобразить “New value: 1”, второй “New value: 2” и т.д.
У вас может возникнуть логичный вопрос: а почему бы просто не использовать глобальную переменную counter? Использование State имеет несколько преимуществ:
- Это нагляднее, так как сразу понятно, что данные относятся к состоянию приложения
- Это облегчает тестирование эндпоинтов
- В Axum приложение может иметь несколько роутеров, и для каждого из них можно указать свой объект состояния, что мы увидим в следующей главе
Роутинг
В этой главе мы подробнее разберёмся с возможностями роутинга эндпоинтов.
Фоллбэк (fallback)
Если путь из введённого пользователем URL не соответствует ни одному эндпоинту, зарегистрированному в роутере, то Axum по умолчанию просто ответит HTTP кодом 404.
Если вам необходимо обрабатывать такие запросы к несуществующим эндпоинтам “вручную”, то можно задать фоллбэк (fallback) обработчик. Фоллбэк — это обычная функция-обработчик запросов, которая регистрируется в роутере при помощи метода fallback и вызывается для всех запросов, для которых не был найден соответствующий эндпоинт.
В качестве примера сделаем фоллбэк обработчик, который просто отображает HTTP метод и URL запроса.
use axum::{Router, http::request::Parts, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new()
.route("/hello", get(hello))
.fallback(my_fallback);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
"Hello!"
}
async fn my_fallback(parts: Parts) -> String {
format!("Method: {}\nURL: {}", parts.method, parts.uri)
}После запуска программы, если перейти на http://localhost:8080/hello, то мы увидим “Hello!”, но попытка указать любой другой путь, например, http://localhost:8080/non-existing-page?a=1&b=2 приведёт к ответу вида:
Method: GET
URL: /non-existing-page?a=1&b=2
Слияние роутеров (merging)
Роутер эндпоинтов можно собирать из других под-роутеров. То есть мы можем определить одну часть эндпоинтов в одном объекте роутера, другую — в другом и потом “склеить” эти роутеры в главный роутер методом merge.
Для примера создадим один роутер для эндпоинтов, связанных с данными пользователей, а другой роутер для эндпоинтов, связанных с товарами.
use axum::{Router, routing::get};
#[tokio::main]
async fn main() {
let users_router = Router::new()
.route("/users", get(list_users));
let products_router = Router::new()
.route("/products", get(list_products));
let app = Router::new()
.merge(users_router)
.merge(products_router);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn list_users() -> &'static str {
"Users"
}
async fn list_products() -> &'static str {
"Products"
}Такое разнесение эндпоинтов по отдельным роутерам позволяет писать более модульный код. Но читабельность кода — не единственное преимущество, которое мы получаем, собирая роутер из под-роутеров. Этот подход так же позволяет задавать отдельные объекты состояния (State) для каждого из роутеров, обеспечивая тем самым изоляцию доступа к частям состояния приложения.
Модифицируем наш пример так, что для каждого из под-роутеров будет использоваться свой объект состояния.
use std::sync::Arc;
use axum::{Router, extract::State, routing::get};
#[derive(Debug)]
struct UserState {}
#[derive(Debug)]
struct ProductState {}
#[tokio::main]
async fn main() {
let users_router = Router::new()
.route("/users", get(list_users))
.with_state(Arc::new(UserState {}));
let products_router = Router::new()
.route("/products", get(list_products))
.with_state(Arc::new(ProductState {}));
let app = Router::new().merge(users_router).merge(products_router);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn list_users(State(state): State<Arc<UserState>>) -> String {
format!("Users endpoint. State: {state:?}")
}
async fn list_products(State(state): State<Arc<ProductState>>) -> String {
format!("Products endpoint. State: {state:?}")
}Если мы запустим приложение и перейдём по адресу http://localhost:8080/users, то мы увидим “Users endpoint. State: UserState”.
Если перейти на http://localhost:8080/products, то должно отобразиться — “Products endpoint. State: ProductState”.
Как видим, эндпоинты работают с тем объектом состояния, который был задан в их под-роутере. Но что случится, если мы добавим еще один объект состояния на уровень объединяющего роутера?
#[derive(Debug)]
struct MainState {}
let app = Router::new()
.merge(users_router)
.merge(products_router)
.with_state(Arc::new(MainState));Не изменится ничего: обработчики используют тот объект состояния, который объявлен “ближе всего” к ним.
Однако если мы удалим объект состояния, объявленный на уровне users_router, и добавим объект состояния типа UserState на уровне главного роутера, тогда при обращении к http://localhost:8080/users будет использоваться объект состояния из главного роутера.
Встраивание под-роутеров (nesting)
Встраивание (nesting) подобно вышерассмотренному слиянию (merging) с тем отличием, что при встраивании пути эндпоинтов из встраиваемого роутера предваряются указанным префиксом.
Например, имеется роутер:
let users_router = Router::new().route("/users", get(list_users));Если его встроить в главный роутер так:
let main_router = Router::new().nest("/api", users_router);то функция-обработчик list_users будет срабатывать для запроса с URL http://localhost:8080/api/users.
Для чего это нужно? Это позволяет еще больше повысить модульность кода. Например, мы можем вынести некоторые эндпоинты в отдельную библиотеку и встроить их в роутер в другом приложении, не опасаясь получить конфликт путей с другими эндпоинтами.
Приведём пример. Создадим два роутера, содержащие эндпоинты с конфликтующими путями. Используя разные префиксы, встроим эти два роутера в главный роутер.
use axum::{Router, routing::get};
#[tokio::main]
async fn main() {
let users_v1_router = Router::new().route("/users", get(list_users_v1));
let users_v2_router = Router::new().route("/users", get(list_users_v2));
let app = Router::new()
.nest("/api/v1", users_v1_router)
.nest("/api/v2", users_v2_router);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn list_users_v1() -> &'static str {
"Users endpoint Version 1"
}
async fn list_users_v2() -> &'static str {
"Users endpoint Version 2"
}При переходе на http://localhost:8080/api/v1/users отображается “Users endpoint Version 1”, а при переходе на http://localhost:8080/api/v2/users — “Users endpoint Version 2”.
Экстракторы
Экстрактор (Extractor) — механизм, позволяющий извлечь некое значение из (или на основе) HTTP-запроса и заинжектить его в функцию-обработчик запроса.
Мы уже знакомы с рядом стандартных экстракторов:
- экстрактор для инжекции аргументов пути — Path
- экстрактор для инжекции квери-параметров — Query
- экстрактор для инжекции тела запроса, переданного как JSON-документ — Json
Теперь давайте разберёмся, как экстракторы устроены.
Чтобы создать экстрактор, нужно реализовать один из двух трэйтов: FromRequestParts или FromRequest.
FromRequestParts
Трэйт FromRequestParts объявлен так:
pub trait FromRequestParts<S>: Sized {
type Rejection: IntoResponse;
async fn from_request_parts(
parts: &mut Parts,
state: &S,
) -> Result<Self, Self::Rejection>;
}Как видим, через аргументы он имеет доступ к заголовочной части HTTP-запроса — Parts и к объекту состояния. Строить свой экстрактор на базе FromRequestParts следует в том случае, если экстрактору необходимо иметь доступ только к заголовочной части HTTP-запроса, а доступ к телу запроса не нужен.
Чтобы понять, как это работает, давайте напишем свою упрощённую версию экстрактора Query, который инжектит квери-параметры в функцию-обработчик.
use std::collections::HashMap;
use axum::{Router, extract::FromRequestParts, http::request::Parts, routing::get};
struct MyQueryParams(HashMap<String, String>);
impl<S: Send + Sync> FromRequestParts<S> for MyQueryParams {
type Rejection = ();
async fn from_request_parts(
parts: &mut Parts, _state: &S
) -> Result<Self, Self::Rejection> {
let mut params = HashMap::new();
// Получает квери-строку вида key_1=val_1&key_2=val_2
if let Some(query_string) = parts.uri.query() {
// По разделителю &, разбиваем квери-строку на подстроки вида key=val
for pair in query_string.split("&") {
// вычленяем из строки key=value ключ и значение
let mut kv = pair.split("=");
if let Some(k) = kv.next() && let Some(v) = kv.next() {
params.insert(k.to_string(), v.to_string());
}
}
}
Ok(MyQueryParams(params))
}
}
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(MyQueryParams(map): MyQueryParams) -> String {
format!("Query params: {map:?}")
}Если запустить сервер (cargo run) и перейти по адресу http://localhost:8080/hello?a=1&b=2&c=3, то мы должны увидеть:
Query params: {"b": "2", "c": "3", "a": "1"}
Теперь давайте рассмотрим довольно распространённый пример: экстрактор, который извлекает ID сессии из HTTP заголовка.
use axum::{ Router, extract::FromRequestParts, routing::get };
use axum::http::{StatusCode, request::Parts};
// Экстрактор ID сессии
struct SessionId(String);
impl<S: Send + Sync> FromRequestParts<S> for SessionId {
type Rejection = StatusCode;
async fn from_request_parts(
parts: &mut Parts, _state: &S
) -> Result<Self, Self::Rejection> {
// ID сессии передаётся в заголовке sessionid
if let Some(value) = parts.headers.get("sessionid") {
if let Ok(string_value) = value.to_str() {
Ok(SessionId(string_value.to_string()))
} else {
Err(StatusCode::BAD_REQUEST)
}
} else {
Err(StatusCode::UNAUTHORIZED)
}
}
}
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(hello));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(SessionId(session_id): SessionId) -> String {
format!("Session ID: {session_id}")
}Протестируем наш эндпоинт:
$ curl -i http://localhost:8080/hello
HTTP/1.1 401 Unauthorized
content-length: 0
date: Mon, 01 Dec 2025 22:20:47 GMT
$ curl -i -H "sessionid: 1111-1111-1111" http://localhost:8080/hello
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
content-length: 26
date: Mon, 01 Dec 2025 22:08:03 GMT
Session ID: 1111-1111-1111
С практической точки зрения, будет гораздо удобнее, если в обработчик будет инжектиться не ID сессии, а сразу объект сессии пользователя. Экстракторы имеют доступ не только к заголовку HTTP-запроса, но и к объекту состояния приложения, где мы будем хранить сессию. Давайте перепишем наш экстрактор так, чтобы он сначала извлекал из заголовков запроса ID сессии, а далее из состояния доставал уже сам объект сессии.
use std::{collections::HashMap, sync::Arc};
use axum::{Router, extract::FromRequestParts, routing::get};
use axum::http::{StatusCode, request::Parts};
use tokio::sync::{Mutex, RwLock};
// Данные пользователя, хранимые в сессии
struct SessionData {
user_name: String,
}
struct AppState {
// ID сессии -> данные сессии
sessions: RwLock<HashMap<String, Arc<Mutex<SessionData>>>>,
}
// Экстрактор сессии. Хранит и ID сессии, и объект данных сессии
struct Session(String, Arc<Mutex<SessionData>>);
impl FromRequestParts<Arc<AppState>> for Session {
type Rejection = StatusCode;
async fn from_request_parts(
parts: &mut Parts,
state: &Arc<AppState>,
) -> Result<Self, Self::Rejection> {
if let Some(value) = parts.headers.get("sessionid") {
if let Ok(string_value) = value.to_str() {
let session_id = string_value.to_string();
let read_guard = state.sessions.read().await;
if let Some(session) = read_guard.get(&session_id) {
Ok(Session(session_id, session.clone()))
} else {
Err(StatusCode::UNAUTHORIZED)
}
} else {
Err(StatusCode::BAD_REQUEST)
}
} else {
Err(StatusCode::UNAUTHORIZED)
}
}
}
#[tokio::main]
async fn main() {
// Предподготовленное хранилище сессий для тестирования нашего экстрактора
let sessions: RwLock<HashMap<String, Arc<Mutex<SessionData>>>> = {
let mut data = HashMap::new();
// тестовая сессия
data.insert(
"1111-1111-1111".to_string(),
Arc::new(Mutex::new(SessionData {user_name: "John Doe".to_string()})),
);
RwLock::new(data)
};
let app_state = AppState { sessions };
let app = Router::new()
.route("/hello", get(hello))
.with_state(Arc::new(app_state));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello(Session(id, session): Session) -> String {
format!(
"Session ID: {id}, User name: {}",
session.lock().await.user_name
)
}Проверяем, что если передать ID несуществующей сессии, мы получим в ответ 401-й код.
$ curl -i -H "sessionid: 2222-2222-2222" http://localhost:8080/hello
HTTP/1.1 401 Unauthorized
content-length: 0
date: Mon, 01 Dec 2025 22:56:52 GMT
Теперь проверяем успешный сценарий:
$ curl -i -H "sessionid: 1111-1111-1111" http://localhost:8080/hello
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
content-length: 47
date: Mon, 01 Dec 2025 22:48:05 GMT
Session ID: 1111-1111-1111, User name: John Doe
FromRequest
Трэйт FromRequest имеет вид:
pub trait FromRequest<S, M = ViaRequest>: Sized {
type Rejection: IntoResponse;
async fn from_request(
req: Request<Body>,
state: &S,
) -> Result<Self, Self::Rejection>
}Он имеет доступ к объекту Request, который инкапсулирует все данные запроса, включая тело. Экстрактор следует строить на основе FromRequest только в случае, если необходим доступ к телу запроса.
Как вы уже могли догадаться, типы Json и Form<FormData>, которые мы рассматривали в разделе про чтение данных запроса, реализуют FromRequest, что позволяет им инжектиться в функцию обработчик.
Чтобы понять, как работать с FromRequest, давайте напишем экстрактор, который будет иметь возможность десериализовать данные запроса, переданные и в JSON, и в XML формате.
Для начала добавим зависимость serde-xml-rs в файл Cargo.toml:
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"]}
axum = "0.8"
serde = { version = "1", features = ["derive"] }
serde_json = "1"
serde-xml-rs = "0.8"
Теперь сама программа — src/main.rs:
use std::io::Cursor;
use axum::{Router, body::{Body, Bytes, to_bytes}, http::StatusCode, routing::post};
use axum::extract::{FromRequest, Request};
use serde::{Deserialize, de::DeserializeOwned};
// Экстрактор для данных запроса
struct AnyFormat<D: DeserializeOwned>(D);
impl<S: Send + Sync, D: DeserializeOwned> FromRequest<S> for AnyFormat<D> {
type Rejection = (StatusCode, &'static str);
async fn from_request(
request: Request<Body>, _state: &S
) -> Result<Self, Self::Rejection> {
// Извлекаем из запроса заголовок запроса и его тело
let (parts, body) = request.into_parts();
let Some(content_type) = parts.headers.get("content-type") else {
return Err((StatusCode::BAD_REQUEST, "Missing content-type"));
};
// Вычитываем байты запроса в буфер, максимальный размер которого 100MB
let body_bytes: Bytes = to_bytes(body, 100 * 1024 * 1024).await.unwrap();
let result = match content_type.to_str().unwrap() {
"application/json" => match serde_json::from_slice::<D>(&body_bytes) {
Ok(entity) => entity,
Err(_) => return Err((StatusCode::BAD_REQUEST, "Malformed JSON")),
},
"application/xml" => {
let cursor = Cursor::new(body_bytes);
match serde_xml_rs::from_reader::<'_, D, _>(cursor) {
Ok(entity) => entity,
Err(_) => return Err((StatusCode::BAD_REQUEST, "Malformed XML")),
}
}
_ => return Err((StatusCode::BAD_REQUEST, "Unsupported format")),
};
Ok(AnyFormat(result))
}
}
#[derive(Debug, Deserialize)]
struct CreateUserRequest {
name: String,
}
#[tokio::main]
async fn main() {
let app = Router::new().route("/users", post(create_user));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn create_user(AnyFormat(req): AnyFormat<CreateUserRequest>) -> String {
format!("Received: {req:?}")
}Теперь, запустив сервер, мы можем на один и тот же эндпоинт http://localhost:8080/users сделать запрос, отправив тело и в формате JSON:
$ curl -i -X POST -H "content-type: application/json" -d '{"name":"John Doe"}' \
http://localhost:8080/users
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
content-length: 48
date: Tue, 02 Dec 2025 00:31:16 GMT
Received: CreateUserRequest { name: "John Doe" }
и в формате XML:
$ curl -i -X POST -H "content-type: application/xml" \
-d '<CreateUserRequest><name>John Doe</name></CreateUserRequest>' \
http://localhost:8080/users
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
content-length: 48
date: Tue, 02 Dec 2025 00:56:08 GMT
Received: CreateUserRequest { name: "John Doe" }
Мидлваре
Мидлваре (middleware) — функциональность, которая вызывается перед функцией-обработчиком, а также имеет возможность обработать результат функции обработчика после её завершения. Можно сказать, что мидлваре оборачивает вызов функции-обработчика запроса.
╭────╮ ┌──────┐ request ┌──────────┐ request ┌──────────┐ │ ├────▶│ ├────────▶│ ├────────▶│ │ │Сеть│ TCP │ Axum │ │middleware│ │обработчик│ │ │◀────┤роутер│◀────────┤ │◀────────┤ запроса │ ╰────╯ └──────┘ response└──────────┘ response└──────────┘
Если мы хотим выполнять какие-то действия перед обработкой любого запроса, то мидлваре — как раз тот механизм, который позволит нам это сделать.
При этом мы можем создать несколько мидлваре, которые будут цепочкой выполняться перед обработчиком запроса и после него.
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
───▶│ ├───▶│ ├───▶│ ├───▶│ ├───▶
│middleware│ │middleware│ │middleware│ │middleware│
◀───┤ 1 │◀───┤ 2 │◀───┤ 3 │◀───┤ 4 │◀───
└──────────┘ └──────────┘ └──────────┘ └──────────┘
По диаграмме сверху видно, что объекты мидлваре выстраиваются подобно слоям, оборачивающим обработчик запроса. Именно поэтому зарегистрированное в роутере мидлваре называют слоем (layer).
Простейшее мидлваре
Самый простой вариант мидлваре выглядит как просто функция, которая принимает объект Request — HTTP запрос и объект Next — ссылка на следующий в цепочке мидлваре или обработчик запроса и возвращает объект Response, полученный от вызова обработчика запроса.
async fn мидлваре(request: Request, next: Next) -> Response {
// ... действия перед обработкой запроса
// вызываем следующий в цепочке обработчик
let response = next.run(request).await;
// ... действия после обработки запроса
// возвращаем результат из мидлваре
response
}Такую функцию надо:
После этого мидлваре начнёт отрабатывать для всех эндпоинтов, зарегистрированных в этом роутере.
let app = Router::new()
.route("/путь", get(функция-обработчик))
.layer(middleware::from_fn(мидлваре));Чтобы понять, как это работает, напишем классический пример мидлваре — мидлваре, который логирует время работы обработчика:
use axum::{Router, extract::Request, response::Response, routing::get};
use axum::middleware::{self, Next};
use tokio::time::Instant;
async fn log_exec_time(request: Request, next: Next) -> Response {
let start = Instant::now();
let response = next.run(request).await;
tracing::info!("Request took: {} micros", start.elapsed().as_micros());
response
}
#[tokio::main]
async fn main() {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
.init();
let app = Router::new()
.route("/hello", get(hello))
.layer(middleware::from_fn(log_exec_time));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
"Hello!"
}Запустим сервер:
$ cargo run
и перейдём в браузере на http://localhost:8080/hello.
В консоли должна появиться лог-запись с уровнем INFO от приложения test_axum.
2025-12-02T23:09:30.342625Z INFO test_axum: Request took: 52 micros
Слои
Теперь давайте рассмотрим, как взаимодействуют между собой разные мидлваре.
Добавим в наш hello сервер два мидлваре, каждый из которых:
- печатает в лог одно сообщение перед вызовом следующего обработчика по цепочке
- печатает в лог другое сообщение после того, как следующий по цепочке обработчик закончил свою работу
use axum::middleware::{Next, from_fn};
use axum::{Router, extract::Request, routing::get};
#[tokio::main]
async fn main() {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
.init();
let app = Router::new()
.route("/hello", get(hello))
.layer(from_fn(async |request: Request, next: Next| {
tracing::info!("Middleware-1: before call");
let response = next.run(request).await;
tracing::info!("Middleware-1: after call");
response
}))
.layer(from_fn(async |request: Request, next: Next| {
tracing::info!("Middleware-2: before call");
let response = next.run(request).await;
tracing::info!("Middleware-2: after call");
response
}));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
tracing::info!("Request handler");
"Hello!"
}Запустим сервер и перейдём по адресу http://localhost:8080/hello
stas@slim:~/dev/proj/rust/test_axum$ cargo run
Compiling test_axum v0.1.0
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.16s
Running `target/debug/test_axum`
2025-12-03T22:36:42.563720Z INFO test_axum: Middleware-2: before call
2025-12-03T22:36:42.563776Z INFO test_axum: Middleware-1: before call
2025-12-03T22:36:42.563800Z INFO test_axum: Request handler
2025-12-03T22:36:42.563823Z INFO test_axum: Middleware-1: after call
2025-12-03T22:36:42.563834Z INFO test_axum: Middleware-2: after call
Как видите, мидлваре оборачивают друг друга подобно матрёшке. При этом тот мидлваре, который был добавлен в роутер последним, становится первым в цепочке.
Работа со стэйтом
Нередко для логики работы мидлваре может понадобиться доступ к данным, хранящимся в состоянии. В этом случае функция-мидлваре будет иметь дополнительный аргумент — State.
async fn мидлваре(state: State<Стэйт>, request: Request, next: Next) -> Response {
// Действия перед обработкой запроса
let response = next.run(request).await;
// действия после обработки запроса
response
}Такая функция превращается в мидлваре при помощи функции from_fn_with_state.
let app = Router::new()
.route("/путь", get(функция-обработчик))
.with_state(state.clone())
.layer(middleware::from_fn_with_state(state, мидлваре));Как вы могли заметить, состояние приходится передавать отдельно и в with_state, и в from_fn_with_state. С одной стороны, это не очень удобно, но, с другой стороны, позволяет иметь разные объекты состояния для мидлвари и для роутера.
В качестве примера напишем мидлваре, который извлекает из HTTP заголовка ID сессии, потом достаёт из состояния соответствующий объект сессии пользователя и помещает его в task-local переменную. Далее эта task-local переменная используется из функции-обработчика запроса.
use std::{collections::HashMap, sync::Arc};
use axum::{Router, extract::{Request, State}, http::StatusCode, routing::get};
use axum::middleware::{self, Next};
use axum::response::{IntoResponse, Response};
use tokio::sync::{Mutex, RwLock};
tokio::task_local! {
pub static SESSION: Arc<Mutex<SessionData>>;
}
// Сессия пользователям
struct SessionData {
user_name: String,
}
// Состояние бекенда, хранящее сессии
struct AppState {
sessions: RwLock<HashMap<String, Arc<Mutex<SessionData>>>>,
}
async fn set_session_for_request(
State(state): State<Arc<AppState>>, request: Request, next: Next
) -> Response {
// получаем объект сессии
let session = if let Some(value) = request.headers().get("sessionid") {
if let Ok(string_value) = value.to_str() {
let session_id = string_value.to_string();
let read_guard = state.sessions.read().await;
if let Some(session) = read_guard.get(&session_id) {
session.clone()
} else {
return StatusCode::UNAUTHORIZED.into_response();
}
} else {
return StatusCode::BAD_REQUEST.into_response();
}
} else {
return StatusCode::UNAUTHORIZED.into_response();
};
// Записываем объект сессии в task-local переменную
let response = SESSION.scope(session, async {
next.run(request).await // вызываем обработчик по цепочке
}).await;
response
}
#[tokio::main]
async fn main() {
let sessions: RwLock<HashMap<String, Arc<Mutex<SessionData>>>> = {
let mut data = HashMap::new();
data.insert( // Создаём тестовую сессию пользователя
"1111-1111-1111".to_string(),
Arc::new(Mutex::new(SessionData {
user_name: "John Doe".to_string(),
})),
);
RwLock::new(data)
};
let app_state = Arc::new(AppState { sessions });
let app = Router::new()
.route("/hello", get(hello))
.with_state(app_state.clone())
.layer(middleware::from_fn_with_state(app_state, set_session_for_request));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> String {
// Извлекаем сессию из task-local переменной
let session = SESSION.with(|session| session.clone());
// используем сессию
format!("Hello, {}!", session.lock().await.user_name)
}Протестируем наш эндпоинт, чтобы убедиться, что мидлваре корректно помещает сессию в task-local переменную, доступную из функции-обработчика.
$ curl -i -H "sessionid: 1111-1111-1111" http://localhost:8080/hello
HTTP/1.1 200 OK
content-type: text/plain; charset=utf-8
content-length: 15
date: Wed, 03 Dec 2025 14:03:22 GMT
Hello, John Doe!
Стандартные мидлваре
Экосистема Axum предоставляет ряд стандартных мидлваре для таких вещей, как CORS, компрессия, таймауты и т.д., но перед тем как мы посмотрим на то, как ими пользоваться, мы должны познакомиться с библиотекой Tower.
Tower
Настало время поговорить о библиотеке Tower. Эта библиотека предоставляет инструментарий для создания клиентов и серверов из отдельных переиспользуемых блоков.
Первое, что нам необходимо сделать — добавить в Cargo.toml зависимости tower и tower_http.
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"]}
axum = "0.8"
tower = { version = "0.5", features = ["full"] }
tower-http = { version = "0.6", features = ["cors", "fs"] }
tracing = "0.1"
tracing-subscriber = { version = "0.3", features = ["env-filter"] }
serde = { version = "1", features = ["derive"] }
serde_json = "1"
Базовый тип, который предоставляет Tower — трэйт Service, являющийся абстракцией над асинхронной функцией.
#![allow(unused)]
fn main() {
pub trait Service<Request> {
type Response;
type Error;
type Future: Future<Output = Result<Self::Response, Self::Error>>;
// Работает по принципу poll в трэйте Future:
// * Возвращает Poll::Ready(Ok(())), если сервис готов к обработке запросов,
// и можно вызывать call
// * Возвращает Poll::Pending, если не готов. Экзекьютор будет оповещён
// о готовности через Context
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>>;
// Используется для непосредственного вызова функциональности сервиса
fn call(&mut self, req: Request) -> Self::Future;
}
}Service — абстракция над асинхронной функцией, которая принимает в качестве аргумента объект некоторого генерик-типа Request и возвращает либо некий генерик Response, либо ошибку.
Можно рассматривать сервис как async (Request) => Result<Response, Error>.
Такая абстракция — как раз то, что нужно для построения сетевого сервера. Например:
- Функции-обработчики запросов, которые мы регистрируем в роутере, по своей сути являются асинхронными функциями, которые принимают HTTP Request и возвращают HTTP Response.
- Мидлваре, с которыми мы познакомились в прошлой главе, также, по сути, являются асинхронными функциями, принимающими HTTP Request и возвращающими HTTP Response.
Хорошо, мы убедились, что такие сущности, как обработчики запросов и мидлваре, можно абстрагировать через трэйт Service. Но что это нам даёт?
Дело в том, что если различные обработчики абстрагированы до единого интерфейса, то они превращаются в универсальные строительные блоки, из которых можно строить цепочки для обработки запросов. То есть можно создать универсальные реализации для таких вещей, как retry, back-pressure, фильтрация запросов, CORS, компрессия, таймауты и т.д. И именно это и представляет из себя библиотека tower: трэйт Service и множество готовых универсальных строительных блоков, построенных на его основе.
Для нас всё это особенно интересно по причине того, что Axum позволяет использовать реализации Service и в качестве обработчиков запросов, и в качестве мидлваре.
Обработчик запроса как Service
До этого момента мы создавали эндпоинты путём регистрации функций-обработчиков в роутере при помощи функции route. При этом роутер предоставляет еще один метод — route_service, который регистрирует Service в качестве обработчика:
#![allow(unused)]
fn main() {
pub fn route_service<T>(self, path: &str, service: T) -> Self
where
T: Service<Request, Error = Infallible> + Clone + Send + Sync + 'static,
T::Response: IntoResponse,
T::Future: Send + 'static,
}where блок гласит, что для того чтобы тип выступал в роли обработчика запроса, он должен иметь такую реализацию трэйта Service, в которой:
- В качестве типа входного аргумента используется
axum::extract::Request. - Метод
callвозвращает объект типа, реализующегоIntoResponse, завёрнутый только вOk, не вErr. При возникновении ошибки можно возвращать объектOk(Response)с соответствующим HTTP кодом, но это должен быть именноOk.
То есть:
impl Service<Request> for МойСервис {
type Response = Response;
type Error = Infallible;
type Future = Pin<Box<dyn Future<Output=Result<Self::Response,Self::Error>>+Send>>;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> {
...
}
fn call(&mut self, req: Request) -> Self::Future {
...
}
}Tip
std::convert::Infallible — тип ошибки, объявленный как пустое перечисление, что делает невозможным создание объекта этого типа. Он используется в ситуациях, когда метод, объявленный в трэйте, возвращает
Result, но от некоторых реализаций этого трэйта требуется, чтобы они никогда не возвращали ошибку.
За основу для примера возьмём наш традиционный hello сервер, но на этот раз в качестве обработчика запроса будет выступать не функция, а объект, чей тип реализует трэйт Service.
use axum::{Router, extract::Request, response::{Response,IntoResponse}};
use axum::http::{Method, StatusCode};
use std::{future::Future, pin::Pin, task::{Context, Poll}, convert::Infallible};
use tower::Service;
#[derive(Clone)]
struct HelloService {
greeting: String,
}
impl Service<Request> for HelloService {
type Response = Response;
type Error = Infallible;
type Future = Pin<Box<dyn Future<Output=Result<Self::Response,Self::Error>>+Send>>;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> {
Poll::Ready(Ok(()))
}
fn call(&mut self, req: Request) -> Self::Future {
if req.method() == Method::GET {
let greeting = self.greeting.clone();
Box::pin(async move { Ok(greeting.into_response()) })
} else {
Box::pin(async move { Ok(StatusCode::METHOD_NOT_ALLOWED.into_response()) })
}
}
}
#[tokio::main]
async fn main() {
let app = Router::new()
.route_service("/hello", HelloService { greeting: "Hello!".to_string() });
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}Запустим сервер и перейдём на http://localhost:8080/hello. Мы должны увидеть всё то же “Hello!”.
Нетрудно заметить, что создавать обработчик запроса из типа, реализующего Service, более трудозатратно, чем создавать обработчик из функции. Однако такой подход предоставляет больше гибкости, так как позволяет нашему объекту-обработчику иметь внутреннее состояние.
Мидлваре как Service
Как мы знаем из прошлой главы, мидлваре регистрируется в роутере при помощи метода layer, который мы наконец-то готовы разобрать подробнее. Он имеет следующую сигнатуру:
pub fn layer<L>(self, layer: L) -> Router<S>
where
L: Layer<Route> + Clone + Send + Sync + 'static,
L::Service: Service<Request> + Clone + Send + Sync + 'static,
<L::Service as Service<Request>>::Response: IntoResponse + 'static,
<L::Service as Service<Request>>::Error: Into<Infallible> + 'static,
<L::Service as Service<Request>>::Future: Send + 'staticЗдесь Layer — трэйт для типов, которые возвращают объект, реализующий трэйт Service. Можно сказать, что Layer — это фабрика для Service. Сам трэйт Layer объявлен так:
pub trait Layer<S> {
type Service;
fn layer(&self, inner: S) -> Self::Service;
}Метод layer в качестве аргумента inner принимает объект, который является либо следующим мидлваре в цепочке, либо обработчиком запроса. Метод возвращает объект мидлваре, который будет встроен в цепочку обработки перед звеном, переданным в аргумент inner.
В качестве примера перепишем в виде сервиса наш мидлваре из прошлой главы: тот, который логирует время выполнения обработчика запроса.
use std::{pin::Pin, task::{Context, Poll}};
use axum::{Router, extract::Request, response::Response, routing::get};
use tokio::time::Instant;
use tower::{Layer, Service};
// Мидлваре, который замеряет время выполнения запроса.
#[derive(Clone)]
struct ExecTimeLogService<S> {
// Следующий мидлваре/обработчик запроса
next_handler: S,
}
impl<S> Service<Request> for ExecTimeLogService<S>
where
S: Service<Request, Response = Response> + Send + 'static,
S::Future: Send + 'static,
{
type Response = S::Response;
type Error = S::Error;
type Future = Pin<Box<dyn Future<Output=Result<Self::Response,Self::Error>>+Send>>;
fn poll_ready(&mut self, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> {
self.next_handler.poll_ready(cx)
}
fn call(&mut self, request: Request) -> Self::Future {
let start = Instant::now();
let future = self.next_handler.call(request);
Box::pin(async move {
let response = future.await?;
tracing::info!("Request took: {} micros", start.elapsed().as_micros());
Ok(response)
})
}
}
// Реализация Layer, которая отвечает за встраивание нашего мидлваре
// в цепочку обработки запроса
#[derive(Clone)]
struct ExecTimeLogLayer;
impl<S> Layer<S> for ExecTimeLogLayer {
type Service = ExecTimeLogService<S>;
// Axum вызывает этот метод, чтобы получить объект мидлваре для дальнейшего
// встраивания его в цепочку обработки запроса.
// inner - это следующий в цепочке мидлваре или обработчик запроса.
fn layer(&self, inner: S) -> Self::Service {
ExecTimeLogService { next_handler: inner }
}
}
#[tokio::main]
async fn main() {
tracing_subscriber::fmt()
.with_max_level(tracing::Level::INFO)
.init();
let app = Router::new()
.route("/hello", get(hello))
.layer(ExecTimeLogLayer);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
"Hello!"
}Запустим наше приложение и перейдём на http://localhost:8080/hello
$ cargo run
Compiling test_axum v0.1.0
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.00s
Running `target/debug/test_axum`
2025-12-05T17:32:48.512545Z INFO test_axum: Request took: 82 micros
Как и в случае с обработчиками запросов, создание мидлваре путём реализации трэйта Service даёт больше гибкости, так как позволяет объекту мидлваре иметь состояние.
Стандартные сервисы
В прошлой главе мы сказали, что для Axum существует ряд стандартных мидлваре (и сервисов), основанных на инфраструктуре Tower. Теперь мы готовы с ними познакомиться.
сервис ServeFile
Сервис ServeFile позволяет отдавать файл в качестве ответа на запрос.
Для примера сделаем эндпоинт, который возвращает HTML файл.
Сначала создадим в корне проекта файл index.html:
<html>
<body>
<h1>Hello</h1>
</body>
</html>
Теперь src/main.rs:
use axum::Router;
use tower_http::services::ServeFile;
#[tokio::main]
async fn main() {
let app = Router::new()
.route_service("/index", ServeFile::new("index.html"));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}После запуска сервера при переходе на http://localhost:8080/index мы должны увидеть нашу страницу из index.html.
Мидлваре CorsLayer
Если мы пишем сервер с таким API, который предполагается вызывать из браузера, то мы неизбежно столкнёмся с CORS (Cross-Origin Resource Sharing) проблемой: если домен, с которого загружается сам сайт, отличается от домена, на котором располагается API сервер, то браузер в целях безопасности не позволит делать вызовы.
Для того чтобы браузер разрешил странице, загруженной с домена X, выполнять запросы на API, которое находится на домене Y, необходимо, чтобы API сервер Y разрешил вызывать себя со страниц, загруженных с домена X. Конечно, мы можем сами написать мидлваре, который будет проставлять необходимые Access-Control-Allow-Origin заголовки, но в этом нет нужды, так как существует готовый мидлваре, делающий тоже самое — CorsLayer.
В примере ниже мы разрешаем Cross-origin вызовы наших эндпоинтов, если вызовы осуществляются из страниц, загруженных с http://mydomain.com или http://api.mydomain.com.
use axum::{Router, routing::get};
use tower_http::cors::CorsLayer;
#[tokio::main]
async fn main() {
let allowed_origins = [
"http://mydomain.com".parse().unwrap(),
"http://api.mydomain.com".parse().unwrap(),
];
let app = Router::new()
.route_service("/api/hello", get(hello))
.layer(CorsLayer::new().allow_origin(allowed_origins));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
"Hello!"
}Другие сервисы
К этому моменту вам должно быть понятно, как использовать сервисы и мидлваре, основанные на tower. Напоследок перечислим некоторые наиболее часто используемые из них.
- сервис ServeDir — подобен вышерассмотренному
ServeFile, но возвращает не конкретный файл, а запрошенные файлы из указанной директории. - сервис Redirect — позволяет переадресовать запрос на другой URL
- мидлваре CompressionLayer — сжимает ответ на запрос при помощи указанного кодека (gzip, deflate, zstd и т.д.)
- мидлваре RequestDecompressionLayer — автоматически декодирует тело запроса, сжатое кодеком
- мидлваре NormalizePathLayer — убирает ненужные знаки
/в конце URL пути - мидлваре RequestBodyLimitLayer — отвергает с 413-м кодом те запросы, чьё тело превышает заданный размер
- мидлваре TimeoutLayer — позволяет установить максимальное время выполнения эндпоинта, после истечения которого будет возвращён указанный HTTP код
- мидлваре TraceLayer — для всех запросов логирует момент получения запроса, и время его выполнения
- мидлваре InFlightRequestsLayer — считает метрику “количество запросов, находящихся в обработке”
Завершение работы сервера
Мы разобрались, как создавать HTTP сервер, теперь давайте разберёмся, как его правильно выключать.
graceful shutdown
По умолчанию, если программа получает сигнал о необходимости завершения, она сразу же прекращает свою работу. При этом, если в программе был запущен Axum сервер, то обработка запросов, выполнявшихся в этот момент, прерывается.
Note
В данной ситуации речь идёт о сигналах, отправляемых операционной системой в качестве реакции на действие, подразумевающее закрытие программы. Например в Unix-подобных системах приложению отправляется сигнал:
SIGTERM, если родительский процесс был завершёнSIGINT, если в консоли, где запущена программа, нажали Ctrl+C.Оба этих сигнала по умолчанию приводят к немедленному выключению программы.
(Также любой сигнал можно отправлять программно, или при помощи утилиты kill)
Если сервер содержит функциональность, которую нежелательно прерывать до её завершения, то применяют так называемый graceful shutdown — корректное выключение. Этот подход подразумевает, что сервер выключается не сразу, а ждёт завершения всех уже обрабатываемых запросов.
Для корректного выключения применяется метод with_graceful_shutdown, который используется следующим образом:
axum::serve(listener, app)
.with_graceful_shutdown(шатдаун_фьючер)
.await
.unwrap();Как это работает? Если мы добавляем к нашему серверу вызов .with_graceful_shutdown(), то это меняет поведение сервера так, что сразу после того, как сервер стартует свою работу, он начинает ждать завершения шатдаун фьючера. Шатдаун фьючер — это любой объект, чей тип реализует уже знакомый нам трэйт Future. После завершения этого шатдаун фьючера Axum начнёт выключаться следующим образом:
- Сразу остановит приём новых запросов по сети
- Дождётся завершения всех уже выполняемых запросов
- Завершит работу сервера
Сперва нам надо разобраться, как работает этот шатдаун фьючер. Для этого рассмотрим следующий пример:
use axum::{Router, routing::get};
use std::time::Duration;
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(async || "Hello!"));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app)
.with_graceful_shutdown(tokio::time::sleep(Duration::from_secs(5)))
.await
.unwrap();
}Если мы запустим это приложение (cargo run), то оно проработает 5 секунд, а после завершится. Почему так? Как мы сказали, добавление вызова .with_graceful_shutdown(шатдаун_фьючер) приводит к тому, что после завершения шатдаун фьючера Axum дождётся завершения всех обрабатываемых запросов и выключится. В примере выше в качестве шатдаун фьючера мы использовали результат вызова функции sleep из библиотеки Tokio. Эта функция возвращает фьючер, который завершается по истечении указанного временного интервала. В нашем случае — 5 секунд.
Этот пример наглядно показывает, что в качестве сигнала к завершению можно использовать любой фьючер, что даёт нам некую свободу в реализации механизма завершения приложения.
Important
Когда мы устанавливаем шатдаун фьючер вызовом
with_graceful_shutdown, мы не перезатираем немедленное завершение программы при полученииSIGTERMилиSIGINT. Мы задаём дополнительный выключатель, которым можем управлять программно.
Сигналы
Как мы уже сказали, по умолчанию, когда Axum приложение получает сигнал SIGTERM или SIGINT, срабатывает стандартный обработчик, который сразу завершает всё приложение. При этом graceful shutdown не происходит, что является для нас нежелательным.
Если мы хотим, чтобы graceful shutdown работал и при получении SIGTERM и SIGINT, то нам необходимо создать свой шатдаун фьючер, который завершается при получении сигнала SIGTERM или SIGINT, тем самым инициируя корректное выключение.
Для перехвата SIGINT библиотека Tokio предлагает функцию ctrl_c. Эта функция перезатирает стандартный обработчик SIGINT, что позволит избежать поведения по умолчанию в виде немедленного завершения приложения.
Tip
SIGINT— сигнал, специфичный для UNIX-подобных операционных систем, однако в Windows существует его аналог — событиеCTRL_C_EVENT, которое работает по тем же правилам. При работе в Windows функцияctrl_cбудет перехватыватьCTRL_C_EVENT.
Можете попробовать запустить такую программу:
#[tokio::main]
async fn main() {
tokio::signal::ctrl_c().await.unwrap();
println!("After Ctrl+C had been pressed");
}После нажатия Ctrl+C вы увидите в консоли текст “After Ctrl+C had been pressed”. Однако если вы запустите такой код:
#[tokio::main]
async fn main() {
tokio::time::sleep(std::time::Duration::from_hours(1)).await;
println!("After Ctrl+C had been pressed");
}и нажмёте Ctrl+C, то не увидите ничего. Это доказывает, что установка обработчика для SIGINT путём вызова функции ctrl_c перезатирает стандартный обработчик для SIGINT.
Второй сигнал, который нам надо перехватывать — SIGTERM. Этот сигнал обычно отправляется программе либо когда завершается операционная система, либо когда завершается родительский процесс программы.
Tip
С точки зрения разработки бэкенд приложений надо отметить, что когда kubernetes начинает выключать pod, то именно
SIGTERMотправляется программе, запущенной в контейнере. При этом по умолчанию kubernetes даёт программе 30 секунд на самостоятельное завершение, а после высылаетSIGKILL, который сразу завершит программу на уровне ядра операционной системы.
В отличие от сигнала SIGINT, для SIGTERM в Windows отсутствует аналог, поэтому код для перехвата обоих сигналов обычно имеет вид:
use tokio::signal;
#[tokio::main]
async fn main() {
let ctrl_c = signal::ctrl_c();
// SIGTERM доступен только на UNIX-подобных системах
#[cfg(unix)]
let terminate = async {
signal::unix::signal(signal::unix::SignalKind::terminate())
.expect("Cannot create SIGTERM handler")
.recv()
.await;
};
// На не UNIX-подобных системах ожидание SIGTERM заменяем на бесконечное ожидание
#[cfg(not(unix))]
let terminate = std::future::pending::<()>();
// Ожидаем либо нажатие Ctrl+C, либо SIGTERM
tokio::select! {
_ = ctrl_c => {},
_ = terminate => {},
}
println!("After Ctrl+C or SIGTERM");
}Здесь мы используем макрос select, рассмотренный в главе про Tokio.
Теперь давайте реализуем корректное выключение сервера при нажатии Ctrl+C в консоли (пока без SIGTERM, чтобы код был менее громоздким):
use axum::{Router, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route("/hello", get(async || "Hello!"));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app)
.with_graceful_shutdown(shutdown_signal())
.await
.unwrap();
}
async fn shutdown_signal() {
tokio::signal::ctrl_c().await.unwrap()
}Эта версия сервера корректно выключается по нажатию Ctrl+C, при этом перед полным выключением сервера Axum дождётся окончания выполнения обработки всех HTTP запросов.
В том, что сервер дождётся завершения всех запросов, легко убедиться. Давайте модифицируем наш hello эндпоинт так, чтобы он никогда не завершался:
use axum::{Router, routing::get};
#[tokio::main]
async fn main() {
let app = Router::new().route(
"/hello",
get(async || {
std::future::pending::<()>().await; // Никогда не завершится
"Hello!"
}),
);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app)
.with_graceful_shutdown(shutdown_signal())
.await
.unwrap();
}
async fn shutdown_signal() {
tokio::signal::ctrl_c().await.unwrap()
}Теперь, если после запуска сервера мы перейдём на http://localhost:8080/hello, то мы инициируем обработку запроса, которая никогда не закончится. Поэтому, если после этого мы нажмём в консоли с запущенным сервером Ctrl+C, то мы инициируем корректное завершение, которое просто зависнет в ожидании окончания обработки hello запроса.
Решение проблемы зависания очевидно: нужно добавить к запросам таймаут. Из прошлой главы мы знаем, что существует стандартный Tower мидлваре, реализующий таймауты — TimeoutLayer.
Окончательный пример с таймаутом и обработкой SIGINT и SIGTERM:
use axum::Router;
use tokio::signal;
#[tokio::main]
async fn main() {
let app = Router::new()
.route(
"/hello",
get(async || {
std::future::pending::<()>().await; // Никогда не завершится
"Hello!"
}),
)
.layer(TimeoutLayer::with_status_code(
StatusCode::REQUEST_TIMEOUT,
Duration::from_secs(10),
));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app)
.with_graceful_shutdown(shutdown_signal())
.await
.unwrap();
}
async fn shutdown_signal() {
let ctrl_c = signal::ctrl_c();
#[cfg(unix)]
let terminate = async {
signal::unix::signal(signal::unix::SignalKind::terminate())
.expect("Cannot create SIGTERM handler")
.recv()
.await;
};
#[cfg(not(unix))]
let terminate = std::future::pending::<()>();
tokio::select! {
_ = ctrl_c => {},
_ = terminate => {},
}
}Остановка фоновых задач
Напоследок, давайте разберём сценарий, когда кроме HTTP сервера у нас также имеется фоновый поток (Tokio таск), который по каналу получает сообщения, отправленные из обработчика HTTP запроса. В рамках корректного отключения нам сначала нужно прекратить приём новых HTTP запросов, далее обработать оставшиеся в канале сообщения и только потом завершить фоновый поток.
Для примера напишем простой сервер с одним эндпоинтом, который через аргумент пути получает слово и отправляет это слово в канал. Фоновая задача будет просто считывать сообщения из канала и печатать их на консоль.
use axum::{Router, http::StatusCode, routing::get};
use axum::extract::{Path, State};
use std::time::Duration;
use tokio::{signal, sync::{broadcast, mpsc}};
#[tokio::main]
async fn main() {
// Канал, для оповещения фоновых задач о необходимости завершиться
let (shutdown_snd, mut shutdown_rcv) = broadcast::channel::<()>(1);
// Канал, по которому эндпоинт передаёт сообщения фоновой задаче
let (word_snd, mut word_rcv) = mpsc::unbounded_channel::<String>();
// Стартуем фоновую задачу, которая принимает по каналу сообщения
// и обрабатывает их.
// Для простоты она будет принимать строковые значения и просто печатать их.
let bg_job = tokio::spawn({
async move {
// Цикл обработки сообщений
loop {
tokio::select! {
// Если получено сообщение, то обрабатываем его
word_resp = word_rcv.recv() => {
if let Some(word) = word_resp {
process_msg(word).await;
}
}
// Если получен сигнал завершаться, то выходим из цикла
_ = shutdown_rcv.recv() => {
println!("> Worker received shutdown command");
break;
}
}
}
// Обрабатываем остатки сообщений в канале
while let Ok(word) = word_rcv.try_recv() {
process_msg(word).await;
}
println!("> Worker is finished");
}
});
let app = Router::new()
.route("/enqueue/{word}", get(handle_request))
.with_state(word_snd);
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app)
.with_graceful_shutdown(shutdown_signal())
.await
.unwrap();
// Извещаем фоновый процесс о необходимости завершиться
println!("> Sending shutdown command to workers");
let _ = shutdown_snd.send(());
let _ = bg_job.await;
}
// Эндпоинт, который получает слово из URL пути и отправляет это слово в канал.
// Далее фоновой задачей, это слово будет считано из канала и обработано.
async fn handle_request(
Path(word): Path<String>,
State(word_snd): State<mpsc::UnboundedSender<String>>,
) -> StatusCode {
match word_snd.send(word) {
Ok(_) => StatusCode::CREATED,
Err(_) => StatusCode::INTERNAL_SERVER_ERROR,
}
}
// Эмуляция бурной деятельности по обработке слова
async fn process_msg(w: String) {
tokio::time::sleep(Duration::from_secs(1)).await;
println!("Word: {w}");
}
async fn shutdown_signal() {
let ctrl_c = signal::ctrl_c();
#[cfg(unix)]
let terminate = async {
signal::unix::signal(signal::unix::SignalKind::terminate())
.expect("Cannot create SIGTERM handler")
.recv()
.await;
};
#[cfg(not(unix))]
let terminate = std::future::pending::<()>();
tokio::select! {
_ = ctrl_c => {},
_ = terminate => {},
}
}Запустив сервер, мы можем перейти на http://localhost:8080/enqueue/hello, после чего в консоли будет напечатано “Word: hello”.
После нажатия Ctrl+C в консоли с запущенным сервером приложения корректно завершится.
Тестирование эндпоинтов
Экосистема Axum предлагает крэйт axum-test, который позволяет проводить полноценное тестирование эндпоинтов, минуя сетевую часть. Это очень удобно, так как позволяет запускать тесты быстрее и не переживать о коллизии портов.
Крэйт axum-test предоставляет обёртку TestServer, при помощи которой можно вызывать эндпоинты “напрямую”:
// Создаём роутер с эндпоинтами, которые будем тестировать
let app = Router::new()
.route("/give-5", get(|| async { "5" }))
// Создаём тестовый сервер, который работает без сетевого слушателя
let server = TestServer::new(app).unwrap();
// Делаем запрос к эндпоинту "напрямую"
let response = server.get("/give-5").await;
// Проверяем результат запроса
response.assert_text("5");Давайте добавим тест для нашего hello эндпоинта. При этом мы немного модифицируем код создания роутера, чтобы его было проще тестировать.
Для начала включим axum-test в Cargo.toml.
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"]}
axum = "0.8"
[dev-dependencies]
axum-test = "18"
Функциональность из крэйта axum-test понадобится только в тестах, поэтому мы объявили её в секции зависимостей для тестов — [dev-dependencies].
Теперь вынесем создание роутера в отдельную функцию, чтобы её можно было вызывать из теста, и допишем сам тест:
use std::collections::HashMap;
use axum::{Router, extract::Query, routing::get};
#[tokio::main]
async fn main() {
let app = setup_app();
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
// Создание роутера
fn setup_app() -> Router {
Router::new()
.route("/hello", get(hello))
}
async fn hello(Query(map):Query<HashMap<String, String>>) -> String {
if let Some(name) = map.get("name") {
format!("Hello, {name}!")
} else {
String::from("Hello!")
}
}
// Этот модуль, содержащий тест, будет компилироваться только при запуске тестов.
#[cfg(test)]
mod test {
use axum_test::TestServer;
use axum::http::StatusCode;
use super::*;
#[tokio::test]
async fn test_hello_endpoint() {
let app = setup_app();
let server = TestServer::new(app).unwrap();
// Тестируем вызов без квери параметра
let response1 = server.get("/hello").await;
response1.assert_status(StatusCode::OK);
response1.assert_text("Hello!");
// Тестируем вызов с квери параметром
let response2 = server.get("/hello?name=Stas").await;
response2.assert_status(StatusCode::OK);
response2.assert_text("Hello, Stas!");
}
}SQLx
Настало время поговорить о работе с реляционными базами данных.
Для работы с реляционными СУБД мы будем использовать популярную библиотеку SQLx, которая поддерживает PostgreSQL, MySQL, SQLite и MS SQL Server.
SQLx предоставляет:
- драйверы для СУБД
- пул соединений
- API для выполнения SQL и получения ответов
- конверторы, преобразующие ответ от БД в объекты Rust структур
Тестовая БД
Для примера будем использовать СУБД PostgreSQL. Вы можете поставить дистрибутив PostgreSQL локально или использовать docker образ.
Сначала создайте новую БД с именем mydb. Если вы предпочитаете использовать докер, то можете использовать следующие команды:
Запустить контейнер с PostgreSQL:
docker run --name my_pg_container \
-p 5432:5432 \
-e POSTGRES_PASSWORD=1111 \
-d postgres
Зайти в консоль запущенного контейнера:
docker exec -it my_pg_container bash
Запустить psql (консольный клиент для PostgreSQL):
psql -U postgres
В консоли psql создать новую БД:
CREATE DATABASE mydb;
Выбрать mydb в качестве текущей активной БД:
\c mydb;
(Чтобы посмотреть все имеющиеся БД, используется команда \list)
Для наших примеров нам понадобится база данных с двумя таблицами: “банковские аккаунты” и “история транзакций”.
┌────────────┐ ┌────────────────┐
│ accounts │ │ transactions │
├────────────┤ ├────────────────┤
│ id │───┐ │ id │
│ owner_name │ │ │ amount │
│ balance │ ├────*│ src_account_id │
└────────────┘ └────*│ dst_account_id │
│ tx_timestamp │
└────────────────┘
Выполните следующий SQL, чтобы создать таблицы и тестовые данные к ним:
CREATE SEQUENCE accounts_seq START WITH 1000;
CREATE TABLE accounts ( -- mydb.public.accounts
id BIGINT PRIMARY KEY DEFAULT nextval('accounts_seq'),
owner_name VARCHAR(255) NOT NULL UNIQUE,
balance NUMERIC(10, 2) NOT NULL DEFAULT 0.00 CHECK (balance >= 0)
);
CREATE SEQUENCE transactions_seq START WITH 1000;
CREATE TABLE transactions ( -- mydb.public.transactions
id BIGINT PRIMARY KEY DEFAULT nextval('transactions_seq'),
amount NUMERIC(10, 2) DEFAULT 0.00,
src_account_id BIGINT NOT NULL,
dst_account_id BIGINT NOT NULL,
tx_timestamp TIMESTAMP NOT NULL,
FOREIGN KEY (src_account_id) REFERENCES accounts (id),
FOREIGN KEY (dst_account_id) REFERENCES accounts (id)
);
INSERT INTO accounts(id, owner_name, balance) VALUES
(1, 'John Doe', 1000.00),
(2, 'Ivan Ivanov', 2000.00);
INSERT INTO transactions(amount, src_account_id, dst_account_id, tx_timestamp)
VALUES
(10.00, 1, 2, TO_TIMESTAMP('2025-12-11 14:00:00', 'YYYY-MM-DD HH24:MI:SS')),
(20.00, 2, 1, TO_TIMESTAMP('2025-12-12 15:00:00', 'YYYY-MM-DD HH24:MI:SS'));
Можете воспользоваться psql командой \dt, чтобы посмотреть список таблиц в базе данных и убедиться, что таблицы accounts и transactions присутствуют.
Подключение к СУБД
Теперь когда база данных создана, можно приступать к программе на Rust.
Создадим новый проект:
cargo new test_sqlx
И добавим в Cargo.toml зависимости:
- sqlx — сама библиотека SQLx. Фичи:
postgresвключает в компиляцию реализации sqlx интерфейсов для PostgreSQLbigdecimalподключает поддержку типаBigDecimal: SQL типNUMERICобычно конвертируют именно вBigDecimal
- chrono — библиотека для работы с датой и временем
- bigdecimal — библиотека, которая предоставляет тип BigDecimal — числовой тип большого размера и без потери точности при совершении операций над числами с плавающей запятой
[package]
name = "test_sqlx"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"] }
sqlx = { version = "0.8", features = ["postgres", "chrono", "runtime-tokio", "bigdecimal"]}
chrono = "0.4"
bigdecimal = "0.4"
Теперь мы можем написать программу, которая подключается к PostgreSQL базе данных. Для создания пула соединений к PostgreSQL используется билдер PgPoolOptions, который позволяет сконфигурировать целый ряд параметров пула соединения, таких как:
- минимальное и максимальное количество соединений в пуле
- таймаут для получения соединения из пула, максимальное время жизни соединения, максимальное время жизни простаивающего соединения
- коллбэки, которые могут выполняться: после установки соединения с сервером СУБД, перед получением соединения из пула, после возврата соединения в пул
- различные опции логирования
Рассмотрим простейший пример подключения к нашей свежесозданной БД:
use sqlx::{Pool, Postgres, postgres::PgPoolOptions};
#[tokio::main]
async fn main() {
let pool: Pool<Postgres> = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb")
.await
.unwrap();
}Для указания непосредственно настроек подключения к БД используется один из двух методов: connect (его мы использовали в примере выше) или connect_with.
connect
Метод connect задаёт настройки подключения при помощи URL строки.
Формат: протокол://логин:пароль@хост/бд?параметры.
Например:
- Для PostgreSQL:
postgres://mylogin:mypassword@localhost/mydb\ - Для MySQL:
mysql://mylogin:mypassword@host/mydb\ - Для SQLite:
sqlite::memory:илиsqlite://my.db
connect_with
Метод connect_with — задаёт настройки подключения при помощи структуры PgConnectOptions, которая инкапсулирует такие параметры, как хост, логин, пароль, имя БД и т.д.
PgConnectionOption позволяет выполнить более тонкую настройку по сравнению с connect.
Пример использования:
use sqlx::postgres::{PgConnectOptions, PgPoolOptions};
#[tokio::main]
async fn main() {
// Опции подключения
let connection_option = PgConnectOptions::new()
.host("localhost")
.username("postgres")
.password("1111")
.database("mydb");
// Создание пула соединений
let pool = PgPoolOptions::new()
.connect_with(connection_option)
.await
.unwrap();
}Выборка данных
Типизированные запросы
Для выборки данных SQLx предлагает тип QueryAs, который позволяет выполнить SQL-запрос и сконвертировать ответ от БД в объекты структур соответствующего типа.
Объект QueryAs, как правило, создаётся при помощи функции sqlx::query_as.
let query: QueryAs<'_, Postgres, ТипРезультата, PgArguments> = sqlx::query_as(
"SELECT поле1, поле2, поле3 FROM таблица"
);Далее объекту QueryAs необходимо передать объект пула соединений с БД, чтобы он мог получить соединение и выполнить запрос. Для этого используется один из следующих методов:
- fetch_all — ожидает, что результатом запроса будет множество записей
- fetch_one — ожидает, что результатом запроса будет ровно одна запись
- fetch_optional — ожидает, что результатом запроса будет не более одной записи
Если мы хотим выбрать множество записей и получить результат в форме вектора объектов, то код будет выглядеть примерно так:
#[derive(FromRow)]
struct ТипРезультата {
поле1: Тип1,
поле2: Тип2,
поле3: Тип3,
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new().connect("PG_URL").await.unwrap();
let query: QueryAs<'_, Postgres, ТипРезультата, PgArguments> = sqlx::query_as(
"SELECT поле1, поле2, поле3 FROM таблица"
);
let result: Vec<ТипРезультата> = query.fetch_all(&pool).await.unwrap();
}Как вы могли заметить, структура, в объекты которой перепаковывается ответ от БД, должна реализовать трэйт FromRow. При этом имена полей структуры должны совпадать с именами соответствующих колонок в результате SQL-запроса.
Рассмотрим пример выборки из таблицы accounts в нашей базы данных:
use sqlx::{postgres::PgPoolOptions, prelude::FromRow, types::BigDecimal};
#[derive(Debug, FromRow)]
struct Account {
id: i64,
owner_name: String,
balance: BigDecimal,
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
// Выборка списка записей
let all_accounts: Vec<Account> = sqlx::query_as(
"SELECT id, owner_name, balance FROM accounts"
).fetch_all(&pool).await.unwrap();
for acc in all_accounts {
println!("{}: {}, {}", acc.id, acc.owner_name, acc.balance.to_string());
}
// 1: John Doe, 1000
// 2: Ivan Ivanov, 2000
// Выборка одной записи
let opt_acc_1: Option<Account> = sqlx::query_as(r#"
SELECT id, owner_name, balance FROM accounts WHERE owner_name=$1
"#)
.bind("John Doe") // Привязываем значение к плэйсхолдеру $1
.fetch_optional(&pool)
.await.unwrap();
if let Some(acc) = opt_acc_1 {
println!("{}: {}, {}", acc.id, acc.owner_name, acc.balance.to_string());
}
// 1: John Doe, 1000
}Как видите, принцип простой — нужно:
- Написать SQL-запрос
- Создать структуру с таким же набором полей, как и набор колонок в результате SQL-запроса
- Воспользоваться функцией
query_as
query_as используется только для выборки двух и более колонок. Если необходимо выбрать только одну колонку, то вместо query_as используется функция query_scalar, которая ведёт себя точно так же, но конвертирует результат от БД не в объекты структур, а в простые типы (строки и числа).
Например:
use sqlx::{postgres::PgPoolOptions};
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
// Выборка одной колонки
let account_ids: Vec<i64> = sqlx::query_scalar("SELECT id FROM accounts")
.fetch_all(&pool).await.unwrap();
println!("All IDs: {account_ids:?}"); // All IDs: [1, 2]
// Выборка одного значения
let accounts_count: i64 = sqlx::query_scalar("SELECT COUNT(*) FROM accounts")
.fetch_one(&pool).await.unwrap();
println!("Number of accounts: {accounts_count}"); // Number of accounts: 2
}Теперь давайте рассмотрим пример с JOIN запросом: выберем всю историю транзакций с указанием имён отправителя и получателя денег. Чтобы получить имя по ID аккаунта, мы сделаем JOIN таблицы transactions на таблицу accounts.
use sqlx::{postgres::PgPoolOptions, prelude::FromRow, types::BigDecimal};
use chrono::NaiveDateTime;
#[derive(Debug, FromRow)]
struct TransactionFullInfo {
id: i64,
amount: BigDecimal,
src_account_owner_name: String,
dst_account_owner_name: String,
tx_timestamp: NaiveDateTime,
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb")
.await
.unwrap();
let transaction: Vec<TransactionFullInfo> = sqlx::query_as(r#"
SELECT
tx.id as id, tx.amount, tx.tx_timestamp,
src_acc.owner_name as src_account_owner_name,
dst_acc.owner_name as dst_account_owner_name
FROM
transactions tx
JOIN accounts src_acc ON tx.src_account_id = src_acc.id
JOIN accounts dst_acc ON tx.dst_account_id = dst_acc.id
"#)
.fetch_all(&pool).await.unwrap();
for tx in transaction {
println!(
"TXID:{} amount={}, timestamp={}, src: {}, dst: {}",
tx.id, tx.amount, tx.tx_timestamp,
tx.src_account_owner_name, tx.dst_account_owner_name
);
}
// TXID:1 amount=10, timestamp=2025-12-11 14:00:00, src: John Doe, dst: Ivan Ivanov
// TXID:2 amount=20, timestamp=2025-12-12 15:00:00, src: Ivan Ivanov, dst: John Doe
}Если в тексте запроса надо задать аргументы, то значения для них передаются при помощи метода bind.
Для примера сделаем запрос, который для заданных отправителя и получателя выводит общую сумму только тех транзакций, чья сумма превышает указанное значение.
use sqlx::{postgres::PgPoolOptions, types::BigDecimal};
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let total_amount: BigDecimal = sqlx::query_scalar(r#"
SELECT
SUM(amount)
FROM transactions tx
JOIN accounts src_acc ON tx.src_account_id = src_acc.id
JOIN accounts dst_acc ON tx.dst_account_id = dst_acc.id
WHERE
amount >= $1
AND src_acc.owner_name = $2
AND dst_acc.owner_name = $3
"#)
.bind(20.0)
.bind("Ivan Ivanov")
.bind("John Doe")
.fetch_one(&pool).await.unwrap();
println!("{total_amount}"); // 20
}Важно отметить, что для передачи аргументов запроса, SQLx использует так называемые prepared statement. То есть для таких запросов на стороне сервера СУБД разбор SQL кода и формирование плана запроса производится только в первый раз. Все дальнейшие вызовы этого же запроса с другими значениями аргументов будут переиспользовать план запроса от предыдущих вызовов.
Нетипизированные запросы
Тип QueryAs позволяет сделать выборку, и сразу конвертировать результат в объекты структуры. Однако есть другой тип запроса — Query, который не занимается такой конвертацией, а возвращает результат в виде коллекции нетипизированных записей Row, которые похожи на хеш-таблицы.
Объект Query создаётся функцией sqlx::query, которая очень похожа на sqlx::query_as. Для того чтобы выполнить объект Query, как и в случае с QueryAs, нужно использовать один из fetch_* методов:
let query: Query<'_, Postgres, PgArguments> = sqlx::query(
"SELECT поле1, поле2, поле3 FROM таблица"
);
let rows: Vec<PgRow> = query.fetch_all(&pool).await.unwrap();Результат запроса представлен объектами типа PgRow (был бы MySqlRow для MySQL или SqliteRow для SQLite).
Для извлечения значений колонок из PgRow используется метод try_get.
В качестве примера перепишем с использованием sqlx::query прошлый пример JOIN запроса:
use chrono::NaiveDateTime;
use sqlx::postgres::PgRow;
use sqlx::{postgres::PgPoolOptions, types::BigDecimal};
use sqlx::Row;
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb")
.await
.unwrap();
let rows: Vec<PgRow> = sqlx::query(r#"
SELECT
tx.id as id, tx.amount, tx.tx_timestamp,
src_acc.owner_name as src_account_owner_name,
dst_acc.owner_name as dst_account_owner_name
FROM
transactions tx
JOIN accounts src_acc ON tx.src_account_id = src_acc.id
JOIN accounts dst_acc ON tx.dst_account_id = dst_acc.id
"#)
.fetch_all(&pool)
.await
.unwrap();
for r in rows {
let id: i64 = r.try_get("id").unwrap();
let amount: BigDecimal = r.try_get("amount").unwrap();
let ts: NaiveDateTime = r.try_get("tx_timestamp").unwrap();
let src: String = r.try_get("src_account_owner_name").unwrap();
let dst: String = r.try_get("dst_account_owner_name").unwrap();
println!("TXID:{id} amount={amount}, timestamp={ts}, src: {src}, dst: {dst}");
}
// TXID:1 amount=10, timestamp=2025-12-11 14:00:00, src: John Doe, dst: Ivan Ivanov
// TXID:2 amount=20, timestamp=2025-12-12 15:00:00, src: Ivan Ivanov, dst: John Doe
}Вставка данных
Теперь рассмотрим, как производить вставку данных в таблицы.
Для выполнения INSERT, UPDATE и DELETE запросов используется уже знакомый нам тип запроса — Query. Однако теперь для выполнения запроса вместо метода fetch_* применяется метод execute.
Рассмотрим пример:
use sqlx::{postgres::{PgPoolOptions, PgQueryResult}, types::BigDecimal};
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let result: PgQueryResult = sqlx::query(
"INSERT INTO accounts(owner_name, balance) VALUES($1, $2)"
)
.bind("Some Name")
.bind(BigDecimal::default())
.execute(&pool).await.unwrap();
println!("{result:?}"); // PgQueryResult { rows_affected: 1 }
}Метод execute возвращает объект структуры PgQueryResult, хранящий число фактически вставленных/изменённых записей.
Если у нас имеется целая коллекция сущностей, которые мы хотим вставить в таблицу, то нам будет удобно воспользоваться типом QueryBuilder, работа с которым имеет вид:
struct Сущность { // Тип сущности, ассоциированной с таблицей в БД
поле1: Тип1,
поле2: Тип2,
поле3: Тип3,
}
// Создаём объект QueryBuilder с заголовком INSERT запроса
let mut qb = QueryBuilder::new(r#"INSERT INTO таблица(поле1, поле2, поле3)"#);
let вектор_сущностей: Vec<Сущность> = ...; // коллекция сущностей для вставки
qb.push_values(&вектор_сущностей, |mut builder, сущность| {
// привязываем поля сущностей к колонкам из заголовка INSERT запроса
builder
.push_bind(&сущность.поле1)
.push_bind(&сущность.поле2)
.push_bind(&сущность.поле3);
});
qb.build().execute(&pool).await.unwrap(); // выполняем запросДля примера рассмотрим программу, которая вставляет в таблицу accounts несколько новых записей:
use sqlx::{
Postgres, QueryBuilder, types::BigDecimal,
postgres::{PgPoolOptions, PgQueryResult}
};
struct NewAcc {
owner_name: String,
balance: BigDecimal,
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb")
.await
.unwrap();
let new_accounts = vec![
NewAcc {owner_name: "Name 1".to_string(), balance: BigDecimal::default()},
NewAcc {owner_name: "Name 2".to_string(), balance: BigDecimal::default()},
NewAcc {owner_name: "Name 3".to_string(), balance: BigDecimal::default()},
];
let mut qb: QueryBuilder<'_, Postgres> =
QueryBuilder::new(r#"INSERT INTO accounts(owner_name, balance)"#);
qb.push_values(&new_accounts, |mut builder, acc| {
builder
.push_bind(&acc.owner_name)
.push_bind(&acc.balance);
});
let result: PgQueryResult = qb.build().execute(&pool).await.unwrap();
println!("{result:?}"); // PgQueryResult { rows_affected: 3 }
}Транзакции
Теперь давайте разберёмся, как в SQLx работать с транзакциями.
Транзакцию можно создать путём вызова метода begin на объекте пула соединений к БД. Этот вызов вернёт объект типа Transaction, который инкапсулирует транзакцию. Далее этот объект транзакции можно использовать вместо пула соединений (Pool) для выполнения запросов в методах fetch_all, fetch_one, execute и т.д. Все запросы, выполненные на объекте транзакции, будут выполнены в рамках этой транзакции.
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new().connect("PG_URL").await.unwrap();
let mut tx = pool.begin().await.expect("Cannot start transaction");
sqlx::query("UPDATE ...").execute(&mut *tx).await?;
sqlx::query("INSERT ...").execute(&mut *tx).await?;
sqlx::query("DELETE ...").execute(&mut *tx).await?;
tx.commit().await.expect("Cannot commit");
}Как это работает?
Для начала, если мы посмотрим на сигнатуру метода Query::execute, то увидим, что в качестве аргумента он принимает не пул соединений (Pool), а некий Executor. Не вдаваясь в подробности, скажем просто, что и Pool, и Transaction реализуют этот трэйт Executor. Именно поэтому запросы можно исполнять как на объекте пула соединений, так и на объекте транзакции.
Теперь разберёмся с самим типом Transaction. Он работает следующим образом:
- Когда мы вызываем на пуле соединений метод
begin(), то из пула выбирается соединение, в которое сразу отправляется вызовBEGIN TRANSACTION. - Вызов метода
commit()приведёт к тому, что в соединение будет отправленоCOMMIT, что в свою очередь закрепит транзакцию. - Если объект
Transactionбудет уничтожен до того, как на нём будет вызван методcommit(), то его деструктор отправит в соединение с БД командуROLLBACK.
В качестве примера рассмотрим функцию, которая совершает пересылку денег с одного аккаунта на другой. Эта функция должна транзакционно совершить три операции:
- снять деньги со счёта отправителя
- добавить деньги на счёт получателя
- создать запись о произошедшей транзакции
use bigdecimal::FromPrimitive;
use sqlx::{PgPool, postgres::PgPoolOptions, types::BigDecimal};
struct Transfer {
src_account_id: i64,
dst_account_id: i64,
amount: BigDecimal,
}
async fn make_transfer(transfer: &Transfer, pool: &PgPool) -> Result<(),sqlx::Error> {
// Начинаем транзакцию
let mut tx = pool.begin().await?;
// Добавляем сумму трансфера к балансу получателя
let _ = sqlx::query("UPDATE accounts SET balance = balance + $1 WHERE id = $2")
.bind(&transfer.amount)
.bind(&transfer.dst_account_id)
.execute(&mut *tx)
.await?;
// Уменьшаем баланс отправителя на сумму трансфера
let _ = sqlx::query("UPDATE accounts SET balance = balance - $1 WHERE id = $2")
.bind(&transfer.amount)
.bind(&transfer.src_account_id)
.execute(&mut *tx)
.await?;
// Создаём новую запись о транзакции по пересылке денег
let _ = sqlx::query(r#"
INSERT INTO transactions(
amount, src_account_id, dst_account_id, tx_timestamp
) VALUES ($1, $2, $3, NOW())
"#)
.bind(&transfer.amount)
.bind(&transfer.src_account_id)
.bind(&transfer.dst_account_id)
.execute(&mut *tx)
.await?;
// Закрепляем транзакцию
tx.commit().await?;
Ok(())
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let transfer = Transfer {
src_account_id: 1,
dst_account_id: 2,
amount: BigDecimal::from_f64(50.0).unwrap()
};
let _ = make_transfer(&transfer, &pool).await.unwrap();
}Теперь, если мы посмотрим на таблицы accounts и transactions, то увидим изменения, сделанные программой:
mydb=# select * from accounts;
id | owner_name | balance
----+-------------+---------
1 | John Doe | 950.00
2 | Ivan Ivanov | 2050.00
mydb=# select * from transactions;
id | amount | src_account_id | dst_account_id | tx_timestamp
----+--------+----------------+----------------+----------------------------
1 | 10.00 | 1 | 2 | 2025-12-11 14:00:00
2 | 20.00 | 2 | 1 | 2025-12-12 15:00:00
3 | 50.00 | 1 | 2 | 2025-12-13 02:00:22.788004
Чтобы увидеть, как происходит откат транзакции, давайте попытаемся сделать перевод суммы, которая превышает текущий баланс на счету отправителя. Это вызовет срабатывание ограничения CHECK (balance > 0) в таблице accounts.
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let transfer = Transfer {
src_account_id: 1,
dst_account_id: 2,
amount: BigDecimal::from_f64(5000.0).unwrap() // На аккаунте нет столько денег
};
let _ = make_transfer(&transfer, &pool).await.unwrap();
}Как видите, мы попытались перевести 5000, что привело к тому, что вторая UPDATE операции (та, которая вычитает сумму со счета отправителя) в функции make_transfer завершилась с ошибкой.
Database(PgDatabaseError {
severity: Error, code: "23514",
message: "new row for relation 'accounts' violates check constraint 'accounts_balance_check'",
detail: Some("Failing row contains (1, John Doe, -4050.00)."),
schema: Some("public"),
table: Some("accounts"),
constraint: Some("accounts_balance_check"),
routine: Some("ExecConstraints")
})
Транзакция при этом была полностью откачена.
Версионирование структуры БД
SQLx предлагает утилиту командной строки sqlx-cli, которая позволяет:
- вычитывать метаданные из БД и валидировать SQL запросы на этапе компиляции
- быстро создавать и удалять тестовую БД
- версионировать структуры БД, что часто еще называют миграцией
Именно версионирование структуры БД мы рассмотрим в этой главе.
Для начала нам потребуется установить саму утилиту при помощи команды:
cargo install sqlx-cli
Теперь давайте перенесём в файлы миграции наш SQL-скрипт для создания таблиц из прошлой главы.
Создадим первый файл при помощи команды:
cargo sqlx migrate add accounts -r --sequential
Эта команда создаст два пустых файла:
migrations/0001_accounts.up.sql— файл для изменения структуры БДmigrations/0001_accounts.down.sql— файл для отката изменений
Откроем 0001_accounts.up.sql и напишем в нём следующее:
CREATE SEQUENCE accounts_seq START WITH 1000;
CREATE TABLE accounts ( -- mydb.public.accounts
id BIGINT PRIMARY KEY DEFAULT nextval('accounts_seq'),
owner_name VARCHAR(255) NOT NULL UNIQUE,
balance NUMERIC(10, 2) NOT NULL DEFAULT 0.00 CHECK (balance >= 0)
);
Далее 0001_accounts.down.sql:
DROP TABLE accounts;
DROP SEQUENCE accounts_seq;
Теперь создадим следующую пару файлов для таблицы transactions.
Можно также сделать это командой cargo sqlx migrate add transactions -r --sequential, но можно и создать файлы 0002_transactions.up.sql и 0002_transactions.down.sql вручную.
Заполним 0002_transactions.up.sql:
CREATE SEQUENCE transactions_seq START WITH 1000;
CREATE TABLE transactions ( -- mydb.public.transactions
id BIGINT PRIMARY KEY DEFAULT nextval('transactions_seq'),
amount NUMERIC(10, 2) DEFAULT 0.00,
src_account_id BIGINT NOT NULL,
dst_account_id BIGINT NOT NULL,
tx_timestamp TIMESTAMP NOT NULL,
FOREIGN KEY (src_account_id) REFERENCES accounts (id),
FOREIGN KEY (dst_account_id) REFERENCES accounts (id)
);
И затем 0002_transactions.down.sql:
DROP TABLE transactions;
DROP SEQUENCE transactions_seq;
Теперь, чтобы протестировать нашу миграцию, давайте создадим новую БД — my_migration.
CREATE DATABASE my_migration;
После создания БД запустим миграцию:
$ cargo sqlx migrate run \
--database-url postgres://postgres:1111@localhost/my_migration
Applied 1/migrate accounts (3.99736ms)
Applied 2/migrate transactions (4.774571ms)
В базе данных должны появиться три таблицы:
accountstransactions_sqlx_migrations
Таблица _sqlx_migrations является служебной таблицей SQLx и хранит метаданные применённых миграций. Механизм миграции использует эту таблицу, чтобы знать, какие миграции были уже выполнены. Таблица хранит номера применённых миграций, имена соответствующих выполненных файлов миграции, время выполнения, а также контрольную сумму файла миграции (нужна для проверки того, не был ли изменён “задним числом” файл от уже применённой миграции).
> select * from _sqlx_migrations;
version | description | installed_on | success | checksum | execution_time
---------+------------- +---------------------+---------+---------------------------
1 | accounts | 2025-12-12 02:19:32 | t | \x3124df | 3997360
2 | transactions | 2025-12-12 02:19:32 | t | \xaded4e | 4774571
Как мы видим, обе наши миграции были успешно применены.
Утилита cargo sqlx migrate позволяет не только применять миграции, но и откатывать их. Например, давайте откатим структуру БД до версии 1, то есть к моменту, когда уже была создана таблица accounts, но еще не была создана таблица transactions.
$ cargo sqlx migrate revert \
--target-version 1 \
--database-url postgres://postgres:1111@localhost/my_migration
Applied 2/revert transactions (3.658186ms)
Skipped 1/revert accounts (0ns)
Если мы проверим, какие таблицы есть в БД my_migration, то мы увидим, что таблица transactions пропала.
Если мы запустим миграцию еще раз, то таблица transactions будет создана опять.
$ cargo sqlx migrate run \
--database-url postgres://postgres:1111@localhost/my_migration
Applied 2/migrate transactions
Тест контейнеры
Считается, что полноценное интеграционное тестирование функциональности, взаимодействующей с базой данных, нужно производить только с использованием реального сервера СУБД. Однако устанавливать и подготавливать сервер PostgreSQL отдельно для тестов — очень неудобно, особенно, если речь идёт о тестировании на CI сервере. Именно поэтому для тестирования работы с СУБД, как правило, используют Docker контейнер с нужным СУБД сервером.
Существует популярная библиотека Testcontainers, которая значительно упрощает интеграционное тестирование с реальными системами, так как берёт на себя всю рутину по:
- запуску тестового контейнера в начале теста
- взаимодействию с контейнером
- завершению работы контейнера после окончания теста
Tip
Если вы писали бэкенд приложения на Java, C#, Python, Ruby и т.д., то вы, скорее всего, уже сталкивались с вариацией библиотеки Testcontainers для вашего языка.
На основе структуры БД, созданной в предыдущих главах, напишем простую программу, которая сначала добавляет в БД новый аккаунт, а потом вычитывает все аккаунты из БД, и печатает их на консоль.
Для этого мы напишем две функции:
fetch_accounts()— вычитывает все аккаунты из БДinsert_accounts(owner_name, initial_balance)— вставляет новый аккаунт с заданным именем и начальным балансом
Однако в этот раз нас больше интересует не сама программа, а тестирование функций, взаимодействующих с БД. Тест, который мы напишем при помощи Testcontainers, будет:
- Поднимать новый контейнер с PostgreSQL
- При помощи SQLx миграции создавать таблицы в базе данных
- Вызывать функцию
insert_accounts, чтобы вставить новый аккаунт - Вызывать функцию
fetch_accounts, и проверять, что результат содержит только что созданный аккаунт
Для начала добавим зависимость на testcontainers, в Cargo.toml:
[package]
name = "test_sqlx"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"] }
sqlx = {version = "0.8", features = ["postgres", "chrono", "runtime-tokio", "bigdecimal"]}
chrono = "0.4"
bigdecimal = { version = "0.4", features = ["serde"]}
[dev-dependencies]
testcontainers = "0.26"
Скопируйте файлы миграции из проекта из прошлой главы Версионирование структуры БД, после чего дерево файлов проекта должно выглядеть так:
/
├── Cargo.toml
├── src/
│ └── main.rs
└── migrations/
├── 0001_accounts.down.sql
├── 0001_accounts.up.sql
├── 0002_transactions.down.sql
└── 0002_transactions.up.sql
Теперь наш src/main.rs:
use bigdecimal::{BigDecimal, FromPrimitive};
use serde::{Deserialize, Serialize};
use sqlx::{FromRow, PgPool, postgres::PgPoolOptions};
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
insert_accounts(&pool, "John Doe", BigDecimal::from_i32(1000).unwrap())
.await.unwrap();
let accounts = fetch_accounts(&pool).await.unwrap();
println!("{accounts:?}");
}
#[derive(Debug, Serialize, Deserialize, FromRow)]
pub struct Account {
id: i64,
owner_name: String,
balance: BigDecimal,
}
pub async fn fetch_accounts(db: &PgPool) -> Result<Vec<Account>, sqlx::Error> {
sqlx::query_as("SELECT id, owner_name, balance FROM accounts")
.fetch_all(db)
.await
}
pub async fn insert_accounts(
db: &PgPool, owner_name: &str, initial_balance: BigDecimal
) -> Result<(), sqlx::Error> {
sqlx::query("INSERT INTO accounts(owner_name, balance) VALUES($1, $2)")
.bind(owner_name)
.bind(initial_balance)
.execute(db)
.await?;
Ok(())
}
#[cfg(test)]
mod test {
use super::*;
use sqlx::{migrate::Migrator, postgres::{PgConnectOptions, PgPoolOptions}};
use testcontainers::{
core::{IntoContainerPort, WaitFor},
runners::AsyncRunner, GenericImage, ImageExt
};
#[tokio::test]
async fn test_create_account() {
// Запуск контейнера с PostgreSQL
let container = GenericImage::new("postgres", "18")
.with_wait_for(WaitFor::message_on_stderr(
"database system is ready to accept connections"
))
.with_exposed_port(5432.tcp())
.with_env_var("POSTGRES_PASSWORD", "1111")
.start()
.await
.expect("Postgres started");
// Подключение к БД в контейнере
let connection_options = PgConnectOptions::new()
.host(&container.get_host().await.unwrap().to_string())
.port(container.get_host_port_ipv4(5432).await.unwrap())
.database("postgres")
.username("postgres")
.password("1111");
let pool = PgPoolOptions::new()
.connect_with(connection_options).await.unwrap();
// Создание таблиц в базе данных при помощи скриптов SQLx миграции
Migrator::new(std::path::Path::new("./migrations")).await.unwrap()
.run(&pool).await.unwrap();
// Вставляем новый аккаунт
insert_accounts(&pool, "Test-Account-1", BigDecimal::from_i32(1000).unwrap())
.await.unwrap();
// Вычитываем все аккаунты
let accounts = fetch_accounts(&pool).await.unwrap();
// Проверяем правильность ответа из БД
assert_eq!(accounts.len(), 1);
assert_eq!(accounts[0].owner_name, "Test-Account-1".to_string());
assert_eq!(accounts[0].balance, BigDecimal::from_i32(1000).unwrap());
}
}Запустите тест командой cargo test:
running 1 test
test test::test_create_account ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 2.58s
Теперь давайте разберём участок кода, где создаётся контейнер:
let container = GenericImage::new("postgres", "18")
.with_wait_for(WaitFor::message_on_stderr(
"database system is ready to accept connections"
))
.with_exposed_port(5432.tcp())
.with_env_var("POSTGRES_PASSWORD", "1111")
.start()
.await
.expect("Postgres started");Здесь:
GenericImage::new("postgres", "18")— указывает, что мы хотим создать контейнер на основе образа postgres из https://hub.docker.com/. Аргумент"18"— это тег образа..with_wait_for— задаёт условие, которого необходимо дождаться перед тем, как с контейнером можно будет начинать работать. В нашем случае мы ожидаем момент, когда postgresql сервер внутри контейнера, напечатает в консоль строку “database system is ready to accept connections”..with_exposed_port(5432.tcp())— указывает, что мы хотим отобразить порт 5432 из контейнера на случайный свободный порт на хостовой системе. Номер порта на хостовой системе можно будет получить из объекта контейнера..with_env_var("POSTGRES_PASSWORD", "1111")— проталкивает в контейнер переменную окруженияPOSTGRES_PASSWORD, равную1111. Согласно документации образа на Docker hub странице, таким способом мы задаём пароль для базы данных в контейнере. Логин по умолчанию — “postgres”
Аналогичным образом можно поднять и любой другой, доступный на Docker hub образ. По завершению теста, все контейнеры будут автоматически потушены, даже если тест завершился с ошибкой.
Testcontainers Modules
В пару к крэйту testcontainers существует еще крэйт testcontainers-modules, который содержит удобные обёртки для популярных Docker образов. Разумеется, обёртка для PostgreSQL образа присутствует среди них.
Добавим в Cargo.toml зависимость на testcontainers-modules:
[dev-dependencies]
testcontainers = "0.26"
testcontainers-modules = { version = "0.14", features = ["postgres"] }
После этого можно запустить контейнер так:
// Запуск контейнера с PostgreSQL
let container = testcontainers_modules::postgres::Postgres::default()
.with_password("1111")
.start().await.unwrap();
// Подключение к БД в контейнере
let connection_options = PgConnectOptions::new()
.host(&container.get_host().await.unwrap().to_string())
.port(container.get_host_port_ipv4(5432).await.unwrap())
.database("postgres")
.username("postgres")
.password("1111");Как видите, код запуска postgresql контейнера стал заметно короче и проще.
Также testcontainers-modules предлагает подобные обёртки для Anvil, Azurite, CockroachDB, Clickhouse, Consul, DynamoDB, ElasticSearch, Kafka, Localstack, Minio, MongoDB, MS SQL Server, MySQL, Nats, Neo4J, OpenLDAP, Oracle, OrientDB, RabbitMQ, Redis, RQLitem Scylladb, Solr, SurrealDB и Zookeeper.
SQLx макросы
Будучи языком со строгой статической типизацией, Rust пытается обнаружить максимум ошибок еще на этапе компиляции. Однако если мы сделаем ошибку в тексте SQL запроса, то узнаем мы об этом только во время его исполнения. Хорошей практикой является написание интеграционных тестов с реальной СУБД для всех запросов, однако это не единственный способ уберечься от ошибок в SQL.
Утилита cargo sqlx, с которой мы познакомились в прошлой главе, имеет возможность подключиться к базе данных и проверить корректность кода SQL запросов. Принцип работы следующий:
- Вместо функций
query_as,query_scalarиqueryмы должны использовать соответствующие макросы: query_as!, query_scalar! и query!. Эти макросы работают по тому же принципу, что и их собратья-функции.
Сразу после написания кода с этими макросами компилятор будет на них ругаться и рекомендовать запустить командуcargo sqlx prepare - Поэтому запускаем эту команду:
cargo sqlx prepare --database-url postgres://postgres:1111@localhost/mydb
Утилита sqlx подключится к базе данных и с её помощью провалидирует все SQL запросы, используемые в макросахquery_as!,query_scalar!иquery!.
Также утилита создаст каталог.sqlx/, в который сложит JSON файлы с метаинформацией о проверенных запросах. - При компиляции приложения макросы
query_as!,query_scalar!иquery!будут валидировать текст SQL запросов, используя метаинформацию из каталога.sqlx.
Таким образом, мы получим проверку корректности SQL запросов на этапе компиляции.
query_as!, query_scalar! и query!
Формат использования макроса query_as! практически такой же, как и функции query_as, но с минимальными отличиями:
struct ТипРезультата {
поле1: Тип1,
поле2: Тип2,
поле3: Тип3,
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new().connect("PG_URL").await.unwrap();
let query = sqlx::query_as!(
ТипРезультата,
"SELECT поле1, поле2, поле3 FROM таблица WHERE поле1 = $1 AND поле2 = $2",
ЗначениеАргумента$1,
ЗначениеАргумента$2,
);
let result: Vec<ТипРезультата> = query.fetch_all(&pool).await.unwrap();
}Как видите, структура, в объекты которой конвертируется результат, больше не должна реализовывать трэйт FromRow. Это логично: макрос выполняется на этапе компиляции, поэтому у него и так есть доступ к полям структуры.
Также макрос sqlx::query_as! принимает минимум два аргумента: структура, в виде объектов которой будет представлен результат запроса, и сам SQL запрос. Напомним, функция query_as имеет только один аргумент — SQL запрос.
Если код запроса содержит аргументы, то значения для них передаются сразу после самого запроса, в то время как с функциями мы использовали метод bind на объекте Query.
Используя макрос, перепишем наш пример использования query_as из прошлой главы.
use sqlx::{postgres::PgPoolOptions, types::BigDecimal};
#[derive(Debug)]
struct Account {
id: i64,
owner_name: String,
balance: BigDecimal,
}
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let all_accounts: Vec<Account> = sqlx::query_as!(
Account,
"SELECT id, owner_name, balance FROM accounts"
).fetch_all(&pool).await.unwrap();
for acc in all_accounts {
println!("{}: {}, {}", acc.id, acc.owner_name, acc.balance.to_string());
}
let opt_acc_1: Option<Account> = sqlx::query_as!(
Account,
"SELECT id, owner_name, balance FROM accounts WHERE owner_name=$1",
"John Doe" // Значение для аргумента $1
)
.fetch_optional(&pool)
.await.unwrap();
if let Some(acc) = opt_acc_1 {
println!("{}: {}, {}", acc.id, acc.owner_name, acc.balance.to_string());
}
}Теперь выполняем команду:
$ cargo sqlx prepare --database-url postgres://postgres:1111@localhost/mydb
query data written to .sqlx in the current directory;
please check this into version control
Если команда cargo sqlx prepare завершилась успешно, то можно запустить программу:
$ cargo run
1: John Doe, 1000
2: Ivan Ivanov, 2000
1: John Doe, 1000
Макрос query_scalar! работает по тому же принципу:
use sqlx::{postgres::PgPoolOptions};
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let account_ids: Vec<i64> = sqlx::query_scalar!("SELECT id FROM accounts")
.fetch_all(&pool).await.unwrap();
println!("All IDs: {account_ids:?}");
let accounts_count: Option<i64> = sqlx::query_scalar!(
"SELECT COUNT(*) FROM accounts"
)
.fetch_one(&pool).await.unwrap();
println!("Number of accounts: {}", accounts_count.unwrap_or_default());
}После выполнения cargo sqlx prepare, запускаем приложение:
$ cargo run
All IDs: [1, 2]
Number of accounts: 2
И макрос query!, как вы уже могли догадаться, тоже работает по той же самой схеме:
use sqlx::{postgres::{PgPoolOptions, PgQueryResult}, types::BigDecimal};
#[tokio::main]
async fn main() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let result: PgQueryResult = sqlx::query!(
"INSERT INTO accounts(owner_name, balance) VALUES($1, $2)",
"Some Name",
BigDecimal::default(),
)
.execute(&pool).await.unwrap();
println!("{result:?}"); // PgQueryResult { rows_affected: 1 }
}После выполнения cargo sqlx prepare, запускаем приложение:
$ cargo run
PgQueryResult { rows_affected: 1 }
query* функции vs. query*! макросы
После прочтения этой главы у вас, скорее всего, возник вопрос: “Когда следует использовать макросы, а когда — просто функции?”.
Распространено мнение, что функции следует использовать только в ситуациях, когда SQL конструируется динамически во время выполнения программы, а во всех остальных случаях следует использовать макросы.
На практике же макросы не являются абсолютной защитой от некорректного SQL, так как структура БД, относительно которой вы выполнили cargo sqlx prepare, может, ввиду разных обстоятельств, оказаться не такой, какая будет в итоге у продакшн базы данных. Поэтому, в первую очередь, важно покрывать интеграционными тестами всю функциональность, которая работает с БД.
Также следует заметить, что макросы не дают никакого преимущества в плане скорости выполнения, так как компилируются в те же структуры, которые создают их собратья-функции.
Axum и SQLx
Теперь, когда мы разобрались, как работать с SQLx, давайте посмотрим, как использовать его совместно с Axum.
Расширим наш test_sqlx проект (который мы создали в главе SQLx), добавив в него Axum-сервер. Для простоты примера пускай наш сервер будет предоставлять только два эндпоинта:
GET /accounts— получить список всех аккаунтовPOST /account— создать новый аккаунт
Сначала добавим axum зависимость в Cargo.toml:
[package]
name = "test_sqlx"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"] }
sqlx = {version = "0.8", features = ["postgres", "chrono", "runtime-tokio", "bigdecimal"]}
chrono = "0.4"
bigdecimal = { version = "0.4", features = ["serde"]}
axum = "0.8"
serde = { version = "1", features = ["derive"] }
serde_json = "1"
Теперь создадим пустые файлы — заготовки под модули:
persist.rs— для кода взаимодействия с БДserver.rs— для кода HTTP сервера
В результате у нас должно получиться такое дерево файлов:
test_sqlx/
├── Cargo.toml
├── src/
│ ├── persist.rs
│ ├── server.rs
│ └── main.rs
└── migrations/
├── 0001_accounts.down.sql
├── 0001_accounts.up.sql
├── 0002_transactions.down.sql
└── 0002_transactions.up.sql
Сначала напишем функциональность для работы с базой данных. У нас будет две функции:
- для выборки всех аккаунтов из таблицы
accounts - для вставки нового аккаунта
Итак, наш файл src/persist.rs:
use bigdecimal::BigDecimal;
use serde::{Deserialize, Serialize};
use sqlx::{FromRow, PgPool};
#[derive(Debug, Serialize, Deserialize, FromRow)]
pub struct Account {
id: i64,
owner_name: String,
balance: BigDecimal,
}
pub async fn fetch_accounts(db: &PgPool) -> Result<Vec<Account>, sqlx::Error> {
sqlx::query_as("SELECT id, owner_name, balance FROM accounts")
.fetch_all(db)
.await
}
pub async fn create_accounts(
db: &PgPool, owner_name: &str, initial_balance: BigDecimal
) -> Result<Account, sqlx::Error> {
let mut tx = db.begin().await?;
// Вставляем новый аккаунт
sqlx::query("INSERT INTO accounts(owner_name, balance) VALUES($1, $2)")
.bind(owner_name)
.bind(initial_balance)
.execute(&mut *tx)
.await?;
// Вычитываем только что вставленную запись.
// Функция currval(имя сиквенса), которая возвращает
// последнее полученное значение сиквенса,
// должна быть вызвана в той же сессии, что и INSERT запрос,
// использовавший этот сиквенс. Поэтому мы используем транзакцию.
let result = sqlx::query_as(r#"
SELECT id, owner_name, balance
FROM accounts
WHERE id = currval('accounts_seq')
"#)
.fetch_one(&mut *tx)
.await?;
tx.commit().await?;
Ok(result)
}Теперь код нашего сервера. Для того чтобы эндпоинты могли использовать базу данных, мы просто поместим объект пула соединений с БД в объект состояния.
Таким образом файл src/server.rs будет иметь вид:
use std::sync::Arc;
use axum::{Json, Router, extract::State, http::StatusCode, routing::{get, post}};
use serde::Deserialize;
use sqlx::{PgPool, postgres::PgPoolOptions, types::BigDecimal};
use crate::persist::{self, Account};
struct AppState {
db: PgPool,
}
/// Создаёт и запускает Axum сервер
pub async fn run_server() {
let pool = PgPoolOptions::new()
.connect("postgres://postgres:1111@localhost/mydb").await.unwrap();
let state = AppState { db: pool };
let app = Router::new()
.route("/accounts", get(list_accounts))
.route("/accounts", post(create_new_account))
.with_state(Arc::new(state)); // Помещаем пул соединений к БД в состояние
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
#[derive(Deserialize)]
struct NewAcc {
owner_name: String,
init_balance: BigDecimal,
}
async fn list_accounts(
state: State<Arc<AppState>>
) -> Result<Json<Vec<Account>>, (StatusCode, String)> {
// Извлекаем объект пула соединений из состояния, и используем его для
// вызова функции, которая вычитывает все аккаунты из БД.
match persist::fetch_accounts(&state.db).await {
Ok(accounts) => Ok(Json(accounts)),
Err(e) => Err((StatusCode::INTERNAL_SERVER_ERROR, e.to_string())),
}
}
async fn create_new_account(
state: State<Arc<AppState>>, Json(acc): Json<NewAcc>
) -> Result<Json<Account>, (StatusCode, String)> {
match persist::create_accounts(&state.db, &acc.owner_name, acc.init_balance).await {
Ok(account) => Ok(Json(account)),
Err(e) => Err((StatusCode::INTERNAL_SERVER_ERROR, e.to_string())),
}
}В главном файле src/main.rs мы просто вызовем функцию запуска сервера:
mod persist;
mod server;
#[tokio::main]
async fn main() {
server::run_server().await
}Для чистоты эксперимента удалим из таблиц transactions и accounts все записи, которые остались от примеров из предыдущих глав.
Если вы использовали Docker, чтобы запускать сервер Postgres, то можете воспользоваться командами:
docker start my_pg_container— запустить контейнер, если он неактивенdocker exec -it my_pg_container bash— запустить консоль в контейнереpsql -U postgres— подключиться к самой БД\c mydb;— выбрать mydb как текущую базу данныхdelete from transactions; delete from accounts;— очистить таблицы
Теперь запустим наше приложение.
cargo run
Сначала вызовем эндпоинт, возвращающий все аккаунты. Так как мы только что удалили все записи из таблиц, то ответом должен быть пустой список:
$ curl -i http://localhost:8080/accounts
HTTP/1.1 200 OK
content-type: application/json
content-length: 2
date: Sat, 03 Jan 2026 02:02:18 GMT
[]
Теперь добавим новый аккаунт:
$ curl -i -X POST \
-H "Content-Type: application/json" \
-d '{"owner_name": "Acc-1", "init_balance": 1000.0}' \
http://localhost:8080/accounts
</strong>HTTP/1.1 200 OK
content-type: application/json
content-length: 49
date: Sat, 03 Jan 2026 02:02:20 GMT
{"id":1000,"owner_name":"Acc-1","balance":"1000"}
Снова вызовем эндпоинт, возвращающий все аккаунты.
$ curl -i http://localhost:8080/accounts
HTTP/1.1 200 OK
content-type: application/json
content-length: 51
date: Sat, 03 Jan 2026 02:02:22 GMT
[{"id":1000,"owner_name":"Acc-1","balance":"1000"}]
Всё работает, как и ожидалось.
Как видите, объект состояния — именно то место, где предпочтительно хранить долгоживущие сущности, которые могут использоваться разными эндпоинтами.
Структура бекенда
К этому моменту мы уже умеем создавать HTTP сервер, работать с базой данных и знаем, как тестировать эндопоинты и функциональность, работающую с БД. Давайте теперь рассмотрим, как всё это обычно компонуют в реальных проектах.
Создание проекта
Мы создадим многомодульный (workspace) проект, состоящий из следующих крэйтов:
persist— Слой работы с базой данных: библиотека с функциями для работы с БД.server— Слой веб сервера: исполняемое приложение, которое для работы с хранилищем импортирует библиотекуpersist.
1) В удобном для вас месте создайте новую директорию test_backend.
2) В директории test_backend/ создайте файл Cargo.toml со следующим содержимым:
[workspace]
resolver = "3"
Корневой workspace готов. Теперь можно добавлять дочерние крэйты.
3) Откройте консоль в директории test_backend/ и создайте модули persist и server:
cargo new persist --lib
cargo new server
После этого корневой Cargo.toml должен иметь содержимое:
[workspace]
resolver = "3"
members = ["persist", "server"]
4) В корневом Cargo.toml объявите зависимости, которые мы будем использовать в дочерних крэйтах:
[workspace]
members = ["server", "persist"]
[workspace.dependencies]
async-trait = "0.1"
thiserror = "1"
tokio = { version = "1", features = ["full"] }
sqlx = {version = "0.8", features = ["postgres", "chrono", "runtime-tokio", "bigdecimal"]}
chrono = "0.4"
bigdecimal = { version = "0.4", features = ["serde"]}
axum = "0.8"
serde = { version = "1", features = ["derive"] }
serde_json = "1"
axum-test = "18"
testcontainers = "0.26"
testcontainers-modules = { version = "0.14", features = ["postgres"] }
Чтобы вам проще было ориентироваться, финальная структура проекта будет такой:
test_backend/
├── Cargo.toml
├── persist
│ ├── Cargo.toml
│ ├── src/
│ │ └── lib.rs
│ └── tests/
│ └── account_storage_tests.rs
├── server
│ ├── Cargo.toml
│ ├── src/
│ │ ├── service.rs
│ │ ├── endpoints.rs
│ │ ├── lib.rs
│ │ └── main.rs
│ └── tests/
│ └── endpoints_tests.rs
└── migrations/
├── 0001_accounts.down.sql
├── 0001_accounts.up.sql
├── 0002_transactions.down.sql
└── 0002_transactions.up.sql
Крэйт persist
Сначала добавим все необходимые зависимости в persist/Cargo.toml:
[package]
name = "persist"
version = "0.1.0"
edition = "2024"
[dependencies]
async-trait = { workspace = true }
sqlx = { workspace = true }
chrono = { workspace = true }
bigdecimal = { workspace = true }
serde = { workspace = true }
[dev-dependencies]
tokio = { workspace = true }
testcontainers = { workspace = true }
testcontainers-modules = { workspace = true }
Весь код крэйта будет в файле persist/src/lib.rs:
use bigdecimal::BigDecimal;
use serde::{Deserialize, Serialize};
use sqlx::{FromRow, PgPool, postgres::PgPoolOptions};
#[derive(Debug, Serialize, Deserialize, FromRow)]
pub struct Account {
pub id: i64,
pub owner_name: String,
pub balance: BigDecimal,
}
// Интерфейс для работы с хранилищем
#[async_trait::async_trait]
pub trait Storage {
async fn fetch_accounts(&self) -> Result<Vec<Account>, sqlx::Error>;
async fn create_accounts(
&self, owner_name: &str, initial_balance: BigDecimal
) -> Result<Account, sqlx::Error>;
}
pub struct StorageImpl {
db: PgPool,
}
impl StorageImpl {
pub fn new(db: PgPool) -> StorageImpl {
StorageImpl { db }
}
pub async fn from_connection_url(url: &str) -> Result<StorageImpl, sqlx::Error> {
let pool = PgPoolOptions::new()
.connect(url).await?;
Ok(StorageImpl { db: pool })
}
}
#[async_trait::async_trait]
impl Storage for StorageImpl {
async fn fetch_accounts(&self) -> Result<Vec<Account>, sqlx::Error> {
sqlx::query_as("SELECT id, owner_name, balance FROM accounts")
.fetch_all(&self.db)
.await
}
async fn create_accounts(
&self, owner_name: &str, initial_balance: BigDecimal
) -> Result<Account, sqlx::Error> {
let mut tx = self.db.begin().await?;
sqlx::query("INSERT INTO accounts(owner_name, balance) VALUES($1, $2)")
.bind(owner_name)
.bind(initial_balance)
.execute(&mut *tx)
.await?;
let result = sqlx::query_as(r#"
SELECT id, owner_name, balance
FROM accounts
WHERE id = currval('accounts_seq')
"#)
.fetch_one(&mut *tx)
.await?;
tx.commit().await?;
Ok(result)
}
}Добавим интеграционный тест для функциональности, работающей с базой данных — persist/tests/account_storage_tests.rs:
use bigdecimal::{BigDecimal, FromPrimitive};
use persist::{Storage, StorageImpl};
use sqlx::{migrate::Migrator, postgres::{PgConnectOptions, PgPoolOptions}};
use testcontainers::runners::AsyncRunner;
#[tokio::test]
async fn test_create_and_fetch_account() {
let container = testcontainers_modules::postgres::Postgres::default()
.with_password("1111")
.start().await.unwrap();
let connection_options = PgConnectOptions::new()
.host(&container.get_host().await.unwrap().to_string())
.port(container.get_host_port_ipv4(5432).await.unwrap())
.database("postgres")
.username("postgres")
.password("1111");
let pool = PgPoolOptions::new()
.connect_with(connection_options).await.unwrap();
Migrator::new(std::path::Path::new("../migrations")).await.unwrap()
.run(&pool).await.unwrap();
// Тестируемый объект хранилища
let sut = StorageImpl::new(pool);
// Изначально таблица с аккаунтами пуста
let accounts = sut.fetch_accounts().await.unwrap();
assert!(accounts.is_empty());
// Создаём новый аккаунт
let created_acc = sut.create_accounts(
"Test-Account-1", BigDecimal::from_f64(1000.0).unwrap()
).await
.unwrap();
// Выбираем все аккаунты, чтобы убедиться, что свежесозданный аккаунт присутствует
let accounts = sut.fetch_accounts().await.unwrap();
assert_eq!(accounts.len(), 1);
assert_eq!(accounts[0].id, created_acc.id);
assert_eq!(accounts[0].owner_name, created_acc.owner_name);
assert_eq!(accounts[0].balance, created_acc.balance);
}Note
Как вы могли заметить, переменная, которая содержит тестируемый объект типа
StorageImpl, называется sut. Аббревиатура SUT расшифровывается как System Under Test — тестируемая система. Использование имениsutдля тестируемой сущности, облегчает чтение кода теста.
Крэйт server
Теперь крэйт сервера, который использует крэйт persist в качестве зависимости. Схему взаимодействия модулей можно проиллюстрировать следующий образом:
┌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┐ ┌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┐ ┆ server crate ┆ ┆ persist crate ┆ ┆┌───────────┐ ┌──────────┐┆ ┆┌──────────┐ ┆ ┆│ endpoints ├──>│ services ├────>│ lib.rs │ ┆ ┆└───────────┘ └──────────┘┆ ┆└──────────┘ ┆ └╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┘ └╌╌╌╌╌╌╌╌╌╌╌╌╌╌╌┘
Добавим всё необходимое в server/Cargo.toml:
[package]
name = "server"
version = "0.1.0"
edition = "2024"
[dependencies]
persist = { path = "../persist" }
thiserror = { workspace = true }
async-trait = { workspace = true }
tokio = { workspace = true }
axum = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
sqlx = { workspace = true }
[dev-dependencies]
bigdecimal = { workspace = true }
axum-test = { workspace = true }
testcontainers = { workspace = true }
testcontainers-modules = { workspace = true }
В крэйте server у нас следующие файлы с кодом:
service.rs— модуль с бизнес-логикой, которая построена вокруг вызовов функциональности из крэйтаpersistendpoints.rs— модуль, содержащий функции обработчики эндпоинтов, которые вызывают функциональность, определённую в модулеservice.rslib.rs— содержит в себе непосредственно создание axum сервераmain.rs— содержит функциюmain, которая запускает функцию создания сервера изlib.rs
Файл server/src/service.rs:
use std::sync::Arc;
use persist::{Account, Storage};
use crate::endpoints::NewAcc;
#[derive(Debug, thiserror::Error)]
pub enum AccountServiceError {
#[error("Database error: (0)")]
StorageError(#[from] sqlx::Error),
}
// Интерфейс для работы с бизнес логикой
#[async_trait::async_trait]
pub trait AccountService {
async fn get_all_accounts(&self) -> Result<Vec<Account>, AccountServiceError>;
async fn create_new_account(&self, new_acc: NewAcc) -> Result<Account, String>;
}
pub struct AccountServiceImpl {
storage: Arc<dyn Storage + Send + Sync>,
}
impl AccountServiceImpl {
pub fn new(storage: Arc<dyn Storage + Send + Sync>) -> AccountServiceImpl {
AccountServiceImpl { storage }
}
}
#[async_trait::async_trait]
impl AccountService for AccountServiceImpl {
async fn get_all_accounts(&self) -> Result<Vec<Account>, AccountServiceError> {
self.storage.fetch_accounts().await
.map_err(AccountServiceError::from)
}
async fn create_new_account(&self, new_acc: NewAcc) -> Result<Account, String> {
self.storage.create_accounts(&new_acc.owner_name, new_acc.init_balance).await
.map_err(|e|e.to_string())
}
}Обратите внимание, что структура AccountServiceImpl инкапсулирует хранилище посредством Arc<dyn Storage + Send + Sync>. Это позволит нам иметь возможность заинжектить в AccountServiceImpl как реальное хранилище — StorageImpl, так и какую-то заглушку для тестов. Ограничения Send и Sync необходимы, так как методы трэйта асинхронны.
Теперь файл, в котором создаётся Axum сервер — server/src/lib.rs. Обратите внимание, что объект нашей бизнес-логики — AccountServiceImpl мы храним в объекте состояния, причём также не напрямую, а посредством Arc<dyn AccountService + Send + Sync>.
use std::sync::Arc;
use axum::{Router, routing::{get, post}};
use persist::StorageImpl;
use crate::service::{AccountService, AccountServiceImpl};
pub mod service;
pub mod endpoints;
pub struct AppState {
pub account_service: Arc<dyn AccountService + Send + Sync>,
}
pub async fn run_server() {
let storage = StorageImpl::from_connection_url(
"postgres://postgres:1111@localhost/mydb"
).await.unwrap();
let account_service = AccountServiceImpl::new(Arc::new(storage));
let app = build_app(Arc::new(account_service));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
pub fn build_app(account_service: Arc<dyn AccountService + Send + Sync>) -> Router {
let state = AppState { account_service };
let app = Router::new()
.route("/accounts", get(endpoints::list_accounts))
.route("/accounts", post(endpoints::create_new_account))
.with_state(Arc::new(state));
app
}И теперь сами эндпоинты — server/src/endpoints.rs. С ними всё просто: они лишь вызывают соответствующие методы из сервиса бизнес-логики и перепаковывают результат в HTTP ответ.
use std::sync::Arc;
use axum::{Json, extract::State, http::StatusCode};
use serde::{Deserialize, Serialize};
use sqlx::types::BigDecimal;
use persist::Account;
use crate::AppState;
#[derive(Serialize, Deserialize)]
pub struct NewAcc {
pub owner_name: String,
pub init_balance: BigDecimal,
}
pub async fn list_accounts(
State(state): State<Arc<AppState>>
) -> Result<Json<Vec<Account>>, (StatusCode, String)> {
match state.account_service.get_all_accounts().await {
Ok(accounts) => Ok(Json(accounts)),
Err(e) => Err((StatusCode::INTERNAL_SERVER_ERROR, e.to_string())),
}
}
pub async fn create_new_account(
State(state): State<Arc<AppState>>, Json(acc): Json<NewAcc>
) -> Result<(StatusCode, Json<Account>), (StatusCode, String)> {
match state.account_service.create_new_account(acc).await {
Ok(account) => Ok((StatusCode::CREATED, Json(account))),
Err(e) => Err((StatusCode::INTERNAL_SERVER_ERROR, e.to_string())),
}
}Как видите, эндпоинты просто достают AccountService из состояния и вызывают его методы.
И напоследок — server/src/main.rs. В главной функции мы просто вызываем функциональность из lib.rs.
#[tokio::main]
async fn main() {
server::run_server().await
}Также напишем интеграционный тест для эндпоинтов server/tests/endpoints_tests.rs. Он будет посредством вызова эндпоинтов сначала создавать новый аккаунт, а затем проверять его наличие в хранилище.
use std::sync::Arc;
use axum::http::StatusCode;
use bigdecimal::{BigDecimal, FromPrimitive};
use persist::{Account, StorageImpl};
use server::{build_app, endpoints::NewAcc, service::AccountServiceImpl};
use sqlx::{migrate::Migrator, postgres::{PgConnectOptions, PgPoolOptions}};
use testcontainers::runners::AsyncRunner;
use axum_test::TestServer;
#[tokio::test]
async fn test_account_endpoints() {
let container = testcontainers_modules::postgres::Postgres::default()
.with_password("1111")
.start().await.unwrap();
let connection_options = PgConnectOptions::new()
.host(&container.get_host().await.unwrap().to_string())
.port(container.get_host_port_ipv4(5432).await.unwrap())
.database("postgres")
.username("postgres")
.password("1111");
let pool = PgPoolOptions::new()
.connect_with(connection_options).await.unwrap();
Migrator::new(std::path::Path::new("../migrations")).await.unwrap()
.run(&pool).await.unwrap();
let storage = StorageImpl::new(pool);
let account_service = AccountServiceImpl::new(Arc::new(storage));
let app = build_app(Arc::new(account_service));
let sut = TestServer::new(app).unwrap();
// Тестовый аккаунт
let new_acc = NewAcc {
owner_name: "John Doe".to_string(),
init_balance: BigDecimal::from_f64(1000.0).unwrap()
};
// Проверяем создание аккаунта
let create_acc_resp = sut.post("/accounts")
.json(&new_acc)
.await;
create_acc_resp.assert_status(StatusCode::CREATED);
let created_acc = create_acc_resp.json::<Account>();
assert_eq!(created_acc.owner_name, new_acc.owner_name);
assert_eq!(created_acc.balance, new_acc.init_balance);
// Проверяем получение всех аккаунтов
let list_accs_resp = sut.get("/accounts").await;
list_accs_resp.assert_status_ok();
let fetched_accs = list_accs_resp.json::<Vec<Account>>();
assert_eq!(fetched_accs.len(), 1);
assert_eq!(fetched_accs[0].id, created_acc.id);
assert_eq!(fetched_accs[0].owner_name, created_acc.owner_name);
assert_eq!(fetched_accs[0].balance, created_acc.balance);
}Миграции
Файлы для миграции структуры БД скопируйте из главы Версионирование структуры БД и поместите в каталог migrations.
Запуск
Теперь можете прогнать тесты:
cargo test
Или запустить сервер:
cargo run
и вызвать эндпоинты, чтобы убедиться в том, что они работают (не забудьте убедиться, что сервер СУБД запущен).
Создать аккаунт:
curl -i -X POST \
-H "Content-Type: application/json" \
-d '{"owner_name": "John Doe", "init_balance": 1000.0}' \
http://localhost:8080/accounts
Получить все аккаунты:
curl -i http://localhost:8080/accounts
Вот и всё: мы разобрались, каким образом на Axum и SQLx можно писать бекенды с классической слоёной архитектурой, где присутствуют слой данных, слой бизнес-логики и слой представления.
Документирование API
Для бэкенд приложений с REST API хороший практикой считается предоставлять эндпоинт, который возвращает описание доступных эндпоинтов в формате OpenAPI.
Open API описание позволяет не только понять, какие эндпоинты предоставляет бэкенд приложение, но и автоматически сгенерировать клиент для работы с этими эндпоинтами при помощи таких инструментов, как Insomnia и Postman.
В этой главе мы познакомимся с библиотекой Utoipa, которая предоставляет макросы для автоматической генерации Open API описания эндпоинтов.
Структура OpenAPI
Сначала подключим Utoipa в Cagro.toml.
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"]}
axum = "0.8"
utoipa = { version = "5", features = ["axum_extras"] }
utoipa-axum = { version = "0.2" }
Теперь рассмотрим главный тип, отвечающий за представление OpenAPI схемы — структуру utoipa::openapi::OpenApi.
pub struct OpenApi {
pub openapi: OpenApiVersion, // Версия OpenAPI спецификации
pub info: Info, // Общая информация об API: версия, лицензия, автор
pub servers: Option<Vec<Server>>,
pub paths: Paths, // Описания эндпоинтов
pub components: Option<Components>,
pub security: Option<Vec<SecurityRequirement>>, // детали аутентификации
pub tags: Option<Vec<Tag>>,
pub external_docs: Option<ExternalDocs>,
pub schema: String,
pub extensions: Option<Extensions>,
}Именно объект OpenApi используется для того, чтобы составить Open API схему эндпоинтов, а после отдать её в виде JSON документа.
Обычно объект OpenApi генерируется из описания эндпоинтов, однако чтобы лучше понять его устройство, давай создадим объект OpenApi вручную.
use utoipa::openapi::{
Content, HttpMethod, Info, License, OpenApiBuilder,
PathItem, Paths, Response, path::Operation
};
fn main() {
let open_api = OpenApiBuilder::new()
.info(
Info::builder()
.license(Some(License::new("GPL 2")))
.title("This is my API")
.version("1.0")
)
.paths(
Paths::builder()
.path("/hello",
PathItem::builder()
.summary(Some("My Hello endpoint"))
.operation(HttpMethod::Get,
Operation::builder()
.response("200",
Response::builder()
.description("'Hello' string")
.content("text/plain", Content::builder().build()))
.build()
)
.build()
)
)
.build();
println!("{}", open_api.to_pretty_json().unwrap());
}Вывод программы:
{
"openapi": "3.1.0",
"info": {
"title": "This is my API",
"license": { "name": "GPL 2" },
"version": "1.0"
},
"paths": {
"/hello": {
"summary": "My Hello endpoint",
"get": {
"responses": {
"200": { "description": "'Hello' string", "content": { "text/plain": {} } }
}
}
}
}
}
Как видите, структура OpenApi является ничем иным, как просто Rust представлением Open API спецификации.
Для получения JSON документа из объекта OpenApi используются методы to_json или to_pretty_json: первый возвращает JSON документ одной строкой, а второй предоставляет JSON отформатированным для удобного чтения человеком.
Генерация схемы
Теперь, когда мы познакомились со структурой OpenApi, давайте разберёмся, как её автоматически генерировать из функций-обработчиков.
Для того чтобы Utoipa могла сгенерировать Open API описание из функции-обработчика запросов, эту функцию необходимо пометить аннотацией path, при этом указав HTTP метод, URL путь, варианты ответа и т.д.
Для примера давайте перепишем наш традиционный Axum Hello пример, добавив к серверу эндпоинт, который отдаёт Open API схему.
use axum::routing::get;
use utoipa::OpenApi;
use utoipa_axum::{router::OpenApiRouter, routes};
#[derive(OpenApi)]
#[openapi(info(description = "My Api description", license(name = "GPL 2")))]
struct MyApiDoc;
// Эта аннотация используется и для генерации OpenAPI документации эндпоинта,
// и для создания Axum роутера, что позволяет не повторять одни и те же настройки.
#[utoipa::path(
get, // Эндпоинт вызывается для HTTP GET метода
path = "/hello", // URL путь эндпоинат
responses( // Возможные варианты ответа от эндпоинта
(status = 200, description = "'Hello' response", body = &'static str)
),
summary = "A hello endpoint", // Текстовое описание эндпоинта
)]
async fn hello() -> &'static str {
"Hello"
}
#[tokio::main]
async fn main() {
// Создаём Open API роутер, который содержит и информацию о роутинге,
// и Open API описание эндпоинтов
let open_api = OpenApiRouter::with_openapi(MyApiDoc::openapi())
.nest("/api", // создаём эндпоинты из utoipa аннотации
OpenApiRouter::new() // и помещаем их под путь /api/
.routes(routes!(hello))
);
// Получаем отдельно Axum роутер и OpenAPI описание эндпоинтов
let (router, api) = open_api.split_for_parts();
// К роутеру, сгенерированному из OpenAPI роутера, добавляем
// эндпоинт, отдающий JSON Open API схему эндпоинтов
let app = router
.route("/api-doc", get(async move || { api.to_pretty_json().unwrap() }));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}Теперь, если мы запустим сервер и перейдём на http://localhost:8080/api-doc, то должны получить примерно следующий JSON документ:
{
"openapi": "3.1.0",
"info": {
"title": "test_axum",
"description": "My Api description",
"license": { "name": "GPL 2" },
"version": "0.1.0"
},
"paths": {
"/api/hello": {
"get": {
"summary": "A hello endpoint",
"operationId": "hello",
"responses": {
"200": {
"description": "'Hello' response",
"content": { "text/plain": { "schema": { "type": "string" } } }
}
}
}
}
},
"components": {}
}
Как видите, мы используем аннотацию path и для создания Open API описания эндпоинта, и для регистрации эндпоинта в Axum роутере: HTTP метод и URL путь берутся из path аннотации.
let open_api = OpenApiRouter::with_openapi(MyApiDoc::openapi())
.nest("/api",
OpenApiRouter::new()
.routes(routes!(hello)) // мы не указываем путь и HTTP метод явно
);Так было сделано, чтобы не дублировать конфигурацию отдельно в аннотации path, и отдельно в роутере.
Более сложный эндпоинт
Рассмотрим теперь более сложный эндпоинт, который принимает аргументы пути, квери-аргументы, а также имеет несколько вариантов формата ответа.
use std::collections::HashMap;
use axum::{extract::{Path, Query}, http::StatusCode, routing::get};
use utoipa::OpenApi;
use utoipa_axum::{router::OpenApiRouter, routes};
#[derive(OpenApi)]
#[openapi(info(description = "My Api description", license(name = "GPL 2")))]
struct MyApiDoc;
#[utoipa::path(
get,
path = "/greet/{name}",
params(
("greeting" = Option<String>, Query, description = "Greeting str, default: 'Hello'"),
),
responses(
(status = 200, description = "Greet response", body = String),
(status = 400, description = "Wrong name error", body = String)
),
summary = "A greet endpoint",
)]
async fn greet(
Path(name): Path<String>,
Query(map): Query<HashMap<String, String>>
) -> (StatusCode, String) {
// Имя не должно быть короче двух символов.
if name.len() < 2 {
return (StatusCode::BAD_REQUEST, "Wrong name".to_string());
}
let greeting = map.get("greeting")
.map(|s| s.as_str())
.unwrap_or("Hello");
(StatusCode::OK, format!("{greeting}, {name}!"))
}
#[tokio::main]
async fn main() {
let open_api = OpenApiRouter::with_openapi(MyApiDoc::openapi())
.nest("/api", OpenApiRouter::new().routes(routes!(greet)));
let (router, api) = open_api.split_for_parts();
let app = router
.route("/api-doc", get(async move || { api.to_pretty_json().unwrap() }));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}Open API описание для этого эндпоинта (http://localhost:8080/api-doc) выглядит так:
{
"openapi": "3.1.0",
"info": {
"title": "test_axum",
"description": "My Api description",
"license": { "name": "GPL 2" },
"version": "0.1.0"
},
"paths": {
"/api/greet/{name}": {
"get": {
"summary": "A greet endpoint",
"operationId": "greet",
"parameters": [
{
"name": "greeting",
"in": "query",
"description": "Greeting str, default: 'Hello'",
"required": false,
"schema": { "type": "string" }
},
{
"name": "name",
"in": "path",
"required": true,
"schema": { "type": "string" }
}
],
"responses": {
"200": {
"description": "Greet response",
"content": { "text/plain": { "schema": { "type": "string" } } }
},
"400": {
"description": "Wrong name error",
"content": { "text/plain": { "schema": { "type": "string" } } }
}
}
}
}
},
"components": {}
}
Больше примеров использования аннотации path можно найти в официальной документации: https://docs.rs/utoipa/latest/utoipa/attr.path.html.
Swagger UI и аналоги
Очень часто в паре с Open API описанием эндпоинтов бэкенд-приложения предоставляют и web-инструмент для вызова и тестирования этих эндпоинтов. Экосистема Utoipa предоставляет крэйты для интеграции со следующими web-инструментами:
Принцип работы с ними очень простой:
- Мы подключаем соответствующую библиотеку.
- Генерируем Open API описание эндпоинтов при помощи Utoipa.
- Крэйт Utoipa SwaggerUI (или Redoc/RapiDoc/Scalar) предоставляет специальный сервис (Tower сервис), который мы просто подключаем в роутер.
- При переходе на URL, по которому SwaggerUI (или другой инструмент) эндпоинт зарегистрирован в роутере, подгружается веб страница со SwaggerUI, которая по Open API описанию создаёт клиент, позволяющий делать вызовы API прямо с веб страницы.
Для начала нам нужно подключить соответствующие крэйты:
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"]}
axum = "0.8"
utoipa = { version = "5", features = ["axum_extras"] }
utoipa-axum = { version = "0.2" }
utoipa-swagger-ui = { version = "9", features = ["axum"] }
utoipa-redoc = { version = "6", features = ["axum"] }
utoipa-rapidoc = { version = "6", features = ["axum"] }
utoipa-scalar = { version = "0.3", features = ["axum"] }
Теперь мы можем добавить SwaggerUI, Redoc, RapiDoc и Scalar в роутере. Вы, скорее всего, будете пользоваться только одним из них, но в учебных целях мы подключим все.
use std::collections::HashMap;
use axum::{extract::{Path, Query}, http::StatusCode};
use utoipa::OpenApi;
use utoipa_axum::{router::OpenApiRouter, routes};
use utoipa_rapidoc::RapiDoc;
use utoipa_redoc::{Redoc, Servable};
use utoipa_scalar::{Scalar, Servable as ScalarServable};
use utoipa_swagger_ui::SwaggerUi;
#[derive(OpenApi)]
#[openapi(info(description = "My Api description", license(name = "GPL 2")))]
struct MyApiDoc;
#[utoipa::path(
get,
path = "/greet/{name}",
params(
("greeting" = Option<String>, Query, description = "Greeting str, default: 'Hello'"),
),
responses(
(status = 200, description = "Greet response", body = String),
(status = 400, description = "Wrong name error", body = String)
),
summary = "A greet endpoint",
)]
async fn greet(
Path(name): Path<String>,
Query(map): Query<HashMap<String, String>>
) -> (StatusCode, String) {
if name.len() < 2 {
return (StatusCode::BAD_REQUEST, "Wrong name".to_string());
}
let greeting = map.get("greeting")
.map(|s| s.as_str())
.unwrap_or("Hello");
(StatusCode::OK, format!("{greeting}, {name}!"))
}
#[tokio::main]
async fn main() {
let open_api = OpenApiRouter::with_openapi(MyApiDoc::openapi())
.nest("/api", OpenApiRouter::new().routes(routes!(greet)));
let (router, api) = open_api.split_for_parts();
let app = router
.merge(SwaggerUi::new("/swagger-ui").url("/api-docs/openapi.json", api.clone()))
.merge(Redoc::with_url("/redoc", api.clone()))
.merge(RapiDoc::new("/api-docs/openapi.json").path("/rapidoc"))
.merge(Scalar::with_url("/scalar", api));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}Теперь мы можем запустить сервер и открыть:
- SwaggerUI: http://localhost:8080/swagger-ui/
- Redoc: http://localhost:8080/redoc
- RapiDoc: http://localhost:8080/rapidoc
- Scalar: http://localhost:8080/scalar
Аутентификация
Если для вызова эндпоинта необходимо передать некий аутентификационный токен (через HTTP заголовок, квери параметр или cookie), то это также должно быть отражено в Open API описании эндпоинтов. Во-первых, потому что эта информация необходима пользователям API, а во-вторых, потому что Swagger UI и другие подобные инструменты иначе не смогут корректно построить клиент для эндпоинтов.
Давайте рассмотрим пример, когда эндпоинты ожидают передачу токена через HTTP заголовок с именем “x-key”. В рамках примера нам не важен механизм получения этого токена. Также для простоты мы не будем валидировать токен, а будем просто считать, что все токены валидны.
use axum::{extract::{FromRequestParts}, http::StatusCode};
use utoipa::{Modify, OpenApi, openapi::security::{ApiKey, ApiKeyValue, SecurityScheme}};
use utoipa_axum::{router::OpenApiRouter, routes};
use utoipa_rapidoc::RapiDoc;
use utoipa_redoc::{Redoc, Servable};
use utoipa_scalar::{Scalar, Servable as ScalarServable};
use utoipa_swagger_ui::SwaggerUi;
// Имя HTTP заголовка для передачи токена
const APIKEY_HEADER: &str = "x-key";
// Тип, который мы будем использовать для добавления информации
// об аутентификации в документ OpenAPI
struct MySecurityAddon;
// Модифицируем OpenAPI документ путём добавления компонента - SecurityScheme,
// который указывает, какой токен необходим для аутентификации и как он передаётся.
impl Modify for MySecurityAddon {
fn modify(&self, openapi: &mut utoipa::openapi::OpenApi) {
if let Some(components) = openapi.components.as_mut() {
components.add_security_scheme(
"apikey_auth",
SecurityScheme::ApiKey(ApiKey::Header(ApiKeyValue::new(APIKEY_HEADER))),
)
}
}
}
#[derive(OpenApi)]
#[openapi(
info(description = "My Api description", license(name = "GPL 2")),
modifiers(&MySecurityAddon), // Добавляем наш SecurityAddon
)]
struct MyApiDoc;
#[utoipa::path(
get,
path = "/hello",
responses((status = 200, description = "'Hello' response", body = &'static str)),
summary = "A hello endpoint",
security( ("apikey_auth" = []) )
)]
async fn hello(_session: Authenticated) -> &'static str {
"Hello"
}
// Обычный Axum экстрактор, который для любого запроса, у которого есть HTTP заголовок
// x-key, возвращает объект Authenticated, сигнализирующий что клиент - авторизован
struct Authenticated;
impl<S: Send + Sync> FromRequestParts<S> for Authenticated {
type Rejection = StatusCode;
async fn from_request_parts(
parts: &mut axum::http::request::Parts,
_state: &S,
) -> Result<Self, Self::Rejection> {
if let Some(_session_id) = parts.headers.get(APIKEY_HEADER) {
Ok(Authenticated)
} else {
Err(StatusCode::UNAUTHORIZED)
}
}
}
#[tokio::main]
async fn main() {
let open_api = OpenApiRouter::with_openapi(MyApiDoc::openapi())
.nest("/api", OpenApiRouter::new().routes(routes!(hello)));
let (router, api) = open_api.split_for_parts();
let app = router
.merge(SwaggerUi::new("/swagger-ui").url("/api-docs/openapi.json", api.clone()))
.merge(Redoc::with_url("/redoc", api.clone()))
.merge(RapiDoc::new("/api-docs/openapi.json").path("/rapidoc"))
.merge(Scalar::with_url("/scalar", api));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}Если мы запустим сервер и запросим Open API описание эндпоинтов (http://localhost:8080/api-docs/openapi.json), то увидим, что в документе появился компонент, описывающий нашу аутентификацию.
{
"openapi":"3.1.0",
"info":{
"title":"test_axum",
"description":"My Api description",
"license":{ "name":"GPL 2" },
"version":"0.1.0"
},
"paths":{
"/api/hello":{
"get":{
"summary":"A hello endpoint",
"operationId":"hello",
"responses":{
"200":{
"description":"'Hello' response",
"content":{ "text/plain":{ "schema":{ "type":"string" } } }
}
},
"security":[ { "apikey_auth":[] } ]
}
}
},
"components":{
"securitySchemes":{ "apikey_auth":{ "type":"apiKey", "in":"header", "name":"x-key" }}
}
}
Если мы запустим Swagger UI (http://localhost:8080/swagger-ui/), то увидим, что в нём появилась кнопка “Authenticate”, которая позволит ввести “x-key”, после чего мы сможем использовать эндпоинты, требующие аутентификацию.
Prometheus метрики
Последняя важная тема, которую мы рассмотрим в рамках изучения бэкендов — метрики.
В этой главе мы узнаем, как собирать и предоставлять Prometheus метрики, работа с которыми обычно выглядит так:

Принцип следующий:
- Сервисы, с которых нужно собирать метрики, должны иметь эндпоинт (для простоты мы будем считать, что его путь —
/metrics, но его путь может быть любым), который выдаёт метрики в формате prometheus метрик. - Prometheus сервис раз в определённое время вызывает эндпоинт, чтобы получить значение метрик и сохранить их. Этот процесс называют скрапингом (scraping — соскабливание).
- Далее метрики из Prometheus сервиса можно запрашивать в агрегированном виде. Например, совместно с Prometheus часто используют систему Grafana — сервис с веб-интерфейсом, который отображает значения метрик в виде графиков и диаграмм.
- Также Prometheus сервер можно настроить таким образом, чтобы при достижении определёнными метриками пороговых значений он генерировал алёрты. При помощи сервиса AlertManager можно легко настроить интеграцию Prometheus алёртов с такими сервисами, как PagerDuty.
В этой главе мы не будем рассматривать установку и настройку Prometheus сервера, а лишь ограничимся созданием эндпоинта /metrics, который отдаёт метрики в том формате, который ожидает Prometheus сервер.
Крэйт metrics
Для работы с Prometheus метриками имеется библиотека prometheus, которая содержит:
- типы, представляющие все виды Prometheus метрик
- функциональность для форматирования значения метрик в формат, подходящий для скрапинга Prometheus сервером.
Однако работать с API библиотеки prometheus напрямую не очень удобно, поэтому обычно используют связку библиотек:
- metrics — фасад, предоставляющий удобные макросы для работы с метриками
- metrics-prometheus — реализация фасада, которая оборачивает крэйт prometheus
Note
Существует также другой крэйт-реализация фасада metrics для Prometheus — metrics-exporter-prometheus. Он имеет встроенный HTTP сервер, поэтому может оказаться более удобным для приложений, которые не экспортируют свой HTTP API. Но для наших примеров, в этой главе, мы будем использовать крэйт
metrics-prometheusтак как он проще, и имеет более очевидный API.
Для работы с метриками нам нужно будет добавить в Cargo.toml следующие зависимости:
[package]
name = "test_axum"
version = "0.1.0"
edition = "2024"
[dependencies]
tokio = { version = "1", features = ["full"]}
axum = "0.8"
metrics = "0.24"
metrics-prometheus = "0.11"
prometheus = "0.14"
Метрика Counter
Первая метрика, с которой мы разберёмся — Counter: числовой счётчик, который подразумевает либо увеличение своего значения, либо рестарт.
Для работы с метрикой Counter библиотека metrics предоставляет удобный макрос counter, который используется примерно следующим образом:
metrics::counter!("имя_метрики").increment(1);Этот вызов:
- создаёт Counter метрику с заданным именем, если она еще не была зарегистрирована, и инициализирует её нулём
- инкрементирует значение метрики
Рассмотрим простейший пример:
fn main() {
// Создаём глобальное хранилище метрик.
let recorder = metrics_prometheus::install();
// Объявляем, что если у нас будет метрика с именем first_counter, то
// её описанием должна быть строка "Some description"
metrics::describe_counter!("first_counter", "Some description");
// Создаём и инкрементируем Сounter метрику с именем first_counter
metrics::counter!("first_counter").increment(1);
// Увеличиваем my_counter на 2
metrics::counter!("first_counter").increment(2);
// Создаём и инкрементируем Сounter метрику с именем second_counter
metrics::counter!("second_counter").increment(1);
// Формируем такое текстовое представление значений метрик,
// которое ожидается Prometheus сервером
let report: String = prometheus::TextEncoder::new()
.encode_to_string(&recorder.registry().gather())
.unwrap();
println!("{report}");
}Эта программа напечатает:
# HELP first_counter Some description
# TYPE first_counter counter
first_counter 3
# HELP second_counter second_counter
# TYPE second_counter counter
second_counter 1
Именно такой текстовый формат использует Prometheus сервис, когда скрапит метрики с приложений путём вызова /metrics эндпоинта. Этот формат подразумевает, что для каждой метрики задано:
# HELP имя_метрики описание— текстовое описание метрики.# TYPE имя_метрики тип— тип метрики:counter/gauge/histogramимя_метрики значение— текущее значение метрики
Теперь давайте рассмотрим, как использовать метрики совместно с Axum сервером. Для примера, модифицируем наш пример Hello-сервера, добавив в него Counter метрику, которая инкрементируется при каждом вызове /hello.
use std::sync::Arc;
use axum::{Router, extract::State, routing::get};
use metrics_prometheus::Recorder;
struct AppState {
recorder: Recorder,
}
#[tokio::main]
async fn main() {
// Инициализируем объект для сбора метрик. Этот объект также используется для
// форматирования значений метрик, запрашиваемых Prometheus сервером.
let recorder = metrics_prometheus::install();
let state = AppState { recorder };
let app = Router::new()
.route("/hello", get(hello))
.route("/metrics", get(get_metrics))
.with_state(Arc::new(state));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
// Инкрементируем счётчик с именем hello_calls
metrics::counter!("hello_calls").increment(1);
"Hello!"
}
// Предполагается, что этот эндпоинт вызывается Prometheus скрапером.
async fn get_metrics(state: State<Arc<AppState>>) -> String {
let report: String = prometheus::TextEncoder::new()
.encode_to_string(&state.recorder.registry().gather())
.unwrap();
report
}Теперь если мы запустим сервер и сразу перейдём по адресу http://localhost:8080/metrics, то получим пустой ответ. Так происходит потому, что метрика hello_calls не была инициализирована никаким значением. Но если мы сначала перейдём на http://localhost:8080/hello, а потом снова на http://localhost:8080/metrics, то получим следующее:
# HELP hello_calls hello_calls
# TYPE hello_calls counter
hello_calls 1
Мы также можем сразу инициализировать метрику, например нулём. Сделать это можно при помощи метода absolute:
let recorder = metrics_prometheus::install();
// Сразу после создания объекта prometheus метрик, инициализируем метрику нулём
metrics::counter!("hello_calls").absolute(0);Измерения
К значениям метрик можно добавлять произвольные атрибуты в формате ключ=>значение, которые называются измерениями (dimension).
metrics::counter!("имя_метрики", "измерение1" => "знач1", "измерение2" => "знач2")
.increment(1);Обычно измерения используются для задания дополнительной информации к значению метрики.
В качестве примера сделаем метрику, подсчитывающую количество запросов к каждому эндпоинту. Для этого мы создадим метрику number_of_calls с измерением "path", которое будет хранить URL путь запроса. И для удобства мы поместим подсчёт этой метрики в отдельный мидлваре.
use std::sync::Arc;
use axum::{Router, extract::{Request, State}, middleware::{Next, from_fn}};
use axum::{response::Response, routing::get};
use metrics_prometheus::Recorder;
struct AppState {
recorder: Recorder,
}
#[tokio::main]
async fn main() {
let recorder = metrics_prometheus::install();
let state = AppState { recorder };
let app = Router::new()
.merge(
// Помещаем во вложенный роутеры те эндпоинты, для которых
// должно вызываться наше мидлваре с метрикой.
Router::new()
.route("/endpoint-1", get(endpoint_1))
.route("/endpoint-2", get(endpoint_2))
.layer(from_fn(metrics_middleware))
)
.route("/metrics", get(get_metrics))
.with_state(Arc::new(state));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn metrics_middleware(request: Request, next: Next) -> Response {
let path = request.uri().path().to_string();
metrics::counter!("number_of_calls", "path" => path).increment(1);
let response = next.run(request).await;
response
}
async fn endpoint_1() -> &'static str {
"Endpoint 1"
}
async fn endpoint_2() -> &'static str {
"Endpoint 2"
}
async fn get_metrics(state: State<Arc<AppState>>) -> String {
let report = prometheus::TextEncoder::new()
.encode_to_string(&state.recorder.registry().gather())
.unwrap();
report
}Запустим сервер, сделаем по запросу к эндпоинтам http://localhost:8080/endpoint-1 и http://localhost:8080/endpoint-2, после чего запросим метрики с http://localhost:8080/metrics.
Мы должны увидеть следующее:
# HELP number_of_calls number_of_calls
# TYPE number_of_calls counter
number_of_calls{path="/endpoint-1"} 1
number_of_calls{path="/endpoint-2"} 1
Gauge
Метрика Gauge, в отличие от Counter, подразумевает не только увеличение, но и уменьшение значения. Эта метрика часто используется для того, чтобы отображать текущее состояние некой величины. Например: количество сообщений, находящихся в обработке, нагрузка на процессор, количество свободного места на диске, количество активных соединений к БД и т.д.
Рассмотрим простой пример, который демонстрирует возможности Gauge:
fn main() {
let recorder = metrics_prometheus::install();
// Установка абсолютного значения для метрики
metrics::gauge!("my_gauge").set(5);
// Инкрементирование значения
metrics::gauge!("my_gauge").increment(3);
// Декрементирование
metrics::gauge!("my_gauge").decrement(1);
let report = prometheus::TextEncoder::new()
.encode_to_string(&recorder.registry().gather())
.unwrap();
println!("{report}");
}Вывод программы:
# HELP my_gauge my_gauge
# TYPE my_gauge gauge
my_gauge 7
Histogram
Метрика Histogram используется для подсчёта частотного распределения значений.
Гистограмма содержит внутри себя несколько счётчиков, каждый из которых связан с неким пороговым значением. Эти счётчики называются бакетами (bucket). По умолчанию Histogram содержит бакеты с такими пороговыми значениями:
0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5, 10, ∞.
Когда мы записываем в метрику очередное значение, то для всех бакетов происходит проверка: является ли значение меньшим, чем пороговое значение бакета. Если является, то счётчик для этого бакета инкрементируется.
Таким образом, мы получаем, сколько записанных значений оказалось меньше, чем 0.005, сколько оказалось меньше, чем 0.01 и т.д.

Метрика Histogram особенно удобна для того, чтобы следить за временем ответа для эндпоинтов, временем выполнения запросов в базу данных и т.д.
Для примера напишем мидлваре, который использует Histogram для замера времени обработки запроса. Для того чтобы имитировать разное время выполнения обработчика запроса, мы будем использовать библиотеку rand, поэтому добавьте rand = "0.9" в Cargo.toml.
use std::{sync::Arc, time::Duration};
use axum::{Router, extract::{Request, State}, middleware::{Next, from_fn}};
use axum::{response::Response, routing::get};
use metrics_prometheus::Recorder;
use tokio::time::Instant;
struct AppState {
recorder: Recorder,
}
#[tokio::main]
async fn main() {
let recorder = metrics_prometheus::install();
let state = AppState { recorder };
let app = Router::new()
.merge(
Router::new()
.route("/endpoint-1", get(endpoint_1))
.layer(from_fn(metrics_middleware))
)
.route("/metrics", get(get_metrics))
.with_state(Arc::new(state));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn metrics_middleware(request: Request, next: Next) -> Response {
let path = request.uri().path().to_string();
let start = Instant::now(); // Начинаем замер времени выполнения
let response = next.run(request).await;
let time_in_seconds = start.elapsed().as_secs_f64(); // Фиксируем время выполнения
metrics::histogram!("call_duration", "path" => path).record(time_in_seconds);
response
}
async fn endpoint_1() -> &'static str {
// Имитируем задержку продолжительностью от 0 до 1000 миллисекунд
tokio::time::sleep(Duration::from_millis(rand::random_range(0..1000))).await;
"Endpoint 1"
}
async fn get_metrics(state: State<Arc<AppState>>) -> String {
let report = prometheus::TextEncoder::new()
.encode_to_string(&state.recorder.registry().gather())
.unwrap();
report
}Итак, запустим наш сервер.
Сперва перейдём в браузере на http://localhost:8080/endpoint-1 и 9 раз обновим страницу, чтобы в сумме иметь 10 обращений к эндпоинту.
Далее перейдём на http://localhost:8080/metrics, чтобы получить метрики:
# HELP call_duration call_duration
# TYPE call_duration histogram
call_duration_bucket{path="/endpoint-1",le="0.005"} 0
call_duration_bucket{path="/endpoint-1",le="0.01"} 0
call_duration_bucket{path="/endpoint-1",le="0.025"} 1
call_duration_bucket{path="/endpoint-1",le="0.05"} 2
call_duration_bucket{path="/endpoint-1",le="0.1"} 3
call_duration_bucket{path="/endpoint-1",le="0.25"} 3
call_duration_bucket{path="/endpoint-1",le="0.5"} 7
call_duration_bucket{path="/endpoint-1",le="1"} 10
call_duration_bucket{path="/endpoint-1",le="2.5"} 10
call_duration_bucket{path="/endpoint-1",le="5"} 10
call_duration_bucket{path="/endpoint-1",le="10"} 10
call_duration_bucket{path="/endpoint-1",le="+Inf"} 10
call_duration_sum{path="/endpoint-1"} 4.274135234
call_duration_count{path="/endpoint-1"} 10
Нетрудно заметить, что так как вызов sleep в нашем эндпоинте засыпает на интервал от 0 до 1000 миллисекунд (то есть не дольше 1 секунды), а мы замеряем время выполнения обработчика в секундах, то все бакеты в гистограмме после бакета с пороговым значением 1.0 не имеют смысла: мы всё равно не засыпаем дольше, чем на секунду.
Для подобных ситуаций, когда мы заранее знаем, в каких пределах будут находиться значения, имеет смысл вручную задать желаемый набор бакетов. Это можно сделать при помощи типа HistogramOpts:
let custom_buckets = vec![0.1, 0.25, 0.5, 1.0, 5.0];
let opts = HistogramOpts::new("имя_гистограммы", "Описание метрики")
.buckets(custom_buckets);Рассмотрим простой пример, где мы конфигурируем Histogram метрику, указывая, что нас интересуют бакеты для пороговых значений: 0.1, 0.25, 0.5, 0.9 и 1.0.
use std::time::Duration;
use prometheus::{Histogram, HistogramOpts};
fn main() {
let recorder = metrics_prometheus::install();
// Интересующие нас пороговые значения для бакетов
let custom_buckets = vec![0.1, 0.25, 0.5, 0.9, 1.0];
// Задаём конфигурацию (описание и бакеты) для Histogram с именем call_duration
let opts = HistogramOpts::new("call_duration", "My description")
.buckets(custom_buckets);
// Регистрируем конфигурацию для Histogram с именем call_duration
let histogram = Histogram::with_opts(opts).unwrap();
recorder.register_metric(histogram);
for _ in 0 .. 10 {
// Эмулируем ожидание в интервале от 0 до 1000 миллисекунд
let latency = Duration::from_millis(rand::random_range(0..1000));
// Записываем в метрику очередное значение
metrics::histogram!("call_duration").record(latency.as_secs_f64());
}
let report = prometheus::TextEncoder::new()
.encode_to_string(&recorder.registry().gather())
.unwrap();
println!("{report}");
}Вывод программы:
# HELP call_duration My description
# TYPE call_duration histogram
call_duration_bucket{le="0.1"} 2
call_duration_bucket{le="0.25"} 5
call_duration_bucket{le="0.5"} 6
call_duration_bucket{le="0.9"} 6
call_duration_bucket{le="1"} 10
call_duration_bucket{le="+Inf"} 10
call_duration_sum 4.932
call_duration_count 10
Как видите, в этой Histogram уже нет “бессмысленных” бакетов.
Метрики процесса
Часто бывает полезно иметь не только метрики, заполняемые непосредственно приложением, но и такие метрики процесса (программы), как потребление CPU и оперативной памяти, количество запущенных потоков, количество открытых файловых дескрипторов и т.д.
Экосистема Rust предлагает множество крэйтов, которые помогают получить метрики хоста и процесса. Мы будем использовать библиотеку metrics-process, которая умеет сразу и получать метрики процесса, и записывать их в соответствующие Prometheus метрики.
Для начала добавим metrics-process в Cargo.toml:
metrics-process = "2"
Библиотека предоставляет тип metrics_process::Collector, который позволяет записать метрики процесса просто путём вызова:
// Получить объект коллектора
let collector = Collector::default();
// Инициализировать описание метрик текстовками по умолчанию (опционально)
collector.describe();
// Произвести сбор метрик процесса и "втолкнуть" значения в Prometheus метрики
collector.collect();Модифицируем наш самый первый пример из этой главы, добавив сбор метрик процесса:
use std::sync::Arc;
use axum::{Router, extract::State, routing::get};
use metrics_process::Collector;
use metrics_prometheus::Recorder;
struct AppState {
recorder: Recorder,
}
#[tokio::main]
async fn main() {
let recorder = metrics_prometheus::install();
let state = AppState { recorder };
let app = Router::new()
.route("/hello", get(hello))
.route("/metrics", get(get_metrics))
.with_state(Arc::new(state));
let listener = tokio::net::TcpListener::bind("0.0.0.0:8080").await.unwrap();
axum::serve(listener, app).await.unwrap();
}
async fn hello() -> &'static str {
metrics::counter!("hello_calls").increment(1);
"Hello!"
}
async fn get_metrics(state: State<Arc<AppState>>) -> String {
// Обновляем метрики процесса
let collector = Collector::default();
collector.describe();
collector.collect();
let report: String = prometheus::TextEncoder::new()
.encode_to_string(&state.recorder.registry().gather())
.unwrap();
report
}Запустим сервер и перейдём на http://localhost:8080/metrics. Мы должны увидеть что-то похожее на:
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 0
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1048576
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 16
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 6397952
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1767575577
# HELP process_threads Number of OS threads in the process.
# TYPE process_threads gauge
process_threads 17
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 1116295168
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 0
Кросс сборка
Разные платформы
Когда вы собираете программу на Rust, то по умолчанию она компилируется в машинный код для той платформы, на которой вы работаете, и линкуется с той стандартной библиотекой C, которая у вас установлена. Поэтому если вы работаете на Windows или MacOS, то у вас не получится просто собрать бинарный исполняемый файл, скопировать его на Linux сервер и там его запустить.
Также если вы работаете под Linux, но версия GLIBC на вашей системе старше, чем версия GLIBC на целевом Linux сервере, то скорее всего, исполняемый бинарный файл, собранный под вашу систему, также не запустится на целевом Linux сервере.
Tip
GLIBC — стандартная библиотека C, используемая по умолчанию в большинстве дистрибутивов Linux.
Собрать программу на Rust под другую платформу можно двумя путями:
- Произвести сборку на таком же окружении, как и целевая платформа. Это может быть как отдельная физическая машина, так и Docker контейнер или виртуальная машина, где запущена такое же окружение, как и на целевой платформе.
- Произвести кросс-компиляцию под другую целевую платформу.
Со сборкой на другой машине, или в Docker контейнере всё более-менее понятно. А с кросс-компиляцией мы будем разбираться дальше в этой главе.
Проблемы кросс-компиляции
Для того чтобы собрать Rust программу под другую платформу, надо сделать две вещи:
- скомпилировать исходный код в объектный файл (машинный код в определённом формате) для целевой платформы
- слинковать объектные файлы со стандартной библиотекой C целевой платформы
Если скомпилировать код в объектные файлы для другой платформы легко (надо просто указать соответствующую опцию компиляции), то для линковки со стандартной библиотекой C под другую платформу всё сложнее, ведь вам понадобятся:
- линкер, умеющий собирать исполняемые файлы целевой платформы
- библиотека C от целевой платформы
Например, собрать программу для Windows x86_64 из под Linux Ubunu относительно нетрудно, но только потому, что в репозитории пакетов Ubuntu имеется нужный пакет с библиотекой C и линкером, который умеет собирать исполняемые файлы для Windows:
# Установить MinGW C++ тулчейн для Windows, который содержит линкер и бибилотеку C
sudo apt install gcc-mingw-w64-x86-64
# Установить Rust тулчейн для кросс компиляции под Windows x86_64
rustup target add x86_64-pc-windows-gnu
# Собрать приложение для Windows x86_64 с библиотекой C из MinGW w64
cargo build --release --target x86_64-pc-windows-gnu
А вот собрать программу из под Windows для Linux уже сложнее: скомпилировать объектные файлы также легко, а добыть линкер и GLIBC нужной версии — проблема.
Zig-build
В этом месте надо сделать отступление и сказать пару слов о таком языке программирования, как Zig. Это компилируемый язык, который имеет такие же правила кросс-платформенной сборки: ему необходимы линкер и стандартная библиотека C под целевую платформу. Однако особенность Zig заключается в том, что Zig SDK содержит в себе и линкеры, и стандартные библиотеки C сразу под все основные платформы. Таким образом, для кросс-сборки программы на Zig нет необходимости дополнительно что-то устанавливать, ведь Zig SDK уже содержит всё необходимое.
Такая особенность Zig не могла остаться незамеченной членами Rust сообщества, которые вскоре создали утилиту zigbuild. Эта утилита использует линкер и библиотеку C из Zig SDK для кросс-сборки программ на Rust.
Для начала установим Zig SDK:
- Скачайте последнюю стабильную версию Zig SDK c официального сайта:
https://ziglang.org/download/. Результатом скачивания должен быть tar.xz или zip архив с именем наподобииzig-x86_64-linux-0.14.1.tar.xz. - Распакуйте архив в удобное для вас место.
- Добавьте путь к корневой папке с Zig SDK (папка в которой находится исполняемый файл
zig) в системный путь. На Unix-подобных системах — это переменнаяPATH, на Windows —Path.
Теперь установите утилиту zigbuild. Для этого выполните команду:
cargo install --locked cargo-zigbuild
Warning
Если у вас Windows и вы используете MinGW, а не Visual C++, то при сборке zigbuild у вас могут возникнуть проблемы с линковкой с системными библиотеками Windows. В этой ситуации рекомендуется просто установить Visual C++, или воспользоваться Docker образом с zigbuild.
Сборка для Windows
Предположим, что вы работаете на Linux или MacOS, и хотите собрать программу для Windows при помощи zigbuild. Вам нужно:
1) Установить Rust тулчейн для Windows
rustup target add x86_64-pc-windows-gnu
2) Собрать программу, используя zigbuild:
cargo zigbuild --release --target x86_64-pc-windows-gnu
После этого должна появиться директория target/x86_64-pc-windows-gnu/release, в которой будет содержаться исполняемый exe файл.
Сборка для Linux
Теперь рассмотрим пример, как собрать программу для Linux из-под Windows.
1) Установите тулчейн для Linux c GLIBC:
rustup target add x86_64-unknown-linux-gnu
2) Далее соберите программу:
cargo zigbuild --release --target x86_64-unknown-linux-gnu
Учтите, что GLIBC имеет разные версии. Версия GLIBC, с которой вы линкуете программу, не должна быть старше, чем версия GLIBC на системе, где вы планируете запускать вашу программу.
Чтобы узнать версию GLIBC на Linux системе, вы можете воспользоваться командой ldd:
$ ldd --version
ldd (Ubuntu GLIBC 2.39-0ubuntu8.6) 2.39
Copyright (C) 2024 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
Zig 0.12, 0.13, 014 и 0.15 по умолчанию линкуют с GLIBC версией 2.28.
Для того чтобы при сборке задать конкретную версию GLIBC, укажите её после точки в имени таргета. Например, чтобы слинковать с GLIBC 3.34, используйте команду сборки:
cargo zigbuild --release --target x86_64-unknown-linux-gnu.3.34
Tip
Также следует заметить, что пользователи Windows могут воспользоваться WSL для сборки программ под Linux.
zigbuild Docker
Вы также можете воспользоваться готовым Docker образом zigbuild, который уже содержит Rust, Zig SDK и zigbuild.
Например, следующая команда собирает программу для Windows:
docker run --rm -it -v $(pwd):/io -w /io ghcr.io/rust-cross/cargo-zigbuild \
cargo zigbuild --release --target x86_64-pc-windows-gnu
MUSL
Иногда вы не знаете, какая версия GLIBC будет использоваться на системе, где планируется запуск вашей программы. В некоторых дистрибутивах (например, Alpine Linux) её нет вовсе.
Для таких ситуаций существует альтернативная стандартная библиотека C — MUSL. В отличие от GLIBC, с которой программы линкуются динамически, MUSL предназначена для статической линковки. Т.е. при сборке программы машинный код библиотеки MUSL помещается непосредственно в бинарный файл программы. Таким образом отпадает необходимость во внешней динамической библиотеке C.
За сборку под Linux с MUSL отвечает отдельный Rust тулчейн, который следует установить командой:
rustup target add x86_64-unknown-linux-musl
Для сборки программы с MUSL вы можете как использовать zibguild (Zig SDK содержит MUSL), так и просто установить пакет MUSL на свою систему, если такой имеется.
Например, если вы используете Ubuntu Linux, то вам будет необходимо установить пакеты musl-tools и musl-dev:
sudo apt install musl-tools musl-dev
после чего вы сможете собрать свою программу под Linux, но слинкованную с MUSL:
cargo build --release --target x86_64-unknown-linux-musl
Но удобнее использовать zigbuild: он работает на любой системе и не требует установки дополнительных пакетов.
cargo zigbuild --target x86_64-unknown-linux-musl --release
Вы можете задаться вопросом: “Если MUSL так удобен, почему бы не использовать его для сборок под Linux всегда?”.
Если ваше приложение не использует никаких внешних динамических библиотек, то MUSL является отличным выбором по умолчанию.
Однако если ваше приложение использует динамическую библиотеку, которая слинкована с GLIBC, то сборка вашего приложения с MUSL в лучшем случае просто не даст ожидаемого результата: приложение всё равно будет нуждаться в GLIBC, только уже для внешней библиотеки.
Например, на момент написания этого текста (Rust 1.92) в экосистеме Rust отсутствовал драйвер для СУБД Oracle, который был бы полностью написан на Rust. Имеющийся крэйт oracle является просто обёрткой над библиотекой, написанной на C и слинкованной с GLIBC. Причём код библиотеки закрыт, что исключает возможность самостоятельно скомпилировать её, и статически слинковать с программой на Rust. Поэтому если ваше приложение должно работать с СУБД Oracle, вам придётся использовать GLIBC.